Author: Denis Avetisyan
A new framework reveals how embracing high-dimensional data, when combined with a focus on quality, can unlock surprisingly accurate and robust machine learning models.
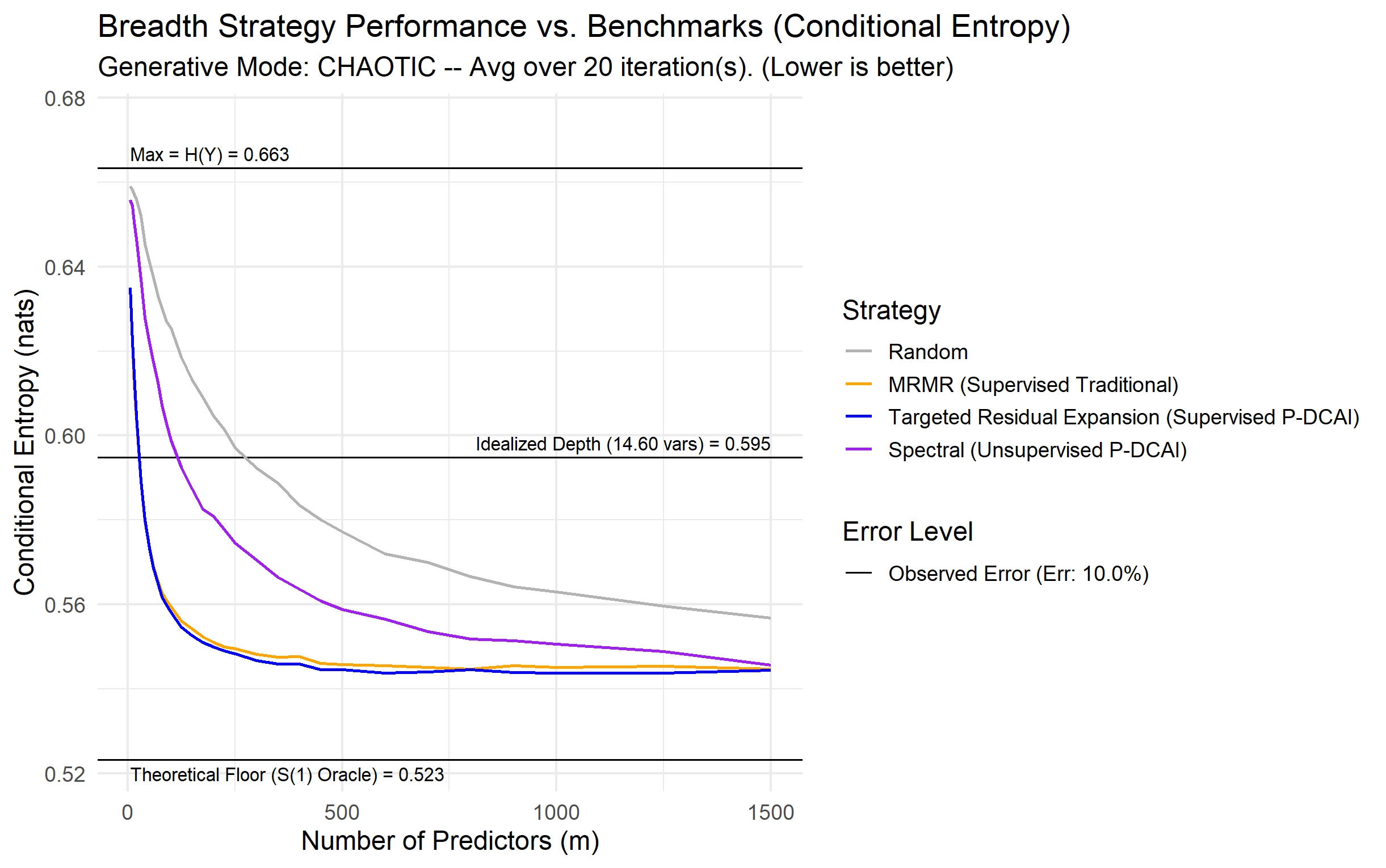
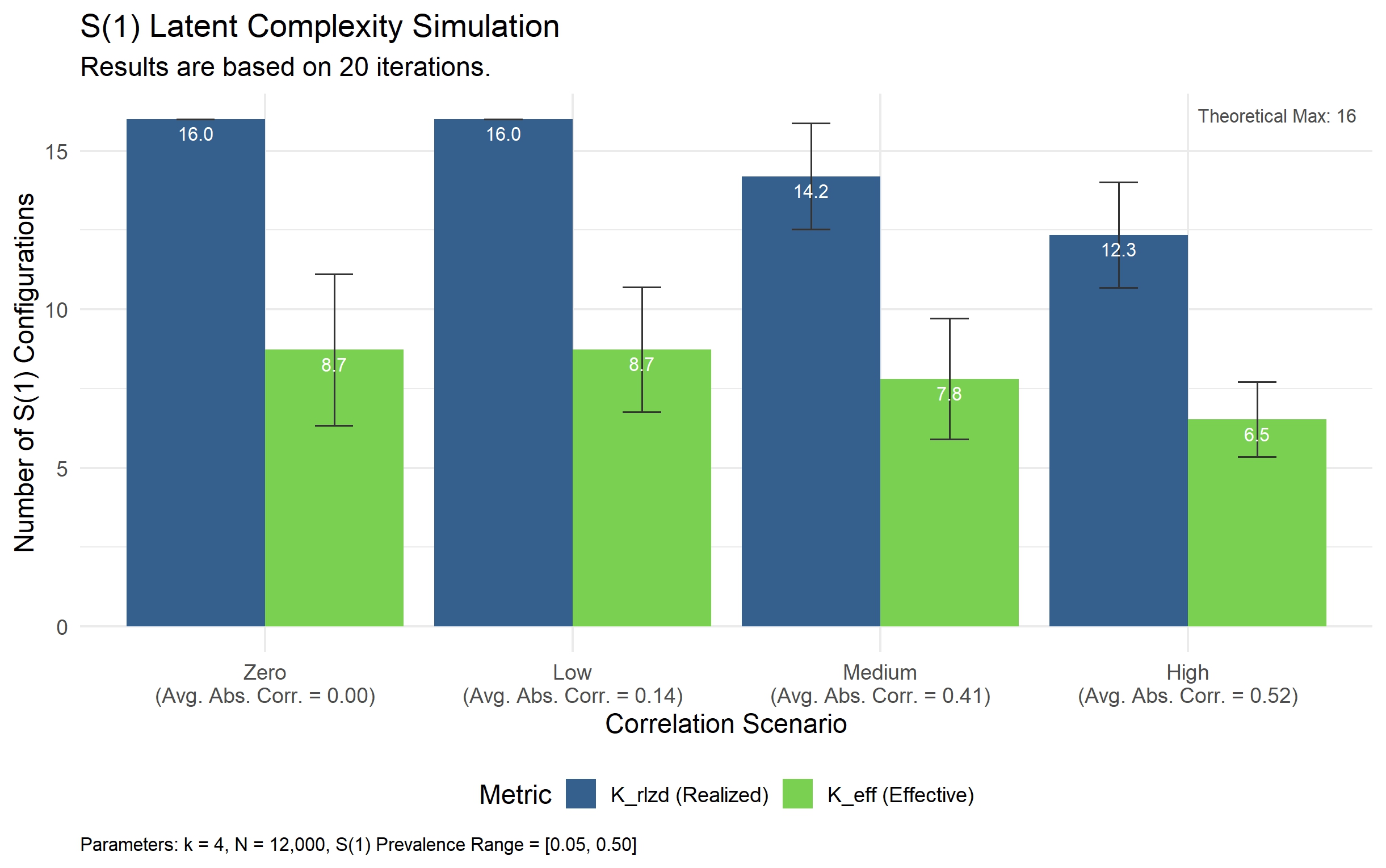
This review proposes a data-centric AI theory, demonstrating that informative redundancy within high-dimensional datasets can mitigate overfitting and enhance predictive performance.
Despite the prevailing “Garbage In, Garbage Out” mantra, modern machine learning routinely achieves high performance with noisy, high-dimensional data-a seeming paradox addressed in ‘From Garbage to Gold: A Data-Architectural Theory of Predictive Robustness’. This work synthesizes principles from Information Theory and Latent Factor Models to demonstrate that predictive robustness arises not from data cleanliness, but from the synergistic interplay between data architecture and model capacity-specifically, that high dimensionality can asymptotically overcome both predictor error and structural uncertainty. By redefining data quality as a portfolio-level architecture rather than item-level perfection, this framework offers a theoretical foundation for learning from uncurated “data swamps” and shifting from model transfer to methodology transfer. Could prioritizing data architecture over algorithmic complexity unlock a new paradigm for building robust and generalizable AI systems?
Navigating the Alignment Challenge: Guiding LLMs Toward Intent
While Large Language Models (LLMs) excel at generating human-quality text, crafting outputs that consistently adhere to nuanced human preferences presents a formidable obstacle. These models, trained on vast datasets, often prioritize statistical likelihood over genuine alignment with intent, leading to responses that may be factually correct yet unhelpful, biased, or even harmful. The challenge isn’t simply about avoiding incorrect information; it’s about capturing the subtleties of human communication – understanding implied meaning, recognizing appropriate tone, and adapting to diverse perspectives. Ensuring LLMs consistently generate text that is not only coherent but also aligned with human values and expectations demands innovative approaches to training, evaluation, and control, moving beyond mere text prediction to genuine communicative intelligence.
Controlling the behavior of large language models often presents a considerable hurdle due to the complexity and computational demands of established techniques. Methods like reinforcement learning from human feedback, while effective, require extensive datasets of human preferences and significant processing power for training. Furthermore, techniques focused on fine-tuning models with specific constraints can be brittle, failing to generalize to unseen prompts or exhibiting unexpected side effects. This computational expense and practical difficulty limit the widespread deployment of LLMs in resource-constrained environments or real-time applications, creating a need for more efficient and scalable alignment strategies. The challenge isn’t simply what an LLM says, but ensuring consistent, predictable, and affordable control over how it generates text.
The Intricacies of Reinforcement Learning from Human Feedback
Reinforcement Learning from Human Feedback (RLHF) addresses the challenge of aligning Large Language Models (LLMs) with human intentions by directly incorporating subjective evaluations into the training process. Rather than relying solely on objective metrics or pre-defined rules, RLHF utilizes human preferences as a reward signal. This is achieved by having human raters compare different LLM-generated outputs for a given prompt and indicating which response is more desirable based on criteria such as helpfulness, honesty, and harmlessness. These comparisons are then used to train a reward model, which learns to predict human preferences. The LLM is subsequently fine-tuned using reinforcement learning techniques, maximizing the reward predicted by the reward model, thus iteratively improving its alignment with human expectations.
Reward Modeling within Reinforcement Learning from Human Feedback (RLHF) involves training a separate model to predict human preferences for LLM outputs, typically using pairwise comparisons of responses to the same prompt. This reward model then serves as the basis for Policy Learning, where the LLM’s policy is iteratively refined to maximize the predicted reward. A critical component of this refinement is often the incorporation of KL Divergence, a measure of how much the updated policy deviates from the original, pre-RLHF policy; this acts as a regularizer to prevent the policy from drifting too far and destabilizing the model’s overall performance and general capabilities. KL(P||Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)}
Implementing Reinforcement Learning from Human Feedback (RLHF) necessitates significant computational investment due to the multi-stage process. Training a reward model requires large datasets of human preference labels, often necessitating extensive annotation efforts. Subsequently, policy learning, typically utilizing algorithms like Proximal Policy Optimization (PPO), demands substantial GPU resources for iterative model updates. Furthermore, careful hyperparameter tuning is crucial at each stage – reward modeling, and policy learning – to prevent issues like reward hacking or divergence. The KL divergence penalty, commonly employed to stabilize training, also introduces another tunable parameter. The interplay between these components and the sensitivity to hyperparameter selection contribute to the overall complexity and resource demands of RLHF pipelines.
Direct Preference Optimization: A Streamlined Approach to Alignment
Direct Preference Optimization (DPO) streamlines Large Language Model (LLM) alignment by bypassing the intermediate step of reward modeling, which is central to Reinforcement Learning from Human Feedback (RLHF). Instead of training a separate reward model to predict human preferences, DPO directly optimizes the language model’s policy to align with the provided preference data. This is achieved by formulating the alignment problem as a binary classification task where the model learns to distinguish between preferred and dispreferred responses. Consequently, DPO reduces the complexity and potential instability associated with training and maintaining a reward model, leading to a more efficient and stable alignment process.
The Direct Preference Optimization (DPO) algorithm utilizes a dataset comprising human-ranked outputs for a given prompt, establishing a clear preference between two or more responses. Training is achieved through Binary Cross-Entropy Loss, which measures the difference between the predicted probability of a preferred response and the actual preference label. This loss function directly optimizes the language model’s policy to increase the likelihood of generating preferred outputs. Specifically, the algorithm aims to maximize the log-likelihood of the preferred response while minimizing the log-likelihood of the dispreferred response, effectively learning from relative preferences without requiring absolute reward scores. The resulting policy update is computationally efficient, as it bypasses the need for iterative reward modeling and reinforcement learning steps.
Direct Preference Optimization (DPO) achieves improved stability and computational efficiency over Reinforcement Learning from Human Feedback (RLHF) by eliminating the reward modeling step. Traditional RLHF requires training a separate reward model from preference data, which introduces potential inaccuracies and instability during policy optimization. DPO bypasses this intermediary step by directly optimizing the language model policy using the preference dataset and a binary cross-entropy loss function. This direct optimization reduces the complexity of the training pipeline and minimizes the risk of reward hacking or divergence, resulting in a more robust and computationally less expensive alignment process. The simplification also allows for faster experimentation and iteration on alignment strategies.
Evaluating DPO: Demonstrating Performance and Efficiency Gains
Recent evaluations indicate that Direct Preference Optimization (DPO) rivals, and in some cases surpasses, Reinforcement Learning from Human Feedback (RLHF) in the crucial task of aligning large language models with human preferences. Through rigorous experimentation, researchers have demonstrated DPO’s ability to generate responses that are consistently favored by human evaluators – achieving similar, or even improved, alignment scores compared to models trained using the more complex RLHF paradigm. This performance is particularly notable given DPO’s simplified training process, suggesting that directly optimizing for preference data can be a highly effective, and computationally efficient, approach to steering language model behavior towards desired outcomes. The findings highlight DPO as a strong contender for future alignment strategies, offering a pathway to create more helpful, harmless, and honest AI assistants.
Direct Preference Optimization (DPO) demonstrably improves training stability in large language models by sidestepping the complexities inherent in traditional Reinforcement Learning from Human Feedback (RLHF). Unlike RLHF, which relies on a separate reward model and policy optimization, DPO directly optimizes the language model’s policy by framing the alignment problem as a supervised learning task. This simplification dramatically reduces the risk of policy divergence-a common issue in RLHF where the model’s behavior drifts unpredictably-and fosters more reliable performance throughout training. Consequently, DPO enables more consistent and predictable model behavior, streamlining the development process and yielding language models with demonstrably improved robustness and trustworthiness.
Direct Preference Optimization (DPO) presents a compelling advantage over traditional Reinforcement Learning from Human Feedback (RLHF) through substantial reductions in computational demands and data requirements. Conventional RLHF often necessitates complex reward modeling and iterative policy optimization, proving resource-intensive and slow to converge. DPO, however, reframes the alignment process as a straightforward supervised learning problem, directly optimizing the language model’s policy towards preferred responses. This simplification translates to a markedly lower computational cost, allowing for training with fewer parameters and less hardware. Moreover, DPO demonstrates enhanced sample efficiency, achieving comparable alignment performance with significantly less human preference data. This makes DPO particularly attractive for practical applications where labeled data and computational resources are limited, paving the way for more accessible and scalable deployment of aligned large language models.
The pursuit of predictive robustness, as outlined in the G2G framework, hinges on a seemingly counterintuitive principle: embracing high dimensionality not as a curse, but as an opportunity. This echoes Grace Hopper’s sentiment: “It’s easier to ask forgiveness than it is to get permission.” The article posits that managing dimensionality effectively, through a focus on informative redundancy and mutual information, allows for the creation of models that are not merely accurate, but also resilient. This mirrors Hopper’s pragmatic approach-a willingness to explore potentially complex solutions if they yield a more robust and ultimately simpler outcome. Good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
Beyond Garbage In, Gold Out
The proposition that high dimensionality need not be a curse, but a potential boon, rests on a delicate equilibrium. This work suggests that prioritizing data quality-specifically, informative redundancy-can indeed tame the beast. However, the precise quantification of “informative” remains an open question. The mutual information metrics presented are a starting point, yet they represent only one lens through which to view the relationship between data structure and predictive power. Future work must address the limitations of any single information-theoretic measure and explore complementary approaches to characterizing data quality in high-dimensional spaces.
A critical consideration lies in the scalability of these techniques. While the benefits of G2G are demonstrable, applying it to truly massive datasets-those characteristic of modern machine learning applications-presents significant computational challenges. Simplification will inevitably be required, and each such step carries a cost. The art, and the future direction of this research, will be to identify those simplifications that preserve the essential structure without sacrificing robustness.
Ultimately, the pursuit of predictive robustness is not merely a technical exercise. It is an acknowledgment that models are, at best, imperfect representations of complex systems. The elegant solution isn’t always the most complex algorithm; often, it’s a deeper understanding of the data itself – a return to first principles, recognizing that structure dictates behavior, even in the messy world of high dimensionality.
Original article: https://arxiv.org/pdf/2603.12288.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- Euphoria Season 3’s New R-Rated Sydney Sweeney Scene Proves The Show Is Trolling Us
- Gold Rate Forecast
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Brent Oil Forecast
- What is Omoggle? The AI face-rating platform taking over Twitch
- 8 Funniest Billy Butcher Quotes From The Boys
- MNT PREDICTION. MNT cryptocurrency
- Crypto Chaos: Are Your Bitcoins and Ethereums Ready for a Wild Ride? 🚀😱
- 🇧🇷 Blockchain & AI: Brazil’s SUS Gets a Tech Makeover! 🚀
2026-03-17 03:25