Author: Denis Avetisyan
Researchers have identified a key mechanism driving training failures in large language models and developed an optimizer to address it.
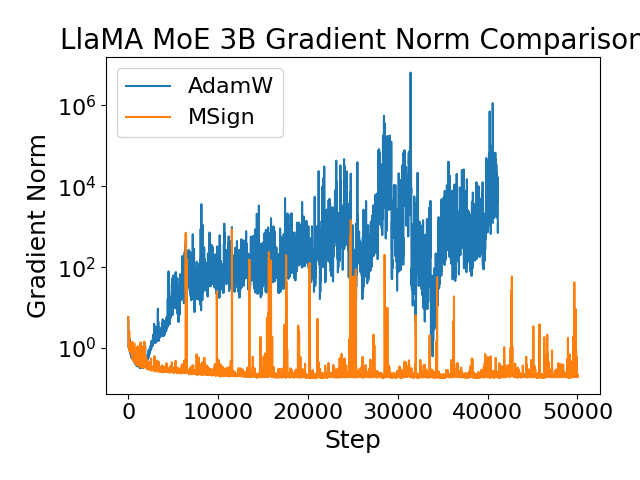
MSign restores stable rank during training to prevent gradient explosions and improve robustness in large language models.
Despite the rapid progress in large language models, training instability remains a persistent challenge, often leading to wasted computational resources. This work, ‘MSign: An Optimizer Preventing Training Instability in Large Language Models via Stable Rank Restoration’, investigates the underlying mechanisms driving these failures in models up to 3 billion parameters, identifying a critical link between declining stable rank and increasing alignment of layer Jacobians. We demonstrate theoretically that these phenomena jointly induce exponential gradient growth, and introduce MSign, a novel optimizer that periodically restores stable rank via matrix sign operations to mitigate this effect. Can this approach unlock more robust and efficient training regimes for even larger and more complex language models?
The Fragile Foundation of Large Language Models
Despite remarkable advancements in natural language processing, training large language models remains a surprisingly delicate process. The pursuit of optimal performance frequently necessitates multiple training restarts and meticulous adjustments to hyperparameters – values that govern the learning process itself. This isn’t merely a matter of fine-tuning; the training process is inherently prone to instability, where small changes can lead to dramatic shifts in the model’s behavior and even complete failure. Researchers have observed that even with substantial computational resources and carefully curated datasets, achieving a consistently stable training run is a significant challenge, demanding constant monitoring and intervention to prevent the model from diverging from effective learning.
The training of large language models is frequently plagued by instability, readily apparent in the dramatic escalation of gradients during the learning process. This isn’t simply a matter of slow convergence; unchecked gradients can cause the model’s weights to diverge, effectively halting learning and necessitating a restart. Compounding this issue is a concurrent collapse in the stable rank of the weight matrices – a measure of how much information is genuinely contributing to the model’s function. As training progresses, these matrices become increasingly dominated by a few dominant singular values, indicating a loss of expressive capacity and hindering the model’s ability to learn complex patterns. This combination of exploding gradients and rank collapse suggests a fundamental fragility in the training dynamics, demanding careful calibration of hyperparameters and sophisticated optimization techniques to maintain stable and effective learning.
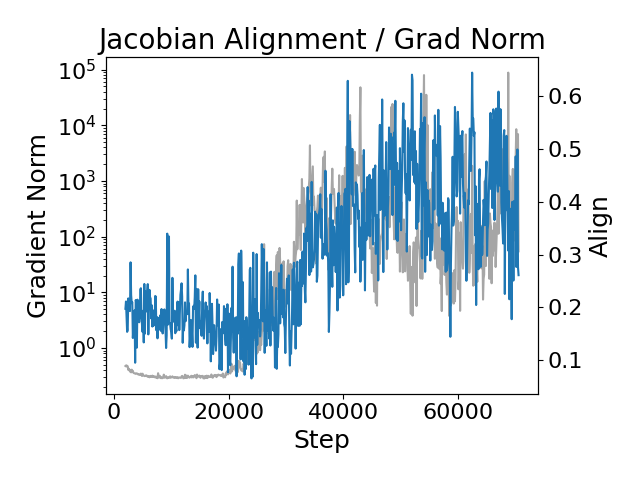
The inherent instability observed during large language model training stems, in part, from a phenomenon known as Jacobian alignment growth. As training progresses, the Jacobians – matrices representing the sensitivity of each layer’s output to its input – tend to become increasingly aligned. This synchronization reduces the effective dimensionality of the learning process, causing gradients to rapidly escalate during backpropagation. Essentially, aligned Jacobians create a feedback loop where updates in one layer are amplified across subsequent layers, hindering the model’s ability to explore the loss landscape effectively. The resulting gradient explosions and vanishing gradients destabilize learning and necessitate careful hyperparameter tuning or even complete restarts of the training process, revealing a fundamental vulnerability within these complex neural networks.
The surprising efficiency of large language models – their ability to achieve strong performance with fewer parameters than initially anticipated – stems from a pervasive low-rank structure within their weight matrices. However, this very characteristic introduces a fundamental fragility to the training process. As training progresses, the tendency towards low rank amplifies the impact of disruptive forces, such as exploding or vanishing gradients. Specifically, a loss of stable rank-the number of non-zero singular values-signals a breakdown in the model’s ability to learn effectively, leading to instability. This suggests that LLMs operate close to a critical point; while low rank enables efficient representation, it simultaneously makes them exceptionally sensitive to the perturbations inherent in gradient-based optimization, necessitating careful tuning and potentially new training strategies to maintain stability.
Unveiling the Mathematical Roots of Instability
Recent theoretical work demonstrates a quantifiable relationship between stable rank collapse, Jacobian alignment growth, and gradient explosion during Large Language Model (LLM) training. Specifically, increases in Jacobian alignment – a measure of how consistently gradients flow through the network’s layers – correlate with a reduction in the stable rank of the model’s weight matrices. The stable rank, representing the effective dimensionality of the weight matrix, diminishes as alignment increases, leading to a condition where small perturbations in the input data or weights can cause exponentially growing gradients. This phenomenon, termed gradient explosion, destabilizes the training process and can result in model failure; the analysis formally defines this relationship as \Delta \text{stable rank} = k \cdot \Delta \text{Jacobian alignment} , where k is a constant dependent on network architecture and training parameters.
The observed relationship between Jacobian alignment and gradient instability is formalized through mathematical derivation. Increasing Jacobian alignment – measured as the cosine similarity between the Jacobian matrices of different layers – directly correlates with a reduction in the stable rank of the neural network’s weight matrices. Specifically, higher alignment concentrates singular values, decreasing the gap between them and reducing stable rank. This loss of stable rank amplifies gradient norms during backpropagation; as the condition number of the weight matrices increases, even small perturbations in the loss function can result in exponentially growing gradients – a phenomenon known as gradient explosion. \sigma_{max} / \sigma_{min} represents this condition number, where \sigma_{max} and \sigma_{min} are the maximum and minimum singular values, respectively, demonstrating the direct link between alignment, rank collapse, and gradient instability.
Prior to this work, observed training instabilities in Large Language Models (LLMs) were largely empirical; interventions were developed based on observed symptom mitigation, not foundational cause. This theoretical framework moves beyond observation by formally defining the relationships between stable rank collapse, Jacobian alignment growth, and gradient explosion. Specifically, mathematical derivations demonstrate that increasing Jacobian alignment directly reduces the stable rank of the neural network’s weight matrices. This reduction in stable rank, quantified by a decrease in the minimum singular value, then mathematically necessitates the growth of gradient norms, ultimately leading to unstable training dynamics. By establishing these causal links – \text{Jacobian Alignment} \rightarrow \text{Stable Rank Collapse} \rightarrow \text{Gradient Explosion} – the framework provides a predictive understanding of instability, enabling targeted interventions based on first principles rather than empirical tuning.
Maintaining stable rank during large language model (LLM) training is critical for preventing catastrophic failures because a reduction in stable rank directly correlates with increased Jacobian alignment and the subsequent onset of gradient explosion. Stable rank, a measure of the dimensionality of the non-zero singular values of the Jacobian matrix, indicates the effective rank of the model’s updates; a decrease signifies a loss of information capacity during training. As stable rank collapses, the model becomes increasingly susceptible to amplified gradients, as the alignment of the Jacobian grows, leading to parameter updates that destabilize the training process and potentially result in NaN values or divergent behavior. Therefore, interventions aimed at preserving or restoring stable rank are essential for robust and reliable LLM training.

MSign: A Rank-Maximizing Optimizer for Stability
The MSign optimizer addresses instability during large language model (LLM) training through the periodic application of the matrix sign operation to weight matrices. This operation, denoted as sign(W) for a given weight matrix W, projects the matrix onto the space of matrices with orthogonal eigenvectors, effectively reshaping the weight distribution. Unlike traditional weight decay or gradient clipping methods, MSign directly modifies the weight matrices themselves, intervening in the training process to prevent the accumulation of detrimental weight configurations. The frequency of this operation is a hyperparameter, allowing for tuning based on model size and training data characteristics. This intervention is designed to counteract issues arising from high internal covariate shift and vanishing/exploding gradients, both common obstacles in training deep neural networks.
The matrix sign operation, applied periodically during training, directly addresses the phenomenon of rank collapse in large language models. Rank collapse refers to the reduction in the singular values of weight matrices, leading to a loss of information and diminished model capacity. By enforcing a positive definite structure on weight matrices via the matrix sign, the stable rank – the number of non-zero singular values – is maximized. This stabilization prevents the exponential growth of gradients that typically accompanies rank collapse, thus mitigating gradient explosions and enabling more robust and efficient training. Maintaining a higher stable rank ensures the model retains representational capacity throughout the training process, supporting the learning of complex patterns and relationships within the data.
Restoring stable rank through the MSign optimizer directly impacts training scalability by enabling the use of larger learning rates. Rank collapse during LLM training typically necessitates conservative learning rate selection to prevent gradient instability; however, MSign mitigates this collapse, allowing for significantly increased learning rates without inducing divergence. This capability is crucial for effectively training larger models, as the computational cost of each training step increases with model size, and aggressive learning rates are needed to accelerate convergence and achieve optimal performance within a reasonable timeframe. Consequently, MSign facilitates the successful training of models with increased parameter counts that would otherwise be intractable due to instability or excessive training duration.
The MSign optimizer minimizes computational overhead by strategically applying the matrix sign operation within existing attention layers. Rather than performing a full matrix sign calculation on the entire weight matrix, the method decomposes this operation into computations already present in the attention mechanism – specifically, utilizing the eigenvectors of the weight matrix which are efficiently computed during attention calculations. This integration avoids the need for separate, costly matrix decompositions and allows the matrix sign to be approximated with minimal additional computational burden, scaling effectively with model size and enabling its application to large language models.
Empirical Validation: Scaling Stability with MSign
Rigorous experimental validation reveals that the MSign optimizer markedly enhances training stability for large language models spanning a considerable scale, from 5 million to 3 billion parameters. Across this range, models utilizing MSign consistently demonstrate a reduced propensity for training failures, achieving successful convergence where standard optimization techniques often falter. This improved stability is not simply a matter of reaching the same endpoint; MSign allows for more reliable and predictable training runs, crucial for efficient research and development of increasingly complex language models. The optimizer’s effectiveness suggests a practical confirmation of the theoretical underpinnings regarding stable rank and its influence on the training process, providing a pathway toward more robust and scalable deep learning architectures.
Training large language models often encounters instability, manifesting as erratic gradient behavior and ultimately, failure to converge. Recent experimentation reveals that employing the MSign optimizer demonstrably mitigates these issues. Models leveraging MSign consistently exhibit significantly reduced fluctuations in gradient norms throughout the training process, indicating a smoother and more predictable learning trajectory. This stabilization directly translates to a markedly higher probability of successful convergence – meaning the model reliably reaches a functional state where it can effectively process and generate text. The observed reduction in gradient volatility suggests MSign effectively manages the complex parameter updates inherent in large model training, fostering a more robust and dependable learning process.
The observed improvements in large language model training stability with the MSign optimizer provide compelling validation of preceding theoretical work. Researchers posited that maintaining a stable rank throughout the training process-specifically, preventing abrupt drops in the singular values of the weight matrix-was crucial for avoiding catastrophic divergence. The experimental results now demonstrate a clear correlation between MSign’s mechanism for preserving stable rank and a marked reduction in training failures, even at scale. This confirms that the previously identified mathematical principles aren’t merely abstract concepts, but directly impact the practical feasibility of training increasingly complex neural networks. The success of MSign therefore not only offers a solution to a persistent engineering challenge, but also reinforces the value of theoretically grounded approaches to deep learning optimization.
The implementation of MSign introduces a modest reduction in training throughput, ranging from 4.6 to 6.7 percent; however, this represents a worthwhile trade-off considering the substantial gains in training stability it provides. Crucially, the optimizer enables successful training runs for large language models where conventional methods consistently fail to converge, unlocking the potential to explore more complex architectures and larger parameter spaces. This ability to consistently achieve convergence, even when faced with challenging training dynamics, outweighs the minor decrease in computational efficiency, positioning MSign as a valuable tool for advancing the frontiers of language model development.

The pursuit of increasingly large language models often introduces unforeseen complexities. This work addresses a critical, yet subtle, point: training instability stemming from stable rank collapse. It’s a demonstration of how diminishing returns can manifest not as marginal improvement, but as systemic failure. Vinton Cerf observed, “The Internet treats everyone the same.” Similarly, this research reveals that the fundamental mathematical structures governing these models demand consistent attention; a neglected rank collapses, and the entire system suffers. The elegance of MSign lies in its focused intervention – restoring stable rank – a testament to the principle that impactful solutions are frequently found through strategic subtraction rather than additive complexity. It’s a corrective measure, demonstrating that a stable foundation is paramount for robust scaling.
Where Do We Go From Here?
The identification of stable rank collapse as a central mechanism of instability in large language models offers a useful, if belated, refinement of the prevailing narrative. The focus has, until now, been largely on variance and magnitude of gradients. The proposed intervention-periodic stable rank restoration via the matrix sign operation-is, at its core, a pragmatic exercise in dimensionality reduction. It accepts the inherent noisiness of the optimization landscape and seeks not to eliminate it, but to constrain its expression. Future work will inevitably explore the minimal frequency of restoration required for stable training, and whether adaptive schemes-responding to detected rank deficiencies-can further streamline the process.
A more profound question concerns the relationship between stable rank and generalization. Is a higher stable rank necessarily better? Or does it merely reflect a greater capacity for memorization? The tendency for these models to converge towards low-rank solutions suggests an underlying principle of efficient representation. Understanding whether this efficiency is a byproduct of optimization, or an inherent property of natural language itself, demands further investigation.
Ultimately, this line of inquiry forces a reckoning with the fundamental limitations of scale. Simply adding parameters does not guarantee improved performance. It merely increases the complexity of the optimization problem. The art, it seems, lies not in building ever-larger models, but in sculpting them with ever greater precision-removing the superfluous, and revealing the underlying structure.
Original article: https://arxiv.org/pdf/2602.01734.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- X-Men ’97 Finally Gave Gambit the Hero Moment He Deserved
- 46 Years Later, The Mandalorian & Grogu Answers A Major Empire Strikes Back Question
- HoI4 fans harsh reactions to the announcement of another DLC pack
- 10 Worst End-Game Couples In Sitcom History
- Emily Henry Says to ‘Trust the Vision’ For Beach Read Adaptation
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Gold Rate Forecast
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
2026-02-09 22:21