Author: Denis Avetisyan
A new approach aligns the strengths of multiple large language models to create more stable and accurate predictions in the volatile world of finance.
This paper introduces FinAnchor, a method for learning aligned multi-modal representations that improves performance on financial prediction tasks.
Extracting actionable insights from lengthy financial documents is hampered by sparse signals and the fluctuating performance of individual large language models. To address this, we introduce FinAnchor: Aligned Multi-Model Representations for Financial Prediction, a framework that leverages the complementary strengths of multiple LLMs without requiring model fine-tuning. FinAnchor achieves this by aligning heterogeneous representations into a shared embedding space via learned linear mappings, creating a robust unified representation for downstream tasks. Does this anchoring approach represent a viable path toward more stable and accurate financial forecasting?
The Illusion of Understanding: When LLMs Disagree
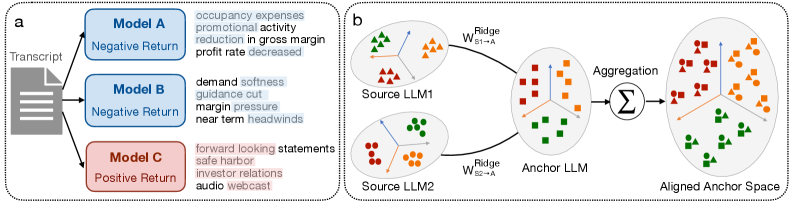
Modern financial forecasting increasingly depends on the analysis of a vast and varied landscape of textual information. Earnings calls, comprehensive financial reports, and often ambiguous policy statements all contribute to understanding market trends and predicting future performance. However, extracting meaningful insights requires processing this data with Large Language Models (LLMs), and a significant challenge arises from the inherent incompatibility between these models. Different LLMs, trained on disparate datasets and employing unique architectures, often interpret and represent the same textual information in fundamentally different ways. This lack of interoperability means that simply feeding data through multiple LLMs doesn’t automatically yield a more complete or accurate prediction; instead, it introduces complexities in integrating potentially conflicting interpretations and necessitates sophisticated methods for harmonizing these diverse perspectives.
Successfully integrating the analyses of multiple Large Language Models for financial forecasting presents a significant challenge because each model constructs its own unique ‘representation space’ – a multi-dimensional map of concepts and relationships derived from the training data. Simply combining the outputs of these models through techniques like concatenation or averaging frequently diminishes predictive accuracy. This degradation occurs because the differing representation spaces create a mismatch in how each model understands and relates financial concepts; essentially, the models are ‘speaking different languages’. While each individual model may accurately interpret its source data, the combined output loses coherence and the nuanced signals necessary for robust financial prediction are lost in translation, highlighting the need for sophisticated methods to align these disparate understandings.
The inability of Large Language Models to seamlessly share learned representations presents a significant obstacle to building truly insightful financial forecasts. When models operate in disparate ‘knowledge spaces’, combining their analyses becomes problematic; simple methods like averaging predictions often dilute valuable signals, as each model interprets information through its unique lens. This lack of interoperability isn’t merely a technical inconvenience, but a fundamental limitation on the potential for generalization. A model trained on earnings calls, for example, struggles to effectively leverage insights gleaned from regulatory filings by a separate model, hindering the development of prediction systems that can adapt to novel data sources and shifting market conditions. Consequently, financial institutions face ongoing challenges in constructing robust and reliable forecasting tools capable of navigating the complexities of modern financial landscapes.
FinAnchor: A Common Language for LLMs (If Only It Were That Simple)
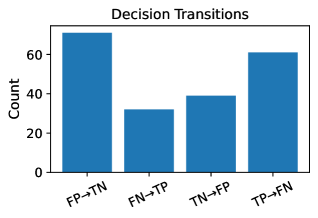
FinAnchor mitigates the issue of representation misalignment arising when integrating outputs from multiple language models by transforming each model’s embeddings into a unified ‘Anchor Space’. This process addresses the inherent variability in how different encoders represent semantic information; without normalization, direct comparison or aggregation of these representations is unreliable. The Anchor Space serves as a common coordinate system, enabling consistent interpretation of features across all participating encoders. By projecting diverse, model-specific representations into this shared space, FinAnchor facilitates effective knowledge transfer and allows for meaningful comparison and combination of information derived from disparate language models.
Linear Alignment within FinAnchor utilizes Ridge Regression to establish a mapping between the output spaces of individual encoders and the designated ‘Anchor Space’. Ridge Regression, a penalized least squares regression technique, minimizes the error between predicted and actual values while simultaneously minimizing the magnitude of the regression coefficients. This is achieved by adding a regularization term – specifically, the squared magnitude of the coefficients – to the loss function. The resulting optimization process yields a linear transformation matrix for each encoder, effectively projecting its outputs into the shared Anchor Space. The regularization prevents overfitting and improves the generalization capability of the alignment, particularly crucial when dealing with varying encoder architectures and data distributions. The objective function can be represented as \min_{W} ||XW - Y||^2 + \lambda ||W||^2 , where X represents the encoder outputs, Y represents the anchor outputs, W is the transformation matrix, and λ is the regularization parameter.
FinAnchor facilitates knowledge transfer and aggregation between Large Language Models (LLMs) by establishing a shared coordinate system, termed the ‘Anchor Space’. This allows for the comparison and combination of outputs from LLMs with differing architectures and training data. Specifically, FinAnchor utilizes ‘Gemma’ as the anchor encoder, meaning all other LLM outputs are projected into the same space as Gemma’s representations. This projection enables direct comparison of knowledge encoded by diverse models, supporting tasks like weighted averaging of predictions or feature-level fusion, ultimately improving overall system performance and robustness.
Putting FinAnchor to the Test: The Illusion of Accuracy
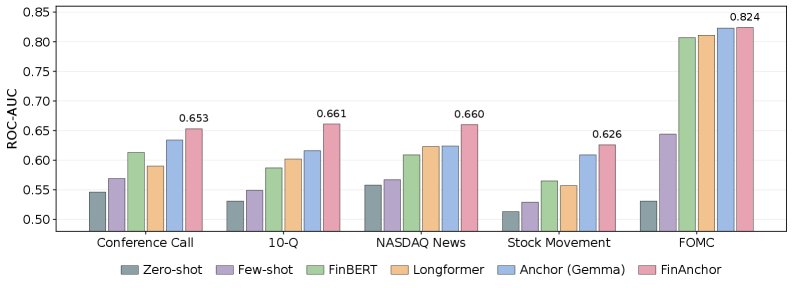
FinAnchor’s performance was assessed through evaluation on three distinct financial prediction tasks. These included ‘Earnings Surprise Prediction’, which forecasts whether a company’s reported earnings will exceed or fall short of analyst expectations; ‘Stock Movement Prediction’, a binary classification task determining if a stock price will increase or decrease; and ‘FOMC Stance Classification’, categorizing Federal Open Market Committee statements as hawkish, dovish, or neutral. This multi-task approach allowed for a comprehensive assessment of FinAnchor’s generalization capabilities across varied financial forecasting scenarios.
Comparative analysis demonstrates FinAnchor’s superior performance across evaluated financial prediction tasks. Specifically, on Stock Movement Prediction, FinAnchor achieved an accuracy of 0.693, exceeding the performance of baseline models Longformer and Hierarchical FinBERT. Similarly, in the FOMC Stance Classification task, FinAnchor attained an accuracy of 0.643, consistently outperforming the aforementioned baselines. These results indicate FinAnchor’s enhanced capacity for accurate prediction within these financial contexts.
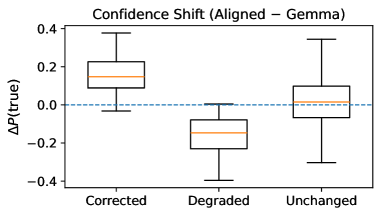
Analysis of FinAnchor’s predictions revealed substantial ‘Decision Transitions’ and ‘Confidence Shifts’ relative to baseline models. This indicates that FinAnchor not only achieves higher accuracy, but also provides more nuanced and reliable predictions. Specifically, the model demonstrated a capacity to revise initial predictions based on evolving data, resulting in more confident and ultimately more accurate outcomes. On the Stock Movement Prediction task, FinAnchor achieved a ROC-AUC score of up to 0.693, demonstrating its ability to discriminate between positive and negative stock movements with increased certainty compared to alternatives.
The Devil in the Details: Alignment Quality and the Road Ahead
The efficacy of FinAnchor hinges on a robust ‘Representation Alignment Quality’, rigorously assessed through R2 scores which consistently demonstrate a high degree of linear correlation between the embedding spaces of the source financial data and its designated anchor. This quantitative validation confirms that FinAnchor effectively maps complex financial concepts into a shared, understandable vector space, allowing for meaningful comparisons and improved predictive power. Specifically, high R2 values indicate that a substantial proportion of the variance in the anchor embedding space can be explained by the source embedding space, signifying a faithful and accurate alignment. This strong correlation is not merely a technical detail; it underpins the framework’s ability to generalize across diverse financial datasets and consistently deliver reliable insights.
The FinAnchor framework distinguishes itself by providing a versatile methodology for integrating multiple Large Language Models (LLMs) when analyzing textual financial data. Rather than depending on the output of a single model – a potentially limiting approach susceptible to individual biases or inaccuracies – the system leverages the collective intelligence of several LLMs. This ensemble approach significantly enhances the robustness of financial predictions and assessments. By combining insights from diverse models, the framework minimizes the risk associated with over-reliance on any single source, leading to more stable and reliable outcomes across various financial instruments and data types. The generalized nature of FinAnchor means it isn’t restricted to specific datasets or LLM architectures, offering adaptability and scalability for a wide range of financial applications.
Ongoing research intends to move beyond static embedding spaces by investigating dynamic anchor spaces that adapt to changing market conditions. This involves exploring methods where the selection of anchor points isn’t fixed, but rather evolves over time, potentially incorporating attention mechanisms or reinforcement learning to identify the most relevant comparisons. Crucially, the integration of temporal information – such as historical price data, news sentiment trends, and macroeconomic indicators – is anticipated to significantly refine prediction accuracy. By acknowledging that financial relationships are rarely static, the framework aims to capture evolving market dynamics, enabling more nuanced and responsive financial modeling and forecasting – ultimately moving beyond simple correlation to a more sophisticated understanding of causal relationships within complex financial systems.
The pursuit of aligned multi-model representations, as detailed in FinAnchor, feels predictably optimistic. It’s a natural inclination to believe combining strengths will yield stability, but production systems rarely cooperate so neatly. As John McCarthy observed, “The best way to predict the future is to invent it,” and this paper attempts precisely that – inventing a more robust predictive model. However, the very act of invention introduces new points of failure. FinAnchor seeks to mitigate instability through representation alignment, a laudable goal, yet one destined to become tomorrow’s tech debt. The elegant theory will, inevitably, encounter the harsh reality of real-world financial data, forcing a compromise between ideal alignment and pragmatic functionality. It’s not a flaw; it’s the pattern.
What’s Next?
The pursuit of aligned multi-model representations, as exemplified by FinAnchor, feels… predictably ambitious. It’s always the alignment phase that gets them. The paper correctly identifies representation instability as a critical issue, but glosses over the fact that instability is often a feature, not a bug. Markets change. Models drift. The carefully constructed alignment will, inevitably, require constant recalibration – a maintenance cycle they’ll call ‘adaptive learning’ and justify with another grant. It used to be a simple bash script that just copied the last known value, honestly.
The real challenge isn’t just combining LLMs, it’s acknowledging their fundamental limitations when applied to inherently noisy, adversarial systems. FinAnchor attempts to build a more robust predictor, but the underlying chaos remains. They’ve layered complexity upon complexity, and while it might yield marginal gains on backtests, one suspects it will eventually succumb to the same fate as all elegantly engineered systems: brittle failure in production. They’ll call it AI and raise funding, naturally.
Future work will undoubtedly focus on scaling this approach – more models, more data, more parameters. But a more fruitful avenue might involve embracing the inherent uncertainty, focusing on risk management, and accepting that prediction, in the financial realm, is always a probabilistic exercise. Though, admittedly, that’s far less glamorous than promising ‘state-of-the-art’ performance.
Original article: https://arxiv.org/pdf/2602.20859.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Brent Oil Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- EUR ZAR PREDICTION
2026-02-25 08:28