Author: Denis Avetisyan
A new pruning strategy targets unstable attention patterns in diffusion models to significantly improve computational efficiency without sacrificing performance.
Sink-Aware Pruning leverages variance statistics to identify and discount unreliable attention sinks, leading to increased sparsity and faster inference.
Efficient inference with large language models remains a critical challenge, particularly for emerging diffusion language models (DLMs). This paper, ‘Sink-Aware Pruning for Diffusion Language Models’, addresses this by challenging the conventional wisdom-inherited from autoregressive models-of preserving ‘attention sink’ tokens during pruning. We demonstrate that these sinks exhibit substantially higher variance across generation timesteps in DLMs, indicating their reduced structural importance compared to their role in autoregressive models. Consequently, we propose a novel pruning strategy that automatically identifies and removes unstable sinks without retraining, achieving improved quality-efficiency trade-offs; but can this approach be generalized to other model architectures and sparsity techniques?
The Quadratic Bottleneck: Scaling Limits of Dense Attention
The remarkable capabilities of standard Transformer models are fundamentally linked to the Attention Mechanism, a process allowing the model to weigh the importance of different input elements. However, this very strength introduces a significant computational bottleneck as sequence length increases. The Attention Mechanism’s complexity scales quadratically with the input sequence – meaning doubling the sequence length quadruples the computational demands. This presents a critical challenge, particularly when processing lengthy documents, high-resolution images, or extended audio clips. Each element within the sequence must be compared to every other element to determine its relevance, creating a rapidly expanding matrix of calculations that quickly overwhelms available resources and hinders the model’s ability to scale to more complex tasks requiring a broader contextual understanding. Consequently, research focuses on mitigating this quadratic complexity to unlock the full potential of Transformers for real-world applications.
The inherent limitations in processing lengthy sequences significantly impede the performance of Transformers when tackling complex tasks that require deep contextual understanding. Applications like nuanced language translation, detailed document summarization, and comprehensive video analysis demand the model consider extensive prior information – yet, computational costs increase disproportionately with sequence length. This presents a critical bottleneck, as the attention mechanism, while powerful, struggles to scale efficiently, hindering the model’s ability to extract meaningful relationships across vast datasets. Consequently, tasks requiring the integration of long-range dependencies suffer from diminished accuracy and slower processing times, ultimately limiting the practical application of these models in real-world scenarios.
Despite efforts to streamline Transformer models through pruning techniques, many current approaches, notably unstructured pruning, deliver disappointing results. These methods attempt to reduce computational load by removing individual connections within the network, yet often achieve only marginal gains in sparsity – the proportion of removed connections – while simultaneously causing a significant drop in model performance. The haphazard nature of unstructured pruning disrupts the carefully learned representations within the network, impacting its ability to generalize and maintain accuracy. Consequently, the computational benefits are frequently overshadowed by the performance cost, demonstrating a critical need for more intelligent pruning strategies that preserve essential network functionality and truly address the efficiency limitations of dense Transformers.
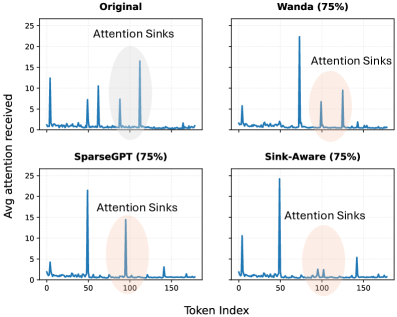
Identifying Attention Focal Points: The Concept of Attention Sinks
Attention mechanisms within transformer models do not distribute weight evenly across all input tokens. A subset of tokens consistently receives a disproportionately high amount of attention, regardless of input variations; these are defined as ‘Attention Sinks’. This phenomenon indicates that the model prioritizes specific tokens during processing, potentially relying on them for key information or contextual understanding. Identifying these sinks is crucial because their prevalence and stability can reveal insights into the model’s internal reasoning and offer opportunities for targeted optimization or pruning without significantly impacting performance.
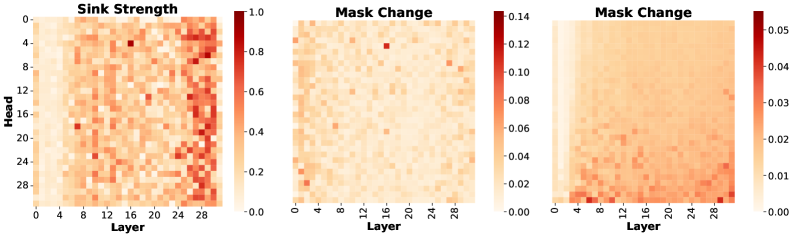
Sink Variance, a quantitative metric, assesses the consistency of attention focused on a given token across multiple input sequences. Higher Sink Variance indicates that a token consistently receives a significant proportion of attention, suggesting it plays a crucial role in the model’s reasoning. Conversely, low Sink Variance implies the attention directed towards a token fluctuates considerably, signifying its potential unimportance or redundancy. The correlation between Sink Variance and model performance demonstrates that pruning attention pathways connected to low-variance sinks results in minimal impact on accuracy, while removing high-variance sinks significantly degrades performance – establishing Sink Variance as a reliable proxy for attention relevance.
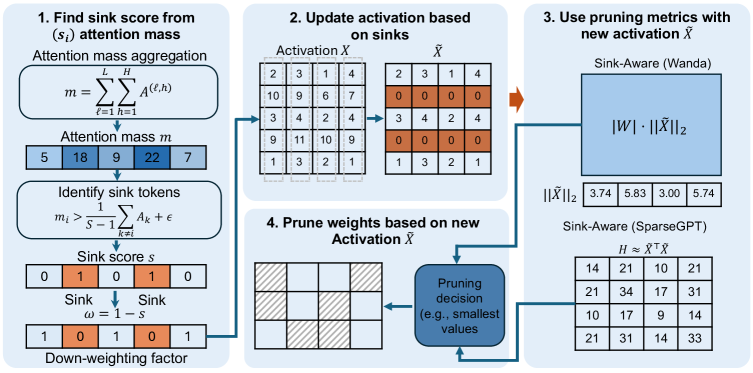
Sink-Aware Pruning represents a departure from conventional attention pruning techniques by focusing on the stability of attention sinks – tokens receiving disproportionately high attention. Instead of randomly or uniformly removing attention weights, this method calculates ‘Sink Variance’ to identify unstable sinks, indicating those less critical to the model’s reasoning. Pruning then selectively removes attention pathways to and from these unstable sinks. This targeted approach minimizes disruption to the model’s core functionality, potentially achieving higher sparsity levels with less performance degradation compared to methods that treat all attention weights equally.
Empirical Validation: Precision Pruning Across Diverse Models
Sink-Aware Pruning was successfully implemented and validated across a range of large language models, specifically LLaDA, Dream, and LLaDA-1.5. Implementation involved integrating the pruning methodology into the model architectures and conducting comprehensive testing to assess its efficacy. These models were selected to represent diverse scales and configurations within the LLM landscape, allowing for evaluation of the method’s generalizability. Successful implementation is defined as the ability to consistently apply the pruning process without causing runtime errors or structural instability in the tested models.
Sink-Aware Pruning utilizes a Calibration Dataset to quantify the stability of individual model weights, referred to as ‘sinks’, prior to their removal. This dataset, separate from the training or evaluation data, is used to calculate a stability score for each weight based on the change in loss when that weight is perturbed. Weights exhibiting minimal loss increase upon perturbation are designated as stable sinks and prioritized for retention during the pruning process. The size and composition of the Calibration Dataset are critical; it must be representative of the model’s expected input distribution to provide an accurate assessment of sink stability and prevent unintended performance regressions following pruning. This pre-pruning analysis allows for a more informed and precise identification of weights that can be removed without significantly impacting model accuracy.
Evaluation of Sink-Aware Pruning utilized the MMLU (Massive Multitask Language Understanding), ARC-C (AI2 Reasoning Challenge – Challenge Set), and PIQA (Physical Interaction Question Answering) benchmarks to quantify performance changes resulting from increased sparsity. Results indicate consistent gains in model sparsity without substantial performance loss across these standardized tests. Specifically, measurable accuracy improvements were observed on each benchmark following the application of Sink-Aware Pruning, demonstrating the method’s ability to maintain, and in some cases enhance, predictive capabilities while reducing model size.
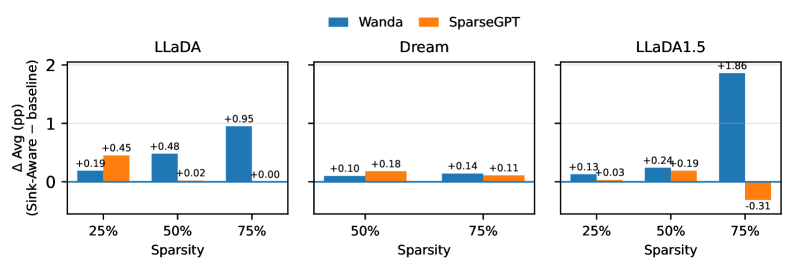
Sink-Aware Pruning demonstrates performance advantages over Wanda and SparseGPT in large language model pruning. Empirical results across models LLaDA, Dream, and LLaDA-1.5, evaluated on benchmarks MMLU, ARC-C, and PIQA, indicate that Sink-Aware Pruning consistently achieves comparable or higher accuracy at increased sparsity levels. Specifically, the method avoids substantial performance regressions observed in Wanda and SparseGPT when aggressively pruning model weights, thereby maintaining a superior accuracy-sparsity trade-off across multiple evaluations and architectures.
Towards Efficient Language Models: A New Paradigm for Scalability
Sink-Aware Pruning represents a novel approach to reducing the size and computational demands of large language models by targeting what are known as ‘attention sinks’ – specific points within the model where attention disproportionately concentrates, yet exhibits instability. This technique doesn’t simply remove connections at random; instead, it selectively prunes these unreliable sinks, thereby minimizing information loss that would otherwise hinder the model’s ability to reason and generate coherent text. The core innovation lies in recognizing that not all attention is equal; by safeguarding the stable, informative connections while eliminating the erratic ones, Sink-Aware Pruning achieves significant compression – potentially reducing computational cost and memory footprint – without sacrificing the model’s core reasoning capabilities. This careful balancing act allows for more efficient models that retain a high degree of performance, even with substantial reductions in size and complexity.
Large language models, while increasingly powerful, demand substantial computational resources and memory – a significant barrier to wider accessibility and deployment. Sink-Aware Pruning offers a compelling solution by strategically reducing the model’s size without sacrificing core performance. This is achieved by identifying and removing less critical parameters, directly lowering both the computational cost of processing information and the memory required to store the model. The potential impact is considerable; a smaller model translates to faster inference speeds, reduced energy consumption, and the ability to run complex language tasks on devices with limited resources, effectively democratizing access to advanced AI capabilities. This efficiency doesn’t come at the expense of reasoning ability, as the pruning process is designed to preserve the most crucial elements of the model’s knowledge and understanding.
The principles guiding Sink-Aware Pruning are not limited to the specific transformer architectures currently under investigation. Researchers anticipate a significant expansion of its applicability, with ongoing work focused on adapting the technique to convolutional neural networks and recurrent neural networks – model types prevalent in image and speech processing. Beyond these architectural variations, the core concept of identifying and selectively removing unstable, high-loss attention points is being explored across different data modalities, including audio and video analysis. This broader application promises not only to reduce the computational demands of these models, but also to potentially enhance their generalization capabilities and robustness by focusing on the most critical information pathways, paving the way for more efficient and adaptable artificial intelligence systems.
A deeper comprehension of attention sinks within large language models promises not only more efficient architectures, but also enhanced interpretability and robustness. Recent investigations reveal that selectively addressing these sinks – points where the model disproportionately focuses attention – yields significant performance gains, particularly when applied with moderate to high levels of sparsity, between 50% and 75%. This suggests that a substantial portion of a model’s parameters may be redundant or contribute minimally to core reasoning abilities, and that aggressive compression – reducing model size and computational demands – doesn’t necessarily equate to diminished performance when informed by an understanding of these critical attention focal points. Consequently, refining techniques to identify and manage attention sinks offers a pathway towards creating language models that are both computationally lean and demonstrably reliable in their decision-making processes.
The pursuit of efficiency in diffusion language models, as detailed in this work, echoes a fundamental principle of information theory. Claude Shannon famously stated, “The most important thing in communication is to convey information with the least possible redundancy.” Sink-Aware Pruning directly addresses redundancy within the attention mechanism. By identifying and discounting unstable attention sinks – those contributing little to the core information flow – the method achieves sparsity without significantly impacting performance. This aligns with Shannon’s emphasis on minimizing noise and maximizing signal clarity; the pruning strategy effectively filters out the ‘noise’ of unreliable attention heads, enabling a more concise and effective communication of information within the model. The paper’s focus on variance statistics to identify these sinks showcases a mathematical rigor consistent with the pursuit of provably optimal solutions.
Beyond the Sinkhole
The observation that attention sinks behave distinctly in diffusion versus autoregressive models is, admittedly, less a revelation than a necessary correction. The uncritical application of pruning strategies developed for one generative paradigm to another demonstrates a regrettable lack of mathematical rigor. The current work, while demonstrating improved efficiency, merely treats a symptom. A complete understanding demands a formal characterization of these ‘sinks’ – not as empirical curiosities, but as emergent properties of the diffusion process itself. Proof of convergence, not merely performance on benchmarks, should be the ultimate metric.
Future research must address the limitations of variance-based discounting. While statistically convenient, it offers no guarantee of stability. A more robust approach might involve exploring the geometric properties of the attention manifold, seeking pruning strategies that preserve intrinsic dimensionality and information flow. Furthermore, the timestep-adaptive nature of the proposed method hints at a deeper connection between pruning and the noise schedule – a relationship deserving of dedicated investigation.
Ultimately, the goal is not simply to create smaller models, but to construct provably correct ones. The elegance of a pruned network lies not in its sparsity, but in the mathematical certainty that every remaining parameter contributes meaningfully to the generative process. Until that standard is met, the pursuit of efficiency remains, at best, an elegant approximation.
Original article: https://arxiv.org/pdf/2602.17664.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- How to Get to the Undercoast in Esoteric Ebb
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Mewgenics vinyl limited editions now available to pre-order
- All Itzaland Animal Locations in Infinity Nikki
- Warframe Voruna Prime access begins on April 8 for all platforms, new deluxe cosmetic Warframe skins revealed
- NASA astronaut reveals horrifying tentacled alien is actually just a potato
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
2026-02-22 16:35