Author: Denis Avetisyan
As large language models infiltrate financial analysis, a critical examination of potential biases is essential for reliable results.
This paper introduces a Structural Validity Framework to address biases in financial LLM evaluation, emphasizing backtesting rigor and the mitigation of temporal and survivorship biases.
Despite the increasing integration of Large Language Models (LLMs) into financial workflows, rigorous evaluation practices have not kept pace, potentially leading to inflated performance metrics and unreliable backtests. This position paper, ‘Evaluating LLMs in Finance Requires Explicit Bias Consideration’, identifies five recurring biases – look-ahead, survivorship, narrative, objective, and cost – that uniquely contaminate financial LLM applications and often compound to create an illusion of validity. We demonstrate that no single bias is addressed in the majority of recent studies, highlighting a critical gap in the field and proposing a ‘Structural Validity Framework’ alongside an evaluation checklist to enforce reproducible results. Can this framework establish a new standard for bias diagnosis and responsible LLM deployment within the financial sector?
Unveiling the Illusion: The Limits of Intelligence in Financial Models
The financial sector is experiencing a swift integration of Large Language Models, driven by the potential for significant advancements in forecasting and risk assessment. These models, capable of processing vast datasets and identifying complex patterns, are being applied to tasks ranging from algorithmic trading and credit scoring to fraud detection and market sentiment analysis. Proponents suggest these tools can unlock previously inaccessible insights, leading to more informed investment decisions and improved financial stability. However, this rapid deployment is occurring with limited understanding of the underlying limitations and potential biases inherent in these systems, raising concerns about the reliability and fairness of increasingly automated financial processes. The promise of enhanced predictive power is currently outpacing the development of robust validation techniques, creating a landscape where apparent success may not reflect genuine analytical superiority.
The increasing deployment of Large Language Models (LLMs) in financial forecasting and risk assessment presents a paradox: seemingly impressive performance may conceal fundamental weaknesses. A significant concern lies in the potential for biased training data to skew results, leading to inaccurate or unfair predictions. Recent research highlights a critical gap in addressing this issue; a user study revealed that 76% of participants lack adequate tools to effectively identify and mitigate these biases within financial LLMs. This scarcity of evaluation methodologies poses a substantial risk, as flawed models can perpetuate existing inequalities or generate erroneous insights without detection, undermining the reliability and trustworthiness of AI-driven financial systems. The absence of robust checks and balances threatens to transform statistical illusions into real-world financial consequences.
A Framework for Structural Integrity: Validating Financial Intelligence
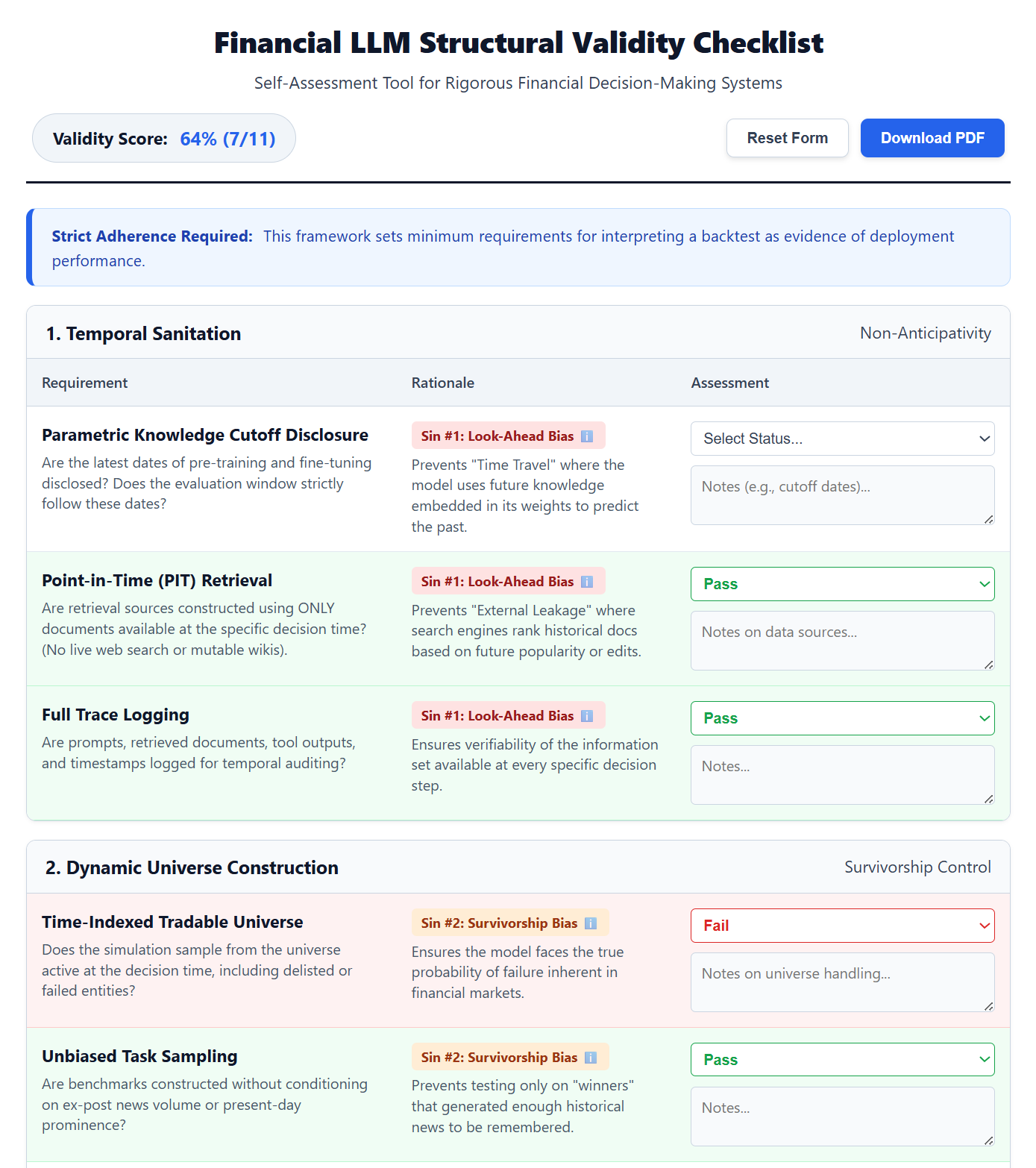
The Structural Validity Framework is a formalized, checklist-driven approach designed to address systematic biases inherent in evaluating Large Language Models (LLMs) within financial applications. This framework moves beyond simple performance metrics by proactively identifying potential sources of bias during test case construction and evaluation procedures. The checklist covers aspects such as data leakage, temporal contamination, and survivor bias, providing specific protocols to mitigate these risks. Implementation requires a documented process for creating and validating test datasets, alongside a rigorous assessment of model predictions to ensure fairness and reliability of evaluation results. The ultimate goal is to establish a standardized, reproducible methodology for assessing LLM performance in finance, fostering trust and enabling informed decision-making.
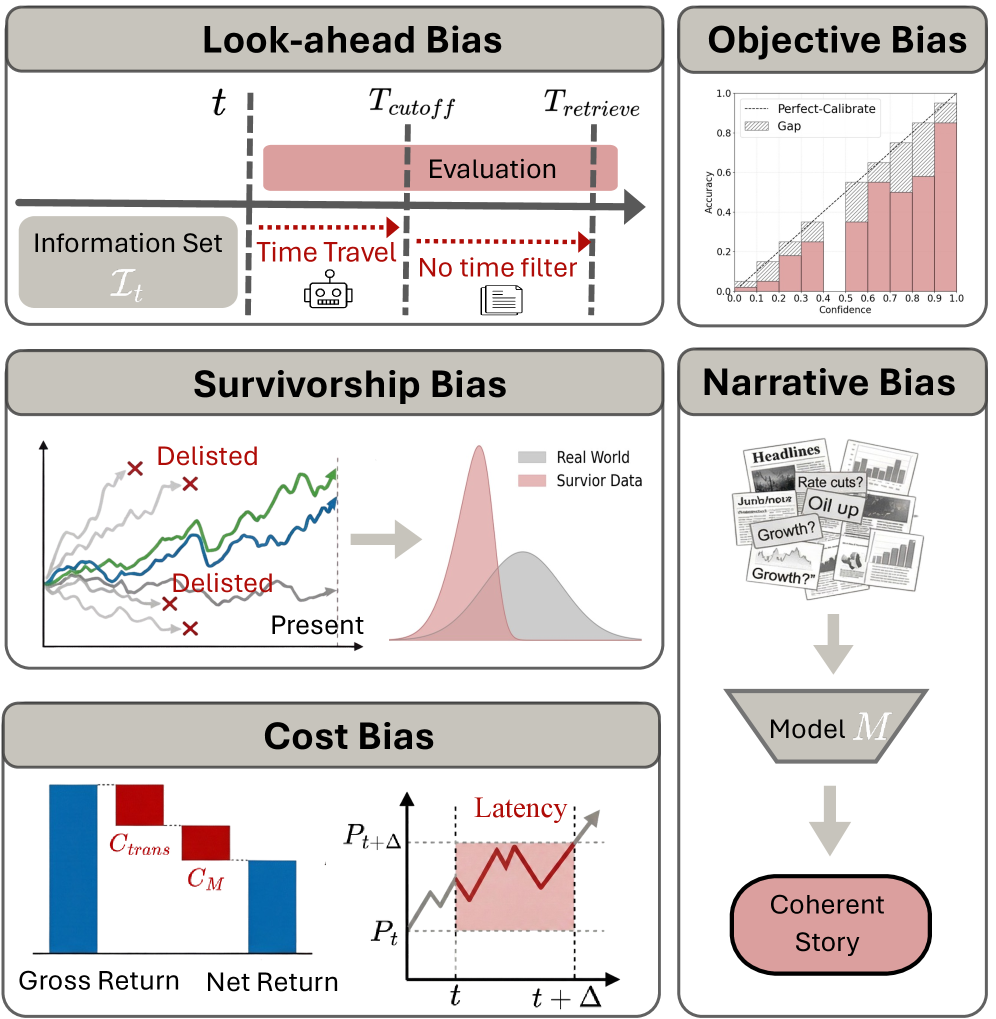
Temporal Sanitation and Dynamic Universe Construction are critical components for mitigating bias in financial Large Language Model (LLM) evaluations. Temporal Sanitation prevents ‘look-ahead’ bias by ensuring models only utilize data available at the time a prediction would have been realistically made; this typically involves strict data partitioning by time. Dynamic Universe Construction addresses survivor bias, a phenomenon where evaluations disproportionately favor entities that have successfully persisted to the present; this is achieved by constructing test sets that include entities that existed at the start of the evaluation period, regardless of their current status, thereby providing a more representative performance assessment.
Rationale Robustness, a core tenet of the Structural Validity Framework, requires that all evaluations of financial Language Learning Models (LLMs) include verifiable justifications for each prediction. This necessitates not simply assessing what a model predicts, but why it arrived at that conclusion. Evaluations must demand explicit rationales – ideally derived from the input data and model weights – and then subject these rationales to independent testing. This testing verifies that the stated reason for a prediction is logically sound and consistent with the observed outcome, preventing evaluations from being misled by correlations or spurious patterns and ensuring the model’s decision-making process is transparent and auditable.
Unmasking the Core Flaws: Common Biases in Financial Modeling
Look-Ahead Bias, Survivorship Bias, and Narrative Bias are prevalent issues in financial time series forecasting that systematically distort model performance evaluations. Look-Ahead Bias occurs when a model utilizes information unavailable at the time of the forecast, creating artificially high accuracy. Survivorship Bias arises from analyzing only currently existing entities, ignoring those that failed, thus overstating historical returns. Narrative Bias involves constructing explanations for past events that are not supported by data, leading to a misinterpretation of relationships and inflated expectations for predictive power. The consistent presence of these biases results in overoptimistic performance metrics that do not reflect the model’s true out-of-sample predictive capability.
Objective bias in financial modeling occurs when a model’s construction or evaluation emphasizes point predictions-confident completion of forecasts-at the expense of accurately representing the uncertainty inherent in those predictions. This prioritization leads to overconfident forecasts that appear more accurate than they are in reality, masking the model’s true predictive power and potentially underestimating associated risks. A well-calibrated model should not only provide a point estimate but also a reliable range of possible outcomes, reflecting the level of uncertainty; objective bias systematically suppresses this uncertainty representation, leading to misleading performance assessments and flawed decision-making.
Cost bias in financial modeling occurs when model evaluations fail to account for transaction costs, taxes, regulatory fees, or other practical expenses associated with implementing a trading strategy or investment approach. This omission results in inflated performance metrics – such as higher Sharpe ratios or annualized returns – that do not reflect realistic, achievable results in a live trading environment. Specifically, backtests and simulations may demonstrate profitability, but after factoring in real-world costs, the strategy may become unprofitable or significantly less attractive. Ignoring these expenses leads to overestimation of potential returns and misallocation of capital, potentially resulting in substantial financial losses when the model is deployed.
The Structural Validity Framework is designed to mitigate common biases – Look-Ahead, Survivorship, and Narrative – through defined validation techniques. These techniques include backtesting protocols adjusted for look-ahead bias, comprehensive dataset construction to address survivorship bias, and objective criteria for evaluating model narratives. A user study indicated that 48% of participants perceive existing research as offering limited guidance on identifying or measuring these biases, highlighting a gap in practical application and supporting the need for a formalized, structured approach like the Structural Validity Framework to improve bias detection and mitigation in financial modeling.
Towards Reliable Intelligence: Practicalities and Future Directions
A foundational element of trustworthy artificial intelligence in finance lies in epistemic calibration – the ability of a model to accurately reflect its own uncertainty. Rather than presenting predictions as definitive truths, a calibrated model assigns probabilities that genuinely correspond to the likelihood of an outcome, acknowledging what it doesn’t know. This isn’t merely a technical refinement; it’s critical for responsible deployment, as it allows stakeholders to appropriately assess risk and avoid over-reliance on potentially flawed outputs. Without this honest self-assessment, AI systems can inadvertently amplify biases or make confidently incorrect predictions, eroding trust and potentially leading to significant financial consequences. A system that understands – and communicates – its limitations fosters a more informed and cautious approach to decision-making, paving the way for genuinely reliable financial intelligence.
Successfully deploying artificial intelligence in financial contexts demands a careful reckoning with practical limitations, specifically the costs associated with computation and the unavoidable delays – or latency – in processing information. Overly optimistic projections of profitability often fail to account for these real-world constraints; a model demonstrating theoretical gains on a research dataset may prove economically unviable when scaled for live trading or high-frequency analysis. Consequently, rigorous evaluation must extend beyond statistical accuracy to encompass the financial feasibility of implementation, including infrastructure costs, energy consumption, and the impact of processing time on trade execution. By prioritizing models that balance performance with resource efficiency, the field can move beyond the allure of idealized results and focus on genuinely deployable solutions that deliver tangible value.
The confluence of sophisticated information extraction techniques and a robust validation framework promises to fundamentally reshape data-driven financial analysis utilizing Large Language Models. By accurately identifying and isolating key financial data points from diverse sources – news reports, earnings calls, regulatory filings – LLMs can move beyond simple textual summarization. However, raw extraction is insufficient; the integration of structural validity checks ensures the reliability and reduces the propagation of errors inherent in unstructured data. This rigorous approach allows for the creation of more accurate predictive models, refined risk assessments, and ultimately, more informed investment decisions. The true potential of LLMs in finance isn’t simply processing language, but transforming ambiguous information into dependable, actionable intelligence through validated data pipelines.
The pursuit of genuinely reliable financial intelligence hinges on a fundamental shift toward robust validation and uncertainty awareness. Current limitations in evaluation tools and frameworks – highlighted by the fact that 50% of surveyed participants cite this as the primary obstacle to mitigating bias – underscore the critical need for standardized, structural validity assessments. By embracing principles of epistemic calibration and realistic implementation constraints, the field can move beyond the allure of purely performant models and toward systems that acknowledge their limitations. This focus isn’t merely about improving accuracy; it’s about building trust and ensuring that data-driven financial analyses are both dependable and actionable, fostering a future where AI serves as a truly reliable partner in complex financial decision-making.
The pursuit of robust financial models, as detailed in the paper, necessitates a holistic understanding of systemic interconnectedness. Tim Berners-Lee aptly stated, “The Web is more a social creation than a technical one.” This sentiment echoes the paper’s central argument; evaluating Large Language Models (LLMs) within finance isn’t merely a technical exercise in benchmark achievement. The Structural Validity Framework proposed directly addresses the ‘social creation’ aspect – acknowledging that data, algorithms, and evaluation metrics are all shaped by human choices and prone to biases like survivorship bias. A seemingly isolated methodological flaw, such as inadequate temporal sanitation, introduces dependencies that ripple throughout the entire evaluation, impacting the reliability of results. The paper’s checklist functions as a means of understanding and mitigating these hidden costs, promoting a more responsible and structurally sound approach to LLM implementation in financial contexts.
What’s Next?
The pursuit of applying large language models to finance, predictably, has outstripped the development of genuinely rigorous evaluation. This work attempts to articulate the lurking pitfalls – temporal leakage, survivorship bias, and the insidious creep of model-driven data contortion – not as isolated problems, but as symptoms of a deeper structural weakness. The ‘Structural Validity Framework’ offered is not a solution, but a diagnostic. It highlights where careful consideration of system-level interactions is crucial, and where naïve application of standard machine learning techniques will inevitably lead to misleading results.
Future work must move beyond incremental improvements in backtesting methodologies. The field needs a broader embrace of causal inference, moving from correlation to understanding the true drivers of financial behavior. Furthermore, the inherent opacity of these models demands increased attention to explainability, not merely as a regulatory requirement, but as a fundamental necessity for building trust and preventing unforeseen systemic risks. The temptation to optimize for short-term gains, measured by easily quantifiable metrics, must be tempered by a long-term view of model robustness and adaptability.
Ultimately, the challenge lies in recognizing that a financial system is not a static dataset to be modeled, but a complex adaptive system constantly evolving. Good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
Original article: https://arxiv.org/pdf/2602.14233.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Brent Oil Forecast
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- EUR ZAR PREDICTION
- Gold Rate Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
2026-02-17 10:34