Author: Denis Avetisyan
New research reveals that artificial intelligence can now automatically link pseudonymous online accounts to real-world identities with alarming accuracy.
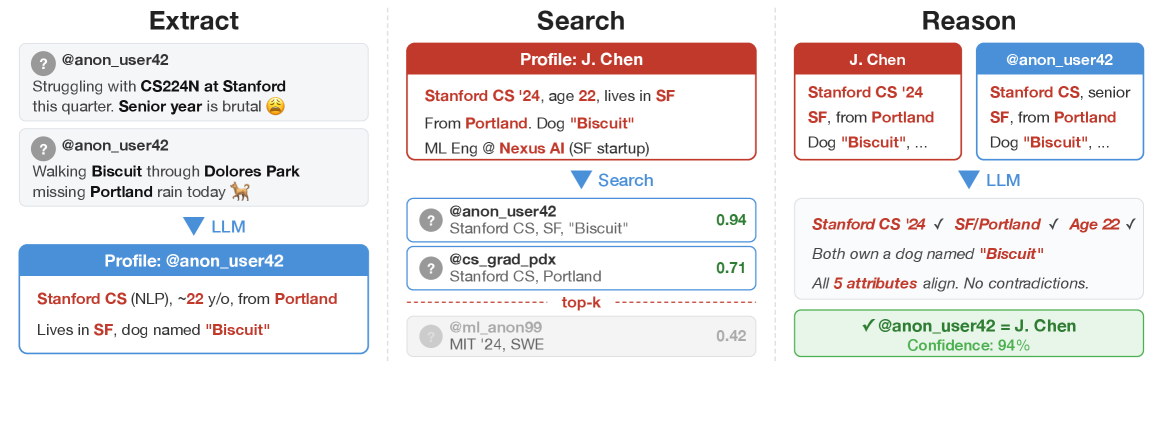
Large language models pose a significant threat to data privacy by enabling large-scale deanonymization of online activity.
Despite growing expectations of online anonymity, pseudonymous user profiles are increasingly vulnerable to re-identification. This vulnerability is demonstrated in ‘Large-scale online deanonymization with LLMs’, which reveals that large language models (LLMs) can automatically link seemingly anonymous online accounts to real-world identities at scale. By extracting identity-relevant features from unstructured text and leveraging semantic embeddings, the research achieves up to 68% recall at 90% precision across multiple datasets-substantially outperforming prior, non-LLM methods. Given these findings, can existing threat models adequately account for the deanonymization potential of readily available LLMs and the erosion of practical online obscurity?
The Inherent Fragility of Online Anonymity
Despite the implementation of various data privacy measures – such as encryption and pseudonymization – individuals are increasingly susceptible to deanonymization attacks. These attacks exploit the inherent limitations of anonymization techniques, revealing personal identities from datasets initially intended to be anonymous. Seemingly innocuous pieces of information, when combined with publicly available data or through sophisticated analytical methods, can uniquely identify individuals within a crowd. This isn’t a failure of intention, but a consequence of data’s interconnectedness and the growing power of data mining algorithms. Even datasets stripped of direct identifiers like names and addresses can be vulnerable if they contain quasi-identifiers – attributes like age, gender, location, and purchase history – which, when correlated, can lead to re-identification with alarming accuracy. The proliferation of data collection and sharing further exacerbates this threat, creating a complex landscape where maintaining true anonymity proves exceptionally challenging.
Established privacy protections, such as anonymization and pseudonymization, are increasingly challenged by advancements in data analysis and machine learning. Techniques once considered secure are now vulnerable to sophisticated attacks that correlate seemingly innocuous data points – browsing history, location data, even typing patterns – to uniquely identify individuals. This erosion of privacy isn’t due to a failure of intent, but a fundamental shift in the capabilities of data science. Adversaries are leveraging powerful algorithms to re-identify individuals within datasets previously thought to be shielded, exposing personal information and creating significant security risks. Consequently, a critical gap exists between the established methods of data protection and the evolving techniques used to circumvent them, demanding a re-evaluation of current strategies and the development of more robust, future-proof solutions.
Dissecting User Profiles with Large Language Models
LLM Extraction initiates the identification process by leveraging Large Language Models to analyze user-provided data, specifically profiles and posts. This analysis focuses on discerning ‘Micro-data’ – discrete pieces of information that, when aggregated, contribute to a unique identifier for each individual. The LLM is tasked with identifying and isolating these data points, which can include stated preferences, unique phrasing, specific affiliations, or consistently mentioned entities. The extracted Micro-data is not limited to explicitly provided personal information; it encompasses any discernible attribute that differentiates one user from another within the dataset. This initial extraction phase forms the basis for subsequent profile construction and matching algorithms.
The LLM-based Semantic Filter operates by assessing the informational content of extracted text segments. It employs natural language understanding to differentiate between statements that contribute to a unique individual profile and those consisting of common or non-identifying information. This is achieved through a scoring mechanism that prioritizes attributes related to specific interests, affiliations, or self-reported details, while down-weighting or removing generalized observations, greetings, or broadly applicable statements. The filter’s thresholds are calibrated to minimize false positives – the inclusion of non-distinguishing data – and ensure the retained micro-data points contribute meaningfully to individual identification accuracy.
The extracted micro-data serves as the primary input for constructing detailed individual profiles. These profiles aggregate the identified attributes – encompassing stated preferences, behavioral patterns, and unique identifiers – into a structured format. This structured data enables subsequent matching algorithms to operate effectively, facilitating the identification of individuals across different datasets or platforms. The robustness of these profiles is directly correlated to the accuracy and comprehensiveness of the initial micro-data extraction process, impacting the reliability of any downstream matching or analytical tasks. Profile construction prioritizes data normalization and standardization to ensure consistency and compatibility across diverse data sources.
A Rigorous Protocol for Assessing Identification Accuracy
Profile splitting is a methodology used in evaluation to generate distinct sets of query and candidate profiles. This process involves partitioning a unified dataset into two non-overlapping subsets: one serving as the source for query profiles and the other for candidate profiles. A crucial component of this splitting is the introduction of a ‘Temporal Gap’, wherein candidate profiles are derived from a period preceding the query profile generation period. This temporal separation simulates a realistic information retrieval scenario where the system must match a current query against previously existing data, preventing artificially inflated performance metrics resulting from direct overlap between query and candidate sets and providing a more robust assessment of the system’s ability to generalize to unseen data.
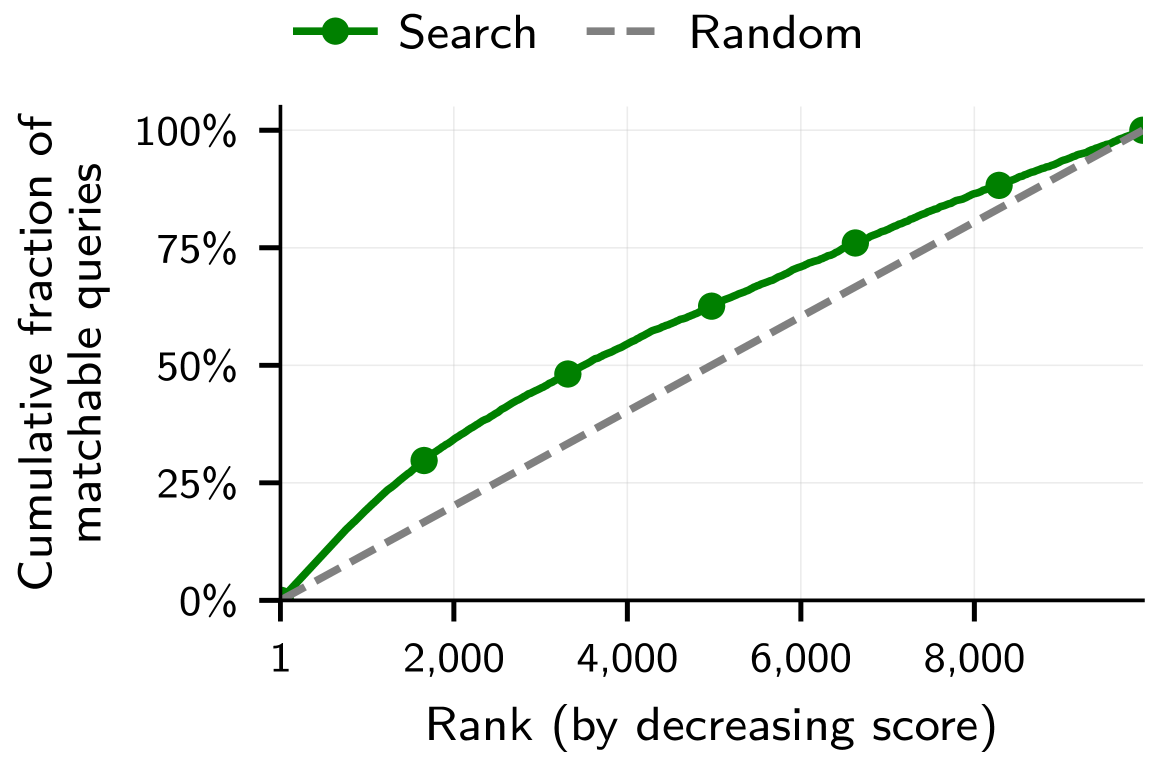
Initial candidate selection functions as a pre-filtering stage within the evaluation framework, reducing the computational burden of subsequent, more complex matching processes. This stage operates by identifying items from the overall candidate pool that exhibit broad similarities to the query based on readily available, coarse-grained attributes. By narrowing the candidate pool – often by several orders of magnitude – before calculating embedding similarities, the system substantially lowers processing requirements and enables scalable evaluation, particularly with large datasets. The criteria for broad similarity are designed for efficiency, prioritizing speed of comparison over nuanced feature matching.
The matching of queries to candidate entities is determined by calculating the similarity between their respective embeddings, a process leveraging vector space models to represent entities and queries numerically. To refine this matching, a ‘Rarity Weighting’ scheme is applied, increasing the importance of less frequent attributes during the similarity calculation. This weighting prioritizes distinctions based on uncommon characteristics, mitigating the impact of frequently occurring, and thus less discriminative, features. Consequently, the use of rarity weighting improves the precision of the matching process by emphasizing attributes that uniquely identify candidates, leading to more accurate results compared to unweighted embedding similarity.
Refining Matches Through LLM-Driven Reasoning
The Calibration Step utilizes Large Language Models (LLMs) to assess the quality of potential matches generated during the initial matching phase. This involves assigning a confidence score to each candidate match, reflecting the LLM’s certainty regarding its relevance. These scores are then used to rank the potential matches, prioritizing those with higher confidence. The ranking process incorporates established methodologies, such as the Bradley-Terry rating system – which estimates the relative skill of players based on pairwise comparisons – and Swiss-System Tournament algorithms, ensuring a robust and statistically sound ordering of matches based on LLM-derived confidence levels. This calibrated ranking provides a prioritized shortlist for subsequent evaluation.
The calibration step utilizes established ranking systems to assess the quality of potential matches beyond simple similarity scores. Bradley-Terry Rating, originally developed for pairwise comparison data, assigns a numerical value representing the relative strength of each candidate, allowing for probabilistic ranking. Complementing this, the Swiss-System Tournament methodology, commonly used in competitive events, iteratively pits candidates against each other, refining their rankings based on win/loss records. This approach avoids the limitations of absolute scoring and provides a more robust and nuanced evaluation of match quality, particularly when dealing with subjective or incomplete data, by focusing on relative performance within the candidate pool.
The Reasoning Step utilizes Large Language Models (LLMs) to determine the optimal match from a reduced set of candidates generated by prior filtering and calibration stages. This process involves a detailed assessment of extracted micro-data, which includes specific attributes and relationships identified within the data sources. The LLM analyzes this micro-data to evaluate the degree of correspondence between the query and each candidate, considering factors such as semantic similarity, contextual relevance, and data consistency. The model then assigns a probability score to each candidate, reflecting its likelihood of being the correct match, and selects the candidate with the highest score as the final result.
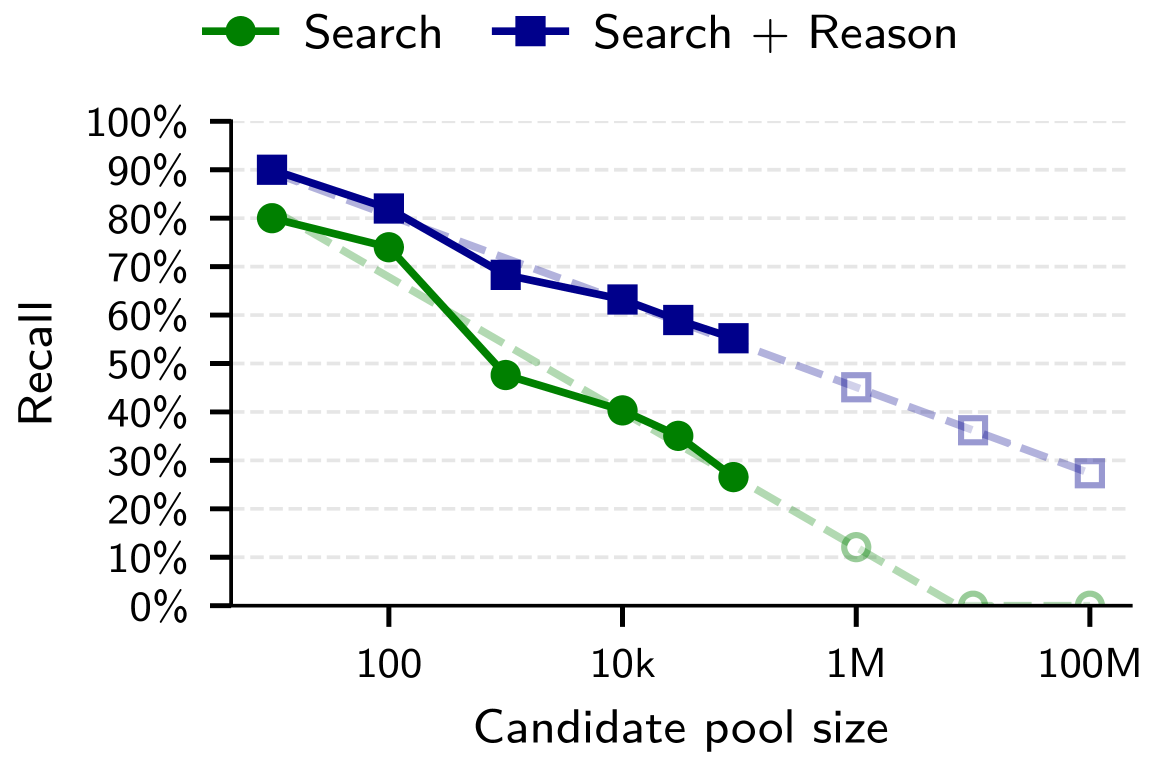
The Imminent Threat to Online Pseudonymity and Future Mitigation Strategies
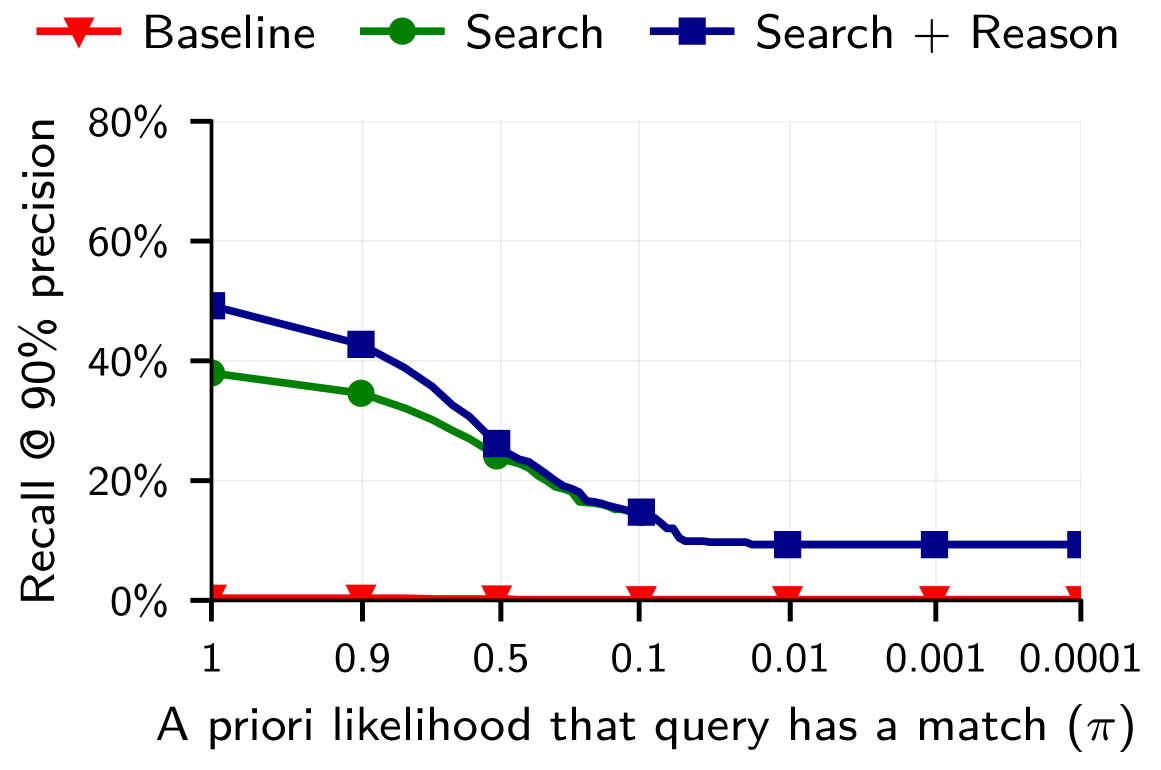
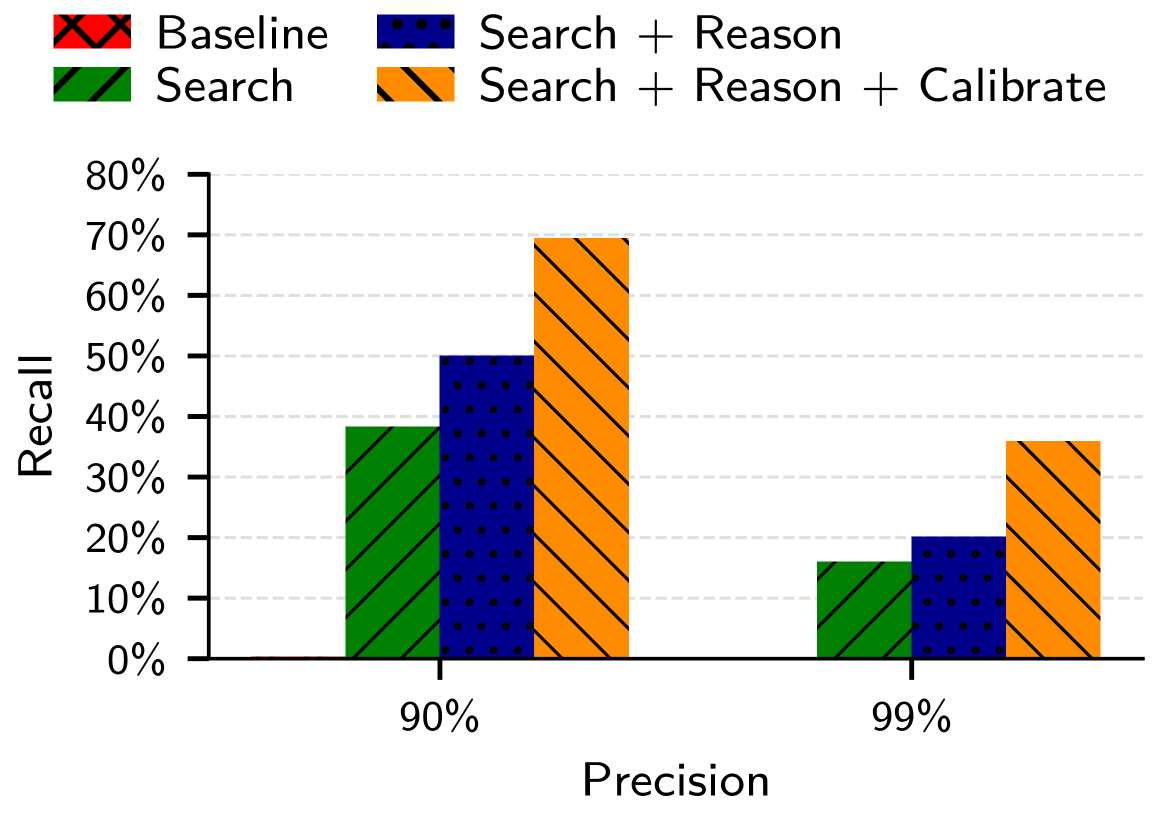
A rigorous evaluation of de-anonymization risk necessitates the use of quantifiable metrics, and this research employed both ‘Recall@Precision’ and false positive rate to precisely measure the success of linking pseudonymous accounts to real-world identities. Recall@Precision assesses the proportion of correctly identified matches within a set of high-confidence links, while the false positive rate indicates the frequency of incorrect matches, ensuring a balance between accurate identification and minimizing erroneous associations. By focusing on these metrics, the study moves beyond qualitative assessments, providing a concrete and reproducible framework for understanding the scale of de-anonymization vulnerabilities and benchmarking the effectiveness of future privacy defenses; this allows for a data-driven approach to mitigating the risks inherent in online pseudonymity.
Recent investigations reveal a substantial capacity for large language models to compromise online pseudonymity at scale. Specifically, these models demonstrate an ability to link seemingly anonymous accounts across different platforms, achieving up to 45.1% recall while maintaining 99% precision when connecting accounts on Hacker News to their corresponding LinkedIn profiles. This success rate indicates that, given a set of potential matches, the model correctly identifies linked accounts nearly half of the time, with a remarkably low rate of false positives. The findings underscore a critical vulnerability in current online privacy practices, suggesting that even limited information available on pseudonymous platforms can be leveraged to reveal real-world identities with concerning accuracy.
The study reveals a surprising capacity for large language models to identify individuals even when faced with extremely limited identifying information. Researchers found that, despite an expectation of only 9% recall – meaning success in only 9% of attempts – LLMs could still accurately link accounts when tasked with matching users against a pool of 10,000 potential candidates. This demonstrates that even seemingly insignificant patterns in online behavior, when analyzed by these models, can be sufficient for re-identification. The ability to succeed with such a low prior probability highlights a significant vulnerability in current pseudonymization techniques and underscores the potential for widespread de-anonymization, even in scenarios where individuals believe their online identities are well-concealed.
Analysis reveals a concerning capacity to link Reddit user identities even within seemingly disparate online communities. Specifically, the methodology achieves a 3.1% recall rate at 99% precision when identifying academic Reddit accounts, demonstrating a significant ability to correlate user activity across the platform. Further investigation shows that users participating in movie-related subreddits can be linked with 2.8% recall at 99% precision, highlighting the potential for cross-community profile construction. These results, while representing a relatively small percentage of overall users, indicate a demonstrable risk to pseudonymity on Reddit, as the methodology successfully identifies a meaningful number of accounts despite the lack of explicit identifying information and the broad scope of the platform.
The demonstrated capacity of large language models to link seemingly anonymous online accounts underscores a critical need for advancements in privacy-preserving technologies. Current pseudonymization techniques, while intended to shield user identities, prove increasingly vulnerable to sophisticated analytical tools capable of exploiting subtle patterns and correlations within online behavior. This research indicates that simply concealing direct identifiers is insufficient; future defenses must focus on techniques that actively disrupt the ability of LLMs to infer identity through contextual data. Areas ripe for exploration include differential privacy methods, homomorphic encryption for data analysis, and the development of robust adversarial training strategies to inoculate online platforms against deanonymization attacks. The ongoing arms race between privacy and identification necessitates a proactive and iterative approach to safeguard user data in an increasingly interconnected digital landscape.
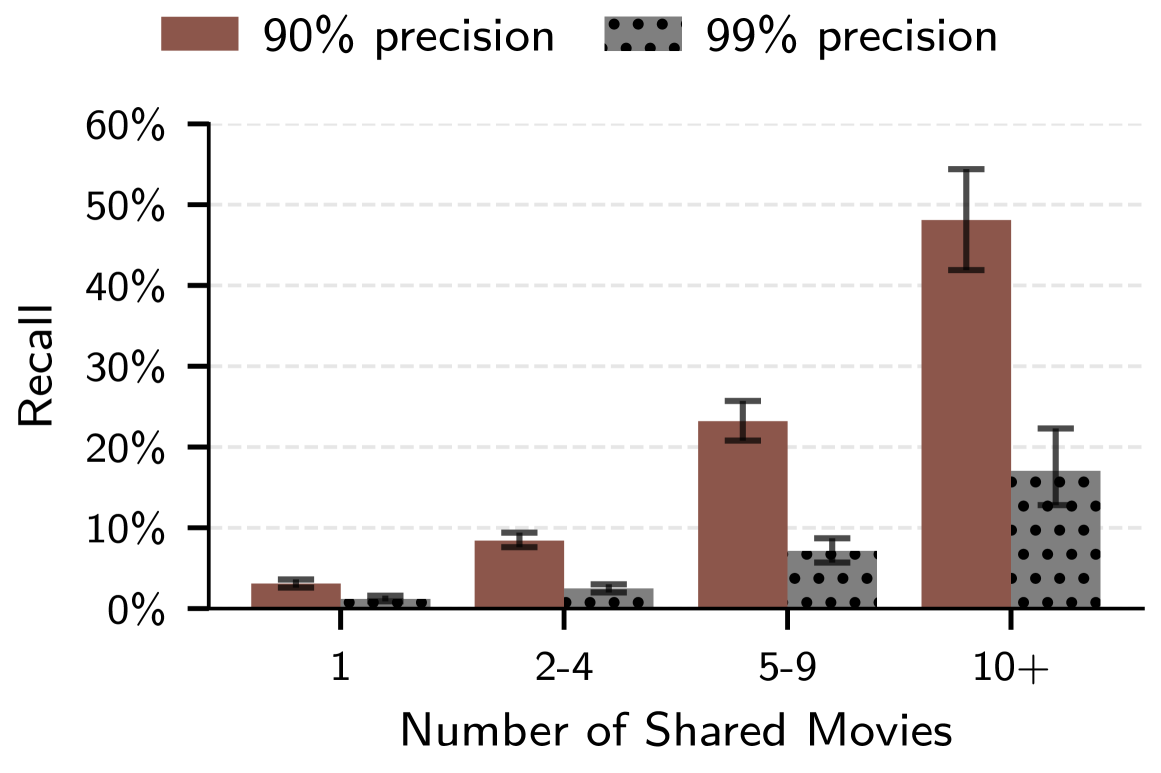
The research meticulously details how large language models dismantle the illusion of online anonymity, a consequence stemming from their capacity to extrapolate patterns and correlations within vast datasets. This echoes Ada Lovelace’s observation that “The Analytical Engine has no pretensions whatever to originate anything.” While the engine – or in this case, the LLM – doesn’t create new information, its power resides in its ability to combine and analyze existing data to reveal previously hidden connections. The study demonstrates this powerfully, showing how LLMs can reconstruct identities by correlating seemingly innocuous online behaviors – a chilling reminder that mathematical precision, applied to data, can breach even carefully constructed digital facades. The core concept of deanonymization hinges on this analytical capability, stripping away layers of abstraction to expose underlying truths.
What’s Next?
The demonstrated efficacy of LLM-driven deanonymization is not, strictly speaking, a discovery. Rather, it is the inevitable consequence of applying sufficiently powerful pattern-matching engines to inherently leaky data. The problem is not the algorithm, but the foundational assumption that pseudonymity offers genuine protection. Formal definitions of privacy – beyond the superficial masking of identifiers – remain conspicuously absent from most online systems. A mathematically sound framework for differential privacy, rigorously enforced, would be a proper starting point, yet such precision is rarely valued over expediency.
Future work must move beyond empirical demonstrations of vulnerability. The focus should shift to provable limits on deanonymization, establishing conditions under which pseudonymity can be guaranteed, even against adversarial LLMs. This necessitates a departure from purely data-driven approaches, toward formal verification and the construction of privacy-preserving algorithms with quantifiable security bounds. Simply increasing the volume of test data, or crafting more complex adversarial attacks, is merely rearranging the deck chairs.
Ultimately, the true challenge lies not in patching vulnerabilities, but in rethinking the very notion of online identity. A system built on inherently fragile assumptions, repeatedly exposed by increasingly sophisticated algorithms, is not a secure system. The pursuit of true privacy demands a level of mathematical rigor currently absent from the field, a commitment to formal definitions, and a willingness to abandon the illusion of security through obscurity.
Original article: https://arxiv.org/pdf/2602.16800.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Infinity Nikki Candlelight Reverie Challenge and Rewards Guide
- Silver Rate Forecast
- Brent Oil Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- EUR ZAR PREDICTION
- Dua Lipa and Callum Turner Had a Town Hall Wedding
2026-02-23 04:32