Author: Denis Avetisyan
A new framework leverages the power of graph neural networks to prioritize augmenting paths in the Ford-Fulkerson algorithm, accelerating max-flow computation and boosting performance in applications like image segmentation.
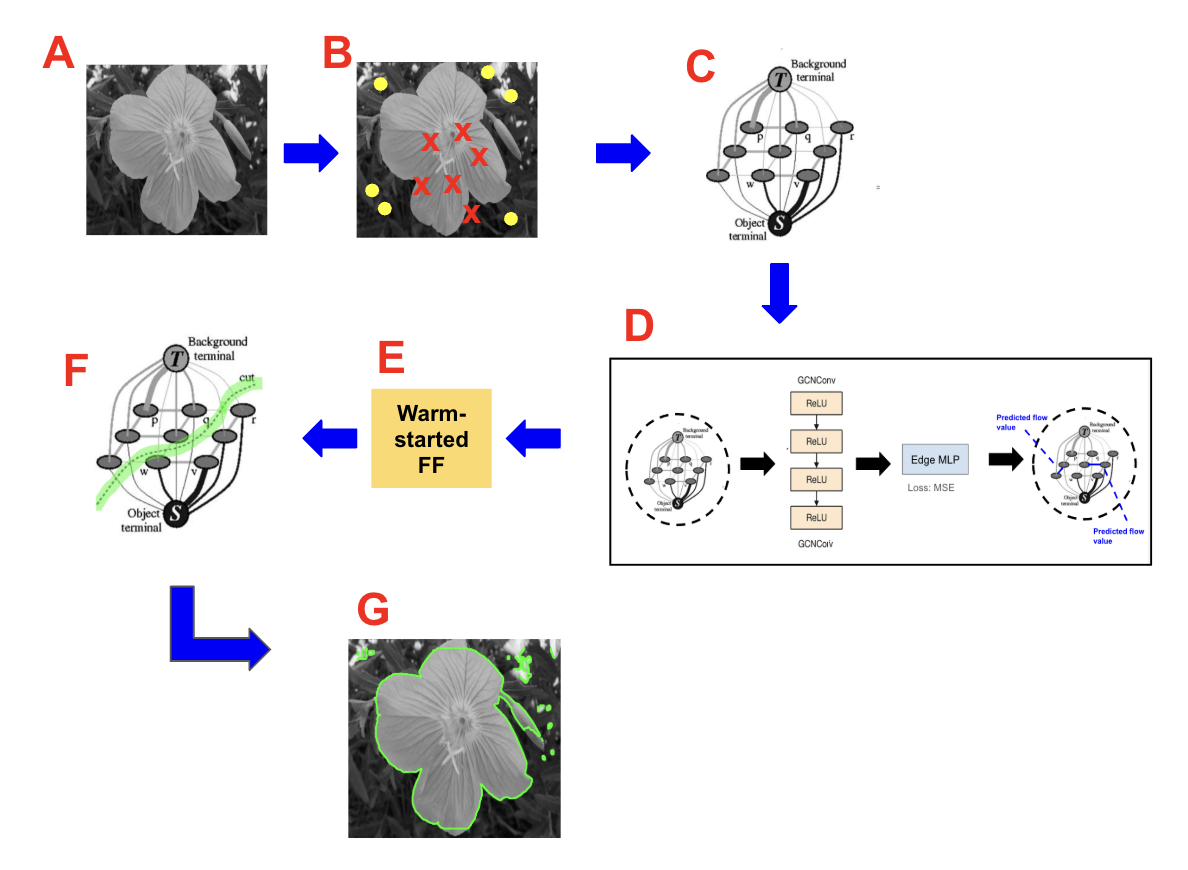
This work introduces a learning-augmented approach to edge prioritization in max-flow algorithms, improving both speed and PAC-learnability.
Despite the established optimality of the Ford-Fulkerson algorithm for max-flow problems, its practical efficiency can be hampered by the need for exhaustive search-this paper, ‘Graph Neural Network-Informed Predictive Flows for Faster Ford-Fulkerson and PAC-Learnability’, introduces a learning-augmented framework that accelerates computation by leveraging Graph Neural Networks (GNNs) to predict edge importance and guide augmenting path selection. The core innovation lies in a Message Passing GNN that learns to prioritize edges likely to belong to high-capacity cuts, enabling a modified Edmonds-Karp search with reduced augmentations while preserving optimality. By demonstrating both practical speedups in max-flow and image segmentation tasks, and providing theoretical connections to PAC-learnability, does this approach pave the way for a new generation of learning-guided combinatorial optimization algorithms?
The Elegant Foundation of Network Flow
The principle of flow networks offers a powerful lens through which to analyze and optimize a surprisingly broad spectrum of real-world challenges. Consider logistical operations – efficiently moving goods from origin to destination – where network capacity represents road or rail limitations and ‘flow’ signifies the volume of transported materials. Similarly, data communication networks rely on maximizing the flow of information packets, constrained by bandwidth and network congestion. Even seemingly disparate problems, such as scheduling tasks in a project or distributing resources in an economy, can be elegantly recast as flow network problems, all seeking to identify the highest possible throughput given inherent limitations. This unifying framework allows researchers to apply sophisticated algorithms, originally developed for network analysis, to address optimization issues across diverse fields, highlighting the versatility and fundamental importance of flow network theory.
While foundational to network flow analysis, classical algorithms such as Ford-Fulkerson encounter significant computational hurdles when applied to complex networks. The algorithm’s iterative process of identifying augmenting paths – routes through the network with remaining capacity – becomes increasingly expensive as network density and capacity values grow. In scenarios with irrational capacities or poorly structured graphs, Ford-Fulkerson may even fail to converge on a solution within a reasonable timeframe. This inefficiency stems from the potential for the algorithm to select suboptimal paths during each iteration, leading to a large number of augmentations required to reach the maximum flow. Consequently, researchers have focused on developing more sophisticated algorithms, like Edmonds-Karp, which guarantee polynomial time complexity and offer improved performance on large-scale networks, addressing the limitations inherent in the original Ford-Fulkerson method.
The core of maximum flow algorithms often hinges on the iterative discovery of augmenting paths – routes through the network with remaining capacity that can accommodate additional flow. While conceptually straightforward, this repeated search for paths becomes increasingly burdensome in dense graphs, where the number of potential routes explodes. Each iteration demands examining numerous edges to identify a viable path, leading to computational complexity that scales poorly with network size. This inefficiency stems from the algorithm’s need to constantly reassess the residual graph, updating capacities and searching for new paths until no further augmentation is possible. Consequently, for large and densely connected networks, the time required to determine the maximum flow can become prohibitively extensive, motivating the development of more sophisticated algorithms capable of bypassing this bottleneck.

Graph Neural Networks: A Natural Fit for Flow Prediction
Flow networks are fundamentally graph-structured data, consisting of nodes representing entities and edges defining capacities between them. Graph Neural Networks (GNNs) are specifically designed to operate on graph data, directly utilizing this inherent structure without requiring transformations like adjacency matrices used in traditional machine learning. This allows GNNs to model complex relationships between network components – such as node connectivity and edge capacities – in a way that respects the network’s topology. The ability to directly process graph data enables efficient feature extraction and representation learning tailored to the specific characteristics of flow networks, facilitating improved performance in tasks like flow prediction and optimization compared to methods requiring data reshaping or ignoring structural information.
Message Passing Graph Neural Networks (MPGNNs) operate by iteratively aggregating and transforming information along the edges of a graph. Each node’s representation is updated based on feature sets of its immediate neighbors, weighted by edge attributes. This process, repeated for multiple ‘message passing’ steps, allows the network to capture dependencies beyond direct connections, effectively modeling complex, multi-hop relationships within the flow network. The resulting node and edge embeddings can then be used to predict flow rates, congestion probabilities, or other relevant flow patterns, leveraging the learned structural and feature-based relationships. The capacity of MPGNNs to learn these relationships stems from their ability to approximate the Weisfeiler-Lehman graph isomorphism test, enabling differentiation between structurally distinct network configurations and their associated flow behaviors.
Pre-processing a flow network with a Graph Neural Network (GNN) enables a ‘warm-start’ of the Ford-Fulkerson algorithm by providing informed initial estimates for edge capacities. Rather than beginning the maximum flow search with arbitrary or zero-valued edge assessments, the GNN predicts likely flow values on each edge based on network topology and node characteristics. These predictions are then used to initialize the residual graph, effectively biasing the Ford-Fulkerson algorithm towards promising augmenting paths. This reduces the number of iterations required to converge on the optimal solution, particularly in large and complex networks, as the algorithm starts closer to the optimal flow assignment and requires fewer path discoveries to refine the solution.
Graph Convolutional Networks (GCNs) represent a specialized approach within Graph Neural Networks designed for predicting edge flows in network optimization problems. GCNs operate by aggregating feature information from neighboring nodes to estimate the flow expected on each edge, effectively learning a function that maps node features and edge attributes to predicted flow values. This prediction serves as a heuristic to guide traditional maximum flow algorithms, such as Ford-Fulkerson, by prioritizing edges with high predicted flow during the search for augmenting paths. By pre-selecting promising edges, the GCN reduces the search space and accelerates convergence towards an optimal solution, particularly in large and complex networks where exhaustive search is computationally prohibitive. The predicted edge flows are typically generated through a series of convolutional layers operating on the graph structure, utilizing σ activation functions and weighted aggregations to capture non-linear relationships.

Rigorous Validation Through PAC Learning
Validating the efficacy of Graph Neural Network (GNN)-assisted flow computation requires a rigorous framework to determine how effectively the GNN learns to select relevant edges within a graph. This assessment necessitates quantifying the learnability of the edge selection function itself, moving beyond simply evaluating the resulting flow computation. A suitable framework must provide bounds on the amount of training data needed to achieve a desired level of accuracy in predicting optimal edge orderings, allowing for a statistically sound determination of whether the GNN is generalizing effectively or overfitting to the training data. Without such a framework, it is difficult to ascertain whether improvements in flow computation are due to the GNN’s inherent learning capability or merely to chance or specific characteristics of the training dataset.
PAC (Probably Approximately Correct) Learning provides a formal framework for analyzing the sample complexity of learning algorithms. Specifically, it establishes bounds on the amount of training data required to ensure that a learned function will generalize to unseen data with a specified level of accuracy and confidence. Sample complexity, in this context, refers to the number of examples needed to learn a target function to within an error tolerance ϵ with a probability of at least 1 - δ. A lower sample complexity indicates greater efficiency in learning, as it requires less data to achieve the desired accuracy and confidence levels. This is crucial for evaluating the feasibility and scalability of machine learning models, particularly when dealing with large datasets or computationally expensive function evaluations.
The learnability of edge importance probabilities, as predicted by the Graph Neural Network, is formally quantifiable through the principles of Probably Approximately Correct (PAC) learning. This analysis establishes a sample complexity bound of O(|E|dlog²(|E|d/ϵ) + log(1/δ)/ϵ), where |E| represents the number of edges in the graph, d is the maximum degree of any node, ϵ defines the desired accuracy, and δ represents the acceptable probability of error. This bound indicates the number of samples required to learn the edge selection function to a specified level of accuracy with high probability; a larger |E| or d increases the required sample size, while decreasing ϵ or increasing δ also necessitates more data for reliable learning.
Cayley Distance and Weighted Cayley Distance are utilized to evaluate the accuracy of predicted edge orderings against optimal solutions. Cayley Distance assesses the number of edge reversals needed to transform one ordering into another. The Weighted Cayley Distance, dW_C(σ, σ^) = min{∑j=1kw(ij): σ^= τik⋯τi1∘σ}, further refines this by considering edge weights w(ij) and represents the minimum cumulative weight of edges that need to be transposed to align the predicted ordering σ^ with the optimal ordering σ, where τik denotes the transposition of edges and .

Amplifying Network Optimization: A Systemic Impact
Graph Neural Networks offer a compelling acceleration to the Ford-Fulkerson algorithm, a cornerstone of network flow optimization, by strategically prioritizing the search for augmenting paths. Traditional implementations can become computationally expensive as network size increases, often requiring exploration of numerous unproductive paths. GNNs, however, learn to predict promising paths based on the network’s structure and current flow, effectively guiding the algorithm toward solutions more quickly. This intelligent path selection is particularly impactful in large networks where the search space expands exponentially, offering substantial reductions in runtime and improved scalability. By focusing computational effort on the most likely candidates, GNNs transform the Ford-Fulkerson algorithm from a potentially exhaustive search into a targeted and efficient process.
The computational speed gains achieved through Graph Neural Network-assisted optimization of the Ford-Fulkerson algorithm extend far beyond theoretical improvements, offering tangible benefits to a diverse range of practical applications. Efficient network routing, crucial for modern communication systems and data transmission, stands to be revolutionized by faster flow calculations. Similarly, logistics optimization – encompassing supply chain management, delivery route planning, and warehouse efficiency – can realize significant cost savings and improved responsiveness. Resource allocation, vital in fields like telecommunications, cloud computing, and even emergency response, becomes more dynamic and effective with the ability to quickly determine optimal distribution strategies. Ultimately, the acceleration of max-flow computations unlocks enhanced performance and scalability across numerous sectors reliant on network analysis and optimization.
The Edmonds-Karp algorithm, renowned for its efficiency in solving the maximum flow problem, experiences a notable performance boost when integrated with Graph Neural Networks (GNNs). While Edmonds-Karp systematically searches for the shortest augmenting path-a path with available capacity-using breadth-first search, GNNs provide an intelligent guide, prioritizing paths likely to yield significant flow increases. This GNN-guided approach doesn’t alter the algorithm’s fundamental guarantee of finding the optimal solution, but it drastically reduces the number of iterations required, especially in complex networks with numerous potential paths. By preemptively identifying promising routes, GNNs minimize the exploration of dead ends, accelerating the convergence of Edmonds-Karp and unlocking substantial computational savings for applications demanding real-time network optimization.
Despite the introduction of Graph Neural Networks to accelerate the search for augmenting paths, the fundamental guarantee of optimality in network flow problems remains firmly rooted in the Max-Flow Min-Cut Theorem. This theorem, a cornerstone of graph theory, dictates that the maximum amount of flow passing through a network is always equal to the minimum capacity of any cut separating the source and sink nodes. Consequently, even as GNNs intelligently guide the Ford-Fulkerson algorithm – or its more efficient implementation, the Edmonds-Karp algorithm – towards solutions, the resulting maximum flow is mathematically assured to be optimal, mirroring the outcome achievable through traditional methods but potentially reached with significantly reduced computational effort. The theorem, therefore, provides a crucial validation of the GNN-assisted approach, ensuring that performance gains do not come at the expense of solution accuracy, and allowing these techniques to be confidently deployed in critical applications.
The pursuit of efficient computation, as demonstrated in this work with the integration of Graph Neural Networks into the Ford-Fulkerson algorithm, echoes a fundamental tenet of system design: structure dictates behavior. By learning edge importance probabilities, the framework doesn’t merely speed up max-flow computation-it reshapes the way the algorithm explores the solution space. This aligns with John McCarthy’s observation: “It is often easier to recognize a solution than to invent one.” The GNN, in essence, recognizes patterns indicating promising paths, allowing the algorithm to prioritize exploration and, ultimately, converge more quickly-a testament to the power of informed structure.
The Road Ahead
The integration of learned priors into established algorithmic structures, as demonstrated by this work, reveals a predictable truth: optimization is not arrival, but merely the relocation of bottlenecks. Accelerating max-flow via Graph Neural Networks does not eliminate computational complexity; it reshapes it. The focus shifts from path discovery to the accuracy of the learned edge probabilities, introducing a new performance surface dependent on the quality and representativeness of the training data. This creates a dependency – an emergent property of the system – where algorithmic performance is now inextricably linked to the data manifold.
Future investigations must address the robustness of these learned heuristics. While performance gains are promising on curated datasets, the true test lies in generalization – how well do these GNN-informed augmentations perform on graphs exhibiting structural variations not present in the training set? A deeper exploration of the residual graph’s information content – what signals remain after the GNN’s prioritization – could reveal critical failure modes and guide the development of more resilient learning frameworks.
Ultimately, this line of inquiry suggests a broader principle: architecture is the system’s behavior over time, not a diagram on paper. The elegance of Ford-Fulkerson lies not in its simplicity, but in its guaranteed convergence. Augmenting it with learning introduces a delicate balance – a potential for speedup, yes, but also a new vector for instability. The challenge, then, is not simply to accelerate computation, but to understand the emergent dynamics of this hybrid algorithmic-learned system.
Original article: https://arxiv.org/pdf/2604.21175.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Gold Rate Forecast
- Infinity Nikki Candlelight Reverie Challenge and Rewards Guide
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Silver Rate Forecast
- Brent Oil Forecast
- 24 Jump Street in the works with Jonah Hill and Channing Tatum set to return
- KPop Demon Hunters Meets Avatar: The Last Airbender In Netflix’s 3-Part Fantasy Series
- EUR ZAR PREDICTION
2026-04-25 20:04