Author: Denis Avetisyan
A new framework and benchmark suite aim to ensure financial large language models are reliable, transparent, and ready for real-world deployment.
This paper introduces the Open FinLLM Leaderboard and AgentOps framework for evaluating and governing financial large language models across their entire lifecycle.
Despite rapid advancements in large language models, applying them to the complexities of financial reasoning remains challenging due to a lack of specialized expertise. This paper introduces an ‘Evaluation and Benchmarking Suite for Financial Large Language Models and Agents’ designed to address this gap by providing a comprehensive lifecycle-spanning exploration, readiness, and governance-for FinLLMs and FinAgents. The suite includes collaborative initiatives like the Open FinLLM Leaderboard and AgentOps framework to foster robust, reliable, and ethically-sound systems. Will these tools pave the way for a new era of trustworthy and impactful artificial intelligence in finance?
The Illusion of Progress: FinLLMs Enter the Arena
The financial sector is witnessing a surge in the adoption of Large Language Models, extending their capabilities beyond simple text processing to encompass a diverse range of tasks. These models are no longer confined to basic information retrieval; instead, they are actively being deployed in areas such as automated report generation, sentiment analysis of market news, fraud detection, and even predictive financial forecasting. This rapid expansion is fueled by the promise of significant gains in operational efficiency through automation and the potential to unlock previously inaccessible insights from vast datasets. The ability of LLMs to process and interpret complex financial language, identify patterns, and generate human-quality text is driving innovation across the industry, with applications ranging from algorithmic trading to personalized financial advice and risk management.
Recent advancements in artificial intelligence have yielded promising results in the financial sector, notably with the development of Large Language Models (LLMs) specifically tailored for financial tasks. Models such as BloombergGPT and, increasingly, FinGPT are demonstrating the feasibility of applying these technologies to complex financial analysis. FinGPT, for example, has achieved an impressive 85% accuracy in financial numerical reasoning – a benchmark significantly exceeding the 55% accuracy of more general-purpose models like Perplexity. This substantial performance gap highlights the benefits of specialized training and fine-tuning for the nuances of financial data, suggesting that LLMs are not simply replicating existing analytical methods, but offering a pathway toward more accurate and insightful financial decision-making.
Despite the considerable power of current Large Language Models, their implementation in financial contexts demands rigorous scrutiny and adaptation. These models are susceptible to “hallucinations,” instances where they generate factually incorrect or nonsensical information – a critical flaw when dealing with sensitive financial data. Recent evaluations highlight this vulnerability; for example, Google AI Overview has been shown to produce inaccurate or misleading summaries in financial reports 43% of the time. This underscores the necessity for robust evaluation metrics, specialized training datasets tailored to financial nuances, and ongoing monitoring to mitigate the risk of flawed insights and ensure reliable performance before widespread adoption can occur.
Benchmarking the Inevitable: Measuring What Matters (Or Doesn’t)
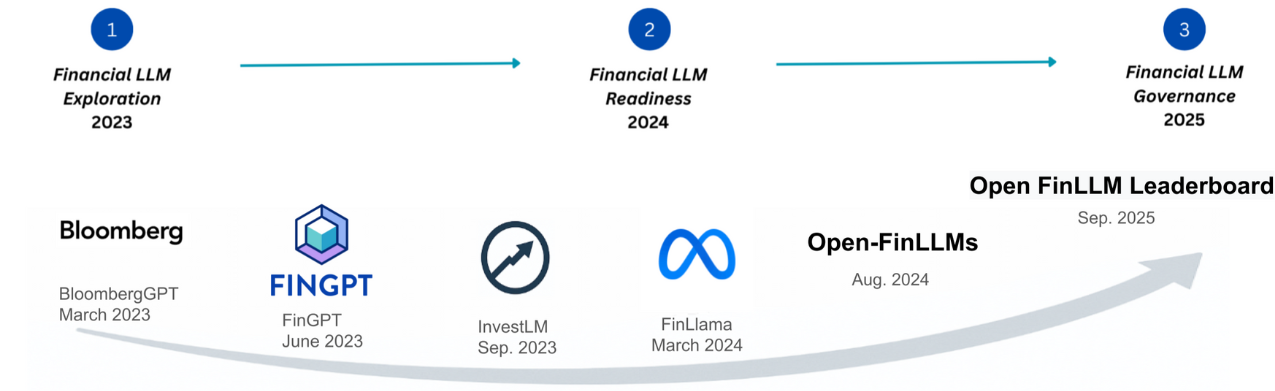
The second stage of FinLLM development prioritizes systematic evaluation to quantify model capabilities across a spectrum of financial applications. This evaluation phase moves beyond initial training and focuses on objective measurement of performance on tasks including, but not limited to, forecasting, risk assessment, and regulatory compliance. Rigorous testing identifies strengths and weaknesses, allowing for targeted improvements and ensuring models meet the demands of real-world financial scenarios. The emphasis is on establishing quantifiable metrics, facilitating comparative analysis, and ultimately increasing confidence in the reliability and accuracy of FinLLMs before deployment.
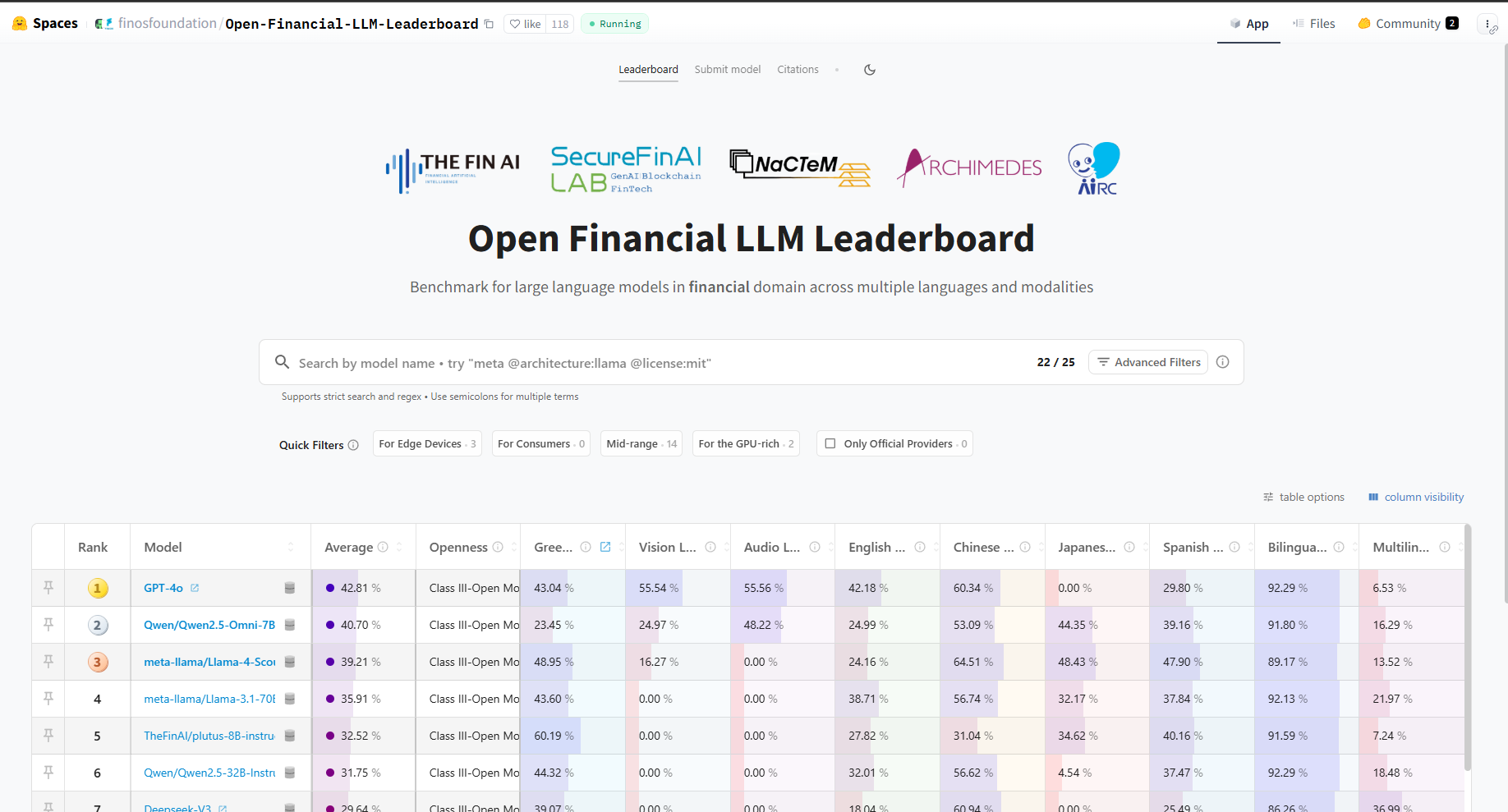
Standardized benchmarks, such as MultiFinBen and FinanceBench, are essential for the objective comparison of FinLLM models across a range of financial tasks. These benchmarks provide a consistent and reproducible framework for evaluating performance on specific datasets and metrics, including question answering, financial forecasting, and regulatory compliance. Utilizing these benchmarks allows developers to identify strengths and weaknesses in their models, track progress over time, and pinpoint areas requiring further development. The availability of standardized metrics facilitates meaningful comparisons between different models, fostering innovation and accelerating advancements in the field of financial language modeling.
The Open FinLLM Leaderboard is a publicly accessible platform designed to track and compare the performance of financial large language models (FinLLMs) across a standardized set of benchmarks. Functioning as a community resource, it enables researchers and developers to submit model results, facilitating transparent progress monitoring and identifying leading approaches. The leaderboard utilizes objective metrics derived from datasets like MultiFinBen and FinanceBench to rank models, providing a quantitative basis for comparison. This collaborative environment promotes reproducibility and accelerates innovation within the FinLLM field by encouraging open sharing of models and evaluation methodologies.
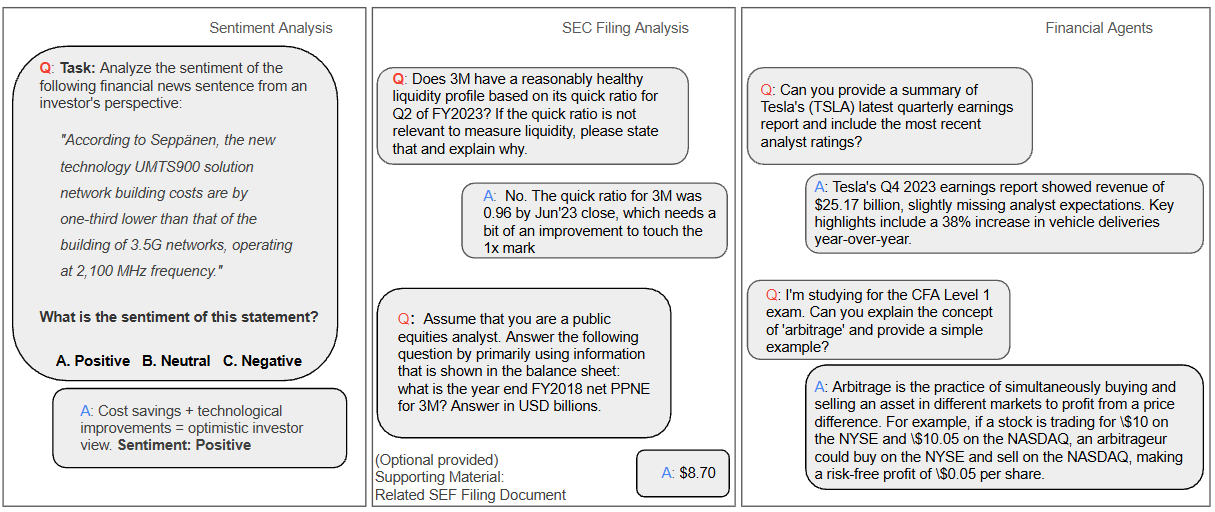
Sentiment analysis and the automated analysis of Securities and Exchange Commission (SEC) filings represent critical applications where robust benchmarking is essential for verifying accuracy and reliability. Recent evaluations have demonstrated significant inaccuracies in AI-generated financial information; specifically, a study found that 57% of life insurance information provided by Google AI Overview was incorrect. This highlights the potential for misinformation and underscores the necessity of standardized benchmarks, such as those provided by tools like the SEC Analyzer and Agentic FinSearch, to objectively assess the performance of financial language models and ensure the trustworthiness of their outputs when processing complex financial data.
The Illusion of Control: Towards Responsible FinAI Governance (And Why It’s Probably Too Late)
The culmination of FinLLM development necessitates a dedicated focus on responsible AI implementation within the financial sector, a domain acutely sensitive to data breaches, regulatory compliance, and ethical lapses. This final stage moves beyond mere algorithmic performance, prioritizing robust security protocols to safeguard confidential financial data and intellectual property. Simultaneously, it addresses growing concerns around algorithmic bias and fairness, striving for transparency and accountability in decision-making processes. Consideration extends to privacy-preserving techniques and the establishment of clear ethical guidelines, acknowledging that trust is paramount in financial applications and that unchecked AI deployment could erode public confidence and invite significant legal repercussions. Ultimately, responsible FinAI governance isn’t simply about mitigating risks; it’s about building a sustainable and equitable financial future powered by artificial intelligence.
Protecting the confidentiality of financial data and proprietary algorithms demands increasingly sophisticated security measures. Air-gapped deployment, a technique isolating the FinLLM system from public networks, prevents external access and data breaches, creating a physically and logically secure environment. Complementing this, zero-knowledge proofs allow verification of computations without revealing the underlying data itself; a system can prove it performed a financial calculation correctly without disclosing the sensitive numbers used. These aren’t merely theoretical concepts, but crucial safeguards against malicious attacks and data leaks, particularly as FinLLMs handle increasingly complex and valuable information. Implementing such advanced techniques is no longer optional, but a fundamental requirement for building trust and ensuring the responsible deployment of AI in the financial sector.
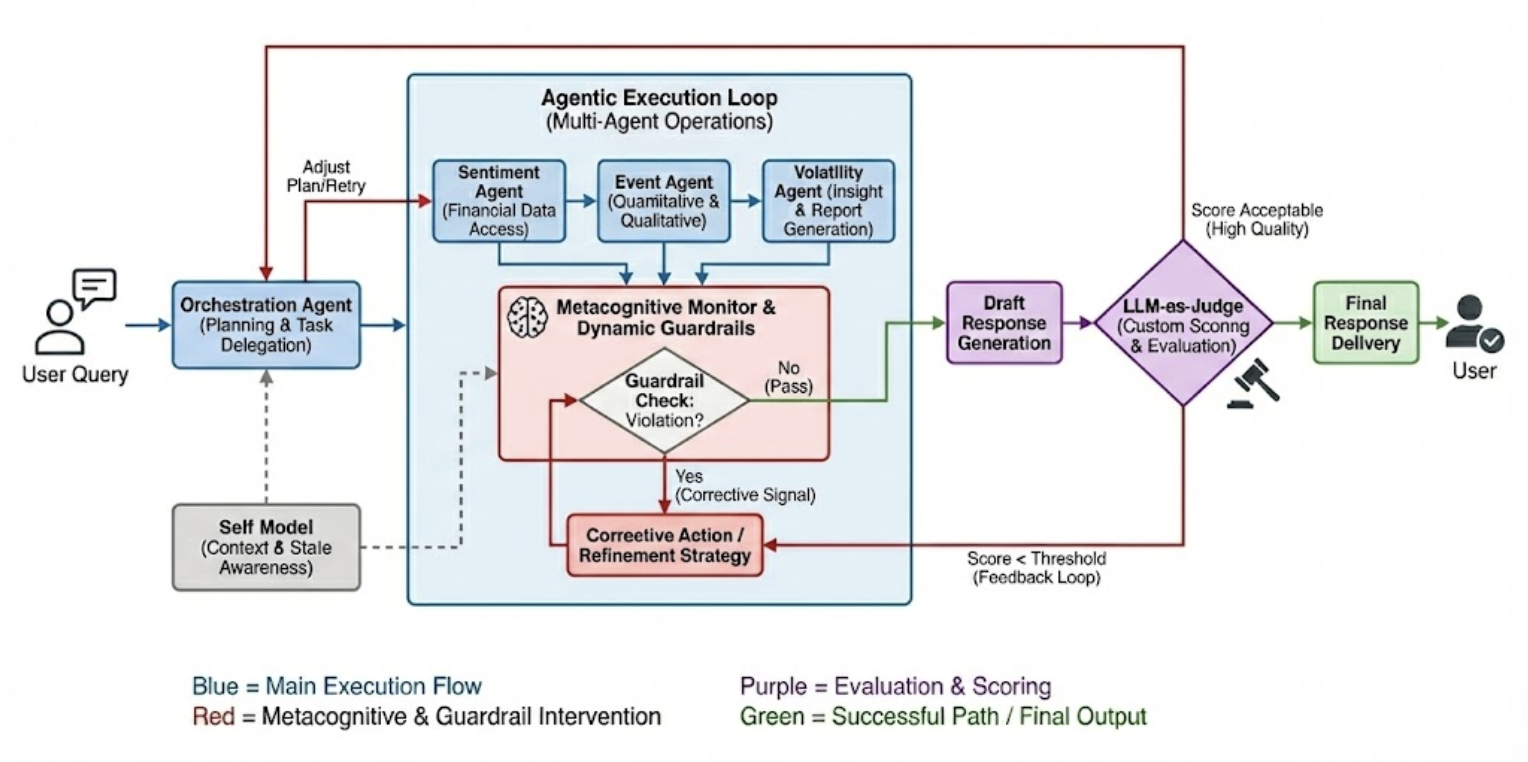
To address the inherent opacity of increasingly sophisticated financial AI agents, the AgentOps Framework offers a systematic approach to behavioral evaluation. This framework isn’t simply about testing outcomes, but dissecting the process by which an agent arrives at a decision. Central to this is Trajectory Tracing, a tool that meticulously records and visualizes the agent’s reasoning steps – the data accessed, the inferences made, and the rules applied – creating an auditable record of its actions. This detailed lineage allows developers and regulators to identify potential biases, errors, or unintended consequences embedded within the agent’s logic. By fostering transparency and accountability, AgentOps and tools like Trajectory Tracing are crucial for building trust in FinAI systems and ensuring responsible deployment within complex financial landscapes.
The FinSight Agent represents a significant advancement in financial AI, functioning as a metacognitive system deliberately designed with governance principles at its core to ensure robust and trustworthy analysis. Recent trials, notably a 43-minute interaction during the Tesla 2024 Q3 earnings conference call, highlighted the intricate nature of agent behavior when processing complex, real-time information. This extended Q&A session served as a crucial stress test, revealing the necessity for exhaustive evaluation protocols to not only assess analytical accuracy but also to understand the reasoning behind the agent’s conclusions and ensure alignment with established financial regulations and ethical guidelines. The complexity observed underscores that simply achieving correct answers is insufficient; a truly responsible FinAI system must demonstrate how it arrives at those answers, fostering transparency and accountability in financial decision-making.
The pursuit of a robust lifecycle for financial LLMs, as detailed in the paper-exploration, readiness, and governance-feels predictably optimistic. It’s a neat structure, naturally. One anticipates production will inevitably introduce chaos. As Tim Berners-Lee observed, “The Web is more a social creation than a technical one.” This sentiment rings true; even the most carefully constructed ‘AgentOps’ framework, designed for reliable FinAI systems, will ultimately bend to the unpredictable demands of real-world financial data and user behavior. The leaderboard, while a useful metric, merely documents the current state of breakage, not prevents it. Every abstraction, however elegantly designed, dies in production; at least it dies beautifully.
What’s Next?
The proposal of a lifecycle – exploration, readiness, governance – for financial LLMs feels less like innovation and more like acknowledging the inevitable. Any framework claiming to anticipate production issues operates under the assumption that those issues haven’t yet manifested. Anything self-healing just hasn’t broken yet. The Open FinLLM Leaderboard, while laudable, will likely measure speed to failure, not resilience. A high score today merely identifies the most elegant system awaiting its first critical edge case.
The AgentOps framework hints at a desire for control over systems demonstrably resistant to it. Retrieval-Augmented Generation, a favored technique, merely externalizes the hallucination problem-the model isn’t wrong, the data is. And documentation? A collective self-delusion, meticulously detailing how the system should work, rather than how it will work when confronted with adversarial input.
Future work will inevitably focus on mitigating the consequences of failures, not preventing them. If a bug is reproducible, the system isn’t unstable-it’s defined. The true metric of success won’t be benchmark scores, but the cost of cleaning up after the inevitable, elegantly-designed collapse.
Original article: https://arxiv.org/pdf/2602.19073.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Brent Oil Forecast
- EUR ZAR PREDICTION
- EUR USD PREDICTION
- 币安人生 PREDICTION. 币安人生 cryptocurrency
- Amazon Primes new GenAI cartoon looks like K-Pop Demon Hunters with aliens
2026-02-24 10:34