Author: Denis Avetisyan
New research explores how to effectively communicate the likelihood of privacy breaches to individuals, empowering them to make more informed decisions about sharing personal information online.
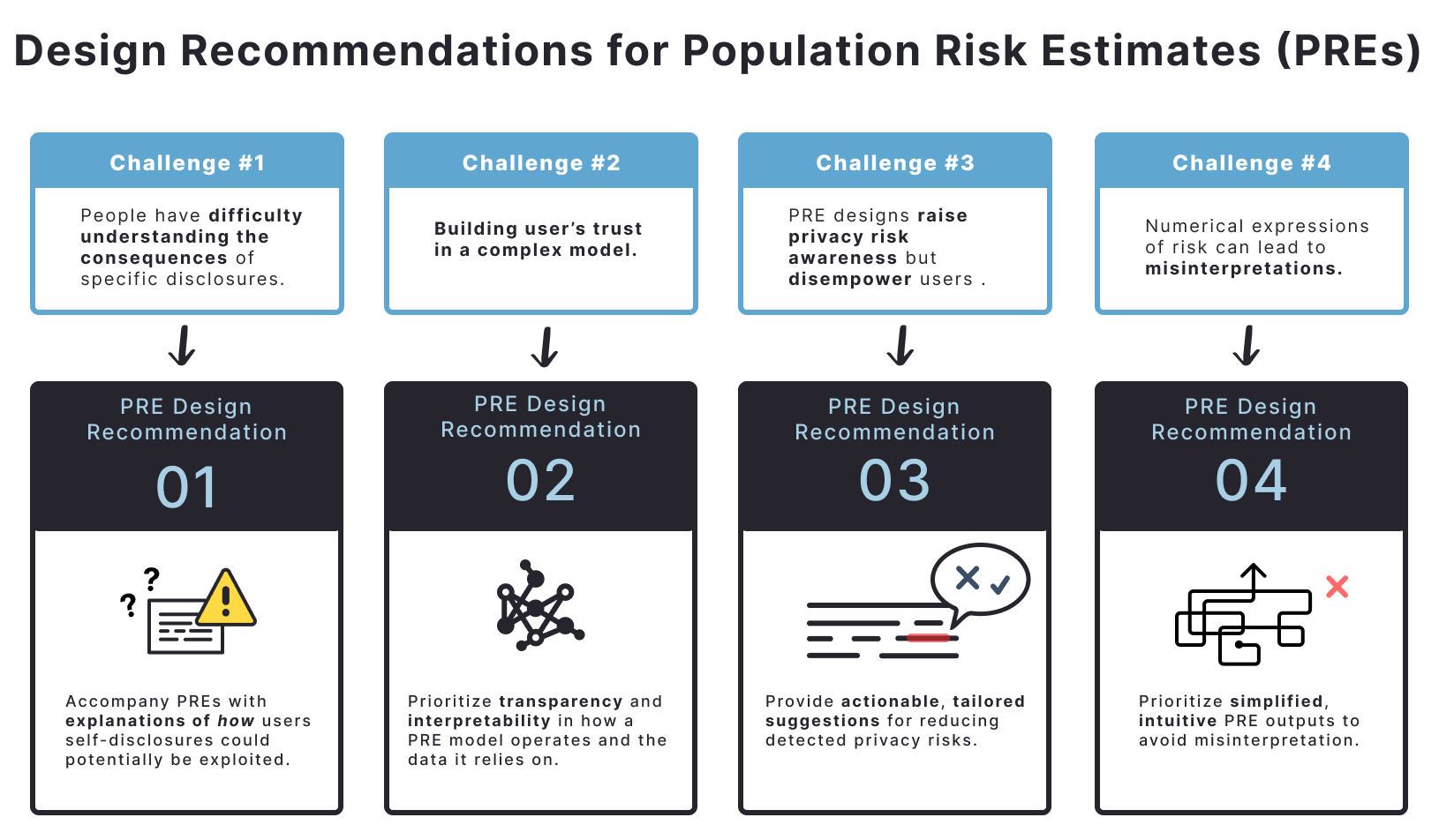
This review synthesizes design recommendations for presenting AI-estimated population risk to improve user privacy awareness and self-disclosure practices.
Despite increasing expectations of online anonymity, individuals often inadvertently disclose sensitive information due to miscalibrated perceptions of privacy risk. This research, titled ‘Supporting Informed Self-Disclosure: Design Recommendations for Presenting AI-Estimates of Privacy Risks to Users’, investigates how to effectively communicate quantified disclosure-based re-identification risks-or population risk estimates-to users. Through design fictions and user studies with \mathcal{N}=44 Reddit users, we identified four key design recommendations for presenting these estimates in a way that promotes informed decision-making without unduly encouraging self-censorship. How can these principles be scaled to build privacy-enhancing tools that truly empower users to navigate the complexities of online self-disclosure?
The Illusion of Control: Privacy in a Hyper-Connected World
The contemporary digital landscape is characterized by a pervasive culture of self-disclosure, as individuals routinely share personal information across a multitude of online platforms. This behavior, often driven by social norms and the desire for connection, frequently occurs with limited awareness of the potential privacy implications. Users may readily provide data – ranging from demographic details and lifestyle preferences to location data and browsing history – in exchange for perceived benefits like personalized content or access to services. However, the aggregation and analysis of this seemingly innocuous data can reveal surprisingly intimate details about an individual’s life, creating vulnerabilities to various harms, including targeted advertising, price discrimination, and even identity theft. This widespread, often uncritical, sharing of personal information represents a significant shift in privacy expectations and necessitates a greater understanding of the risks involved in the digital age.
Early privacy protections, such as K-anonymity, aimed to shield individual identities by ensuring data records were indistinguishable within a group of at least ‘k’ individuals. However, contemporary data landscapes render this approach increasingly ineffective. The pervasive practice of data aggregation – combining datasets from disparate sources – and sophisticated re-identification techniques allow adversaries to pinpoint individuals even within seemingly anonymized groups. Attributes not initially considered identifying, when combined, can uniquely reveal a person’s identity, a process accelerated by machine learning algorithms. This means that while K-anonymity might have offered a degree of privacy in simpler contexts, it provides a false sense of security against modern threats that leverage the power of big data and advanced analytical tools, necessitating more robust and dynamic privacy solutions.
The modern digital landscape presents a curious paradox: while awareness of privacy risks is demonstrably increasing, this knowledge isn’t translating into consistent protective behaviors, fostering a state increasingly described as privacy fatigue. Individuals express concern over data breaches and surveillance, yet continue to engage in online activities that compromise their personal information, often due to convenience, social pressure, or a sense of powerlessness. This disconnect stems from the sheer complexity of managing one’s digital footprint, the constant evolution of privacy policies, and the perceived lack of meaningful control over data collection. Consequently, people become overwhelmed, desensitized, and ultimately disengaged, leading to a resignation where privacy concerns are acknowledged but rarely addressed through proactive measures, creating a vulnerability that data collectors readily exploit.
The ability to make reasoned choices regarding personal data hinges critically on a comprehensive understanding of potential repercussions, yet this understanding often remains elusive for many individuals. Research indicates that users frequently underestimate the scope of data collection and the possibilities for misuse, ranging from targeted advertising to discriminatory practices and even identity theft. This lack of clarity isn’t necessarily due to a lack of intelligence, but rather the inherent complexity of data ecosystems and the often-buried nature of privacy policies. Consequently, even when presented with privacy options, individuals may struggle to assess the true trade-offs between convenience, personalization, and the protection of their sensitive information, leading to choices that don’t fully reflect their preferences or values. Bridging this gap between awareness and informed action is therefore essential for empowering individuals to navigate the digital landscape with greater agency and control.
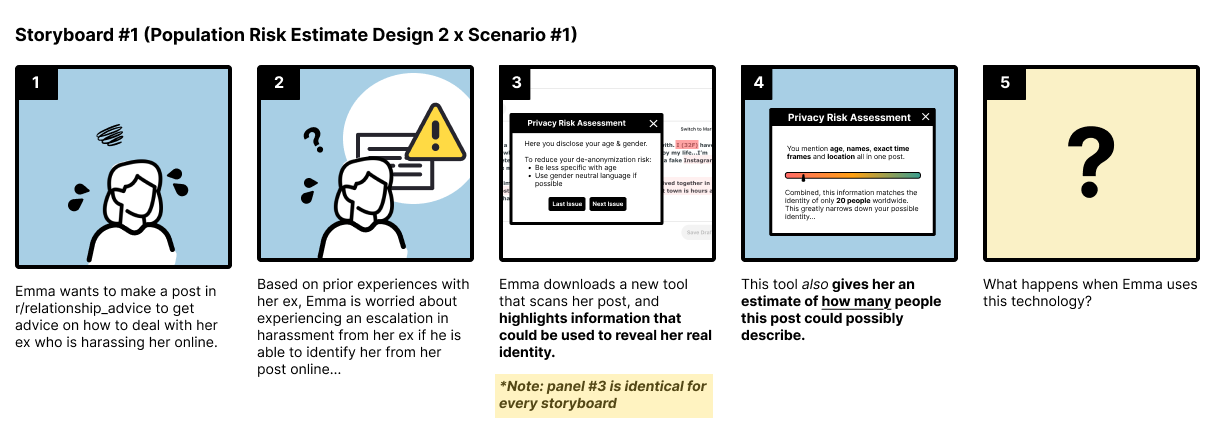
Deconstructing the Shadow: Quantifying Population Risk
PopulationRiskEstimate calculates the probability of re-identification by analyzing shared characteristics – or quasi-identifiers – present within a dataset. This method doesn’t assess the absolute certainty of re-identification, but rather quantifies the risk based on the prevalence of specific attribute combinations. The calculation considers the size of the dataset, the number of individuals sharing those characteristics, and external data sources that could facilitate linking records. A higher Population Risk Estimate indicates a greater likelihood that an individual could be uniquely identified based on the available data, even without directly identifying information. The output is a numerical score representing this likelihood, allowing for comparative risk assessment across different datasets or data subsets.
ExplainableAI (XAI) is a critical component in translating the technical outputs of Population Risk Estimation (PRE) into actionable insights for diverse audiences. The PRE process, while quantitatively assessing re-identification likelihood, generates data that requires interpretation; XAI techniques facilitate this by providing transparent rationales for the estimated risks. This involves not simply presenting a risk score, but detailing which specific characteristics contributed most significantly to that score, and how those characteristics increase vulnerability. For technical users, XAI allows for validation of the PRE model and deeper investigation into potential data privacy issues. Crucially, XAI also enables non-technical stakeholders – such as data subjects, policymakers, or legal counsel – to understand the basis of the risk assessment without requiring specialized expertise, fostering trust and informed decision-making regarding data disclosure and mitigation strategies.
Natural Language Presentation (NLP) of Population Risk Estimates (PREs) significantly improves user understanding and acceptance of re-identification risk assessments. Rather than presenting raw statistical data, NLP translates PREs into easily digestible narratives describing the likelihood of individual disclosure based on shared attributes within a dataset. This approach moves beyond numerical values to articulate why a particular risk exists, detailing the specific characteristics that contribute to potential re-identification. Studies indicate that communicating risks through natural language fosters greater user awareness and encourages proactive mitigation strategies, ultimately increasing trust in the accuracy and relevance of the assessment compared to solely relying on quantitative metrics.
A study of Population Risk Estimates (PREs) demonstrated a positive correlation between risk assessment and user behavior; 74% of simulated outcomes indicated that PREs increased user awareness of potential disclosure risks. Furthermore, 79% of subsequent user reflections resulted in characters successfully mitigating re-identification threats. However, effective utilization of PREs requires careful TrustCalibration; users must accurately interpret the estimated risks to make informed decisions, preventing both undue alarm and insufficient precaution. This calibration is critical for ensuring that risk assessments translate into practical and effective privacy-preserving behaviors.
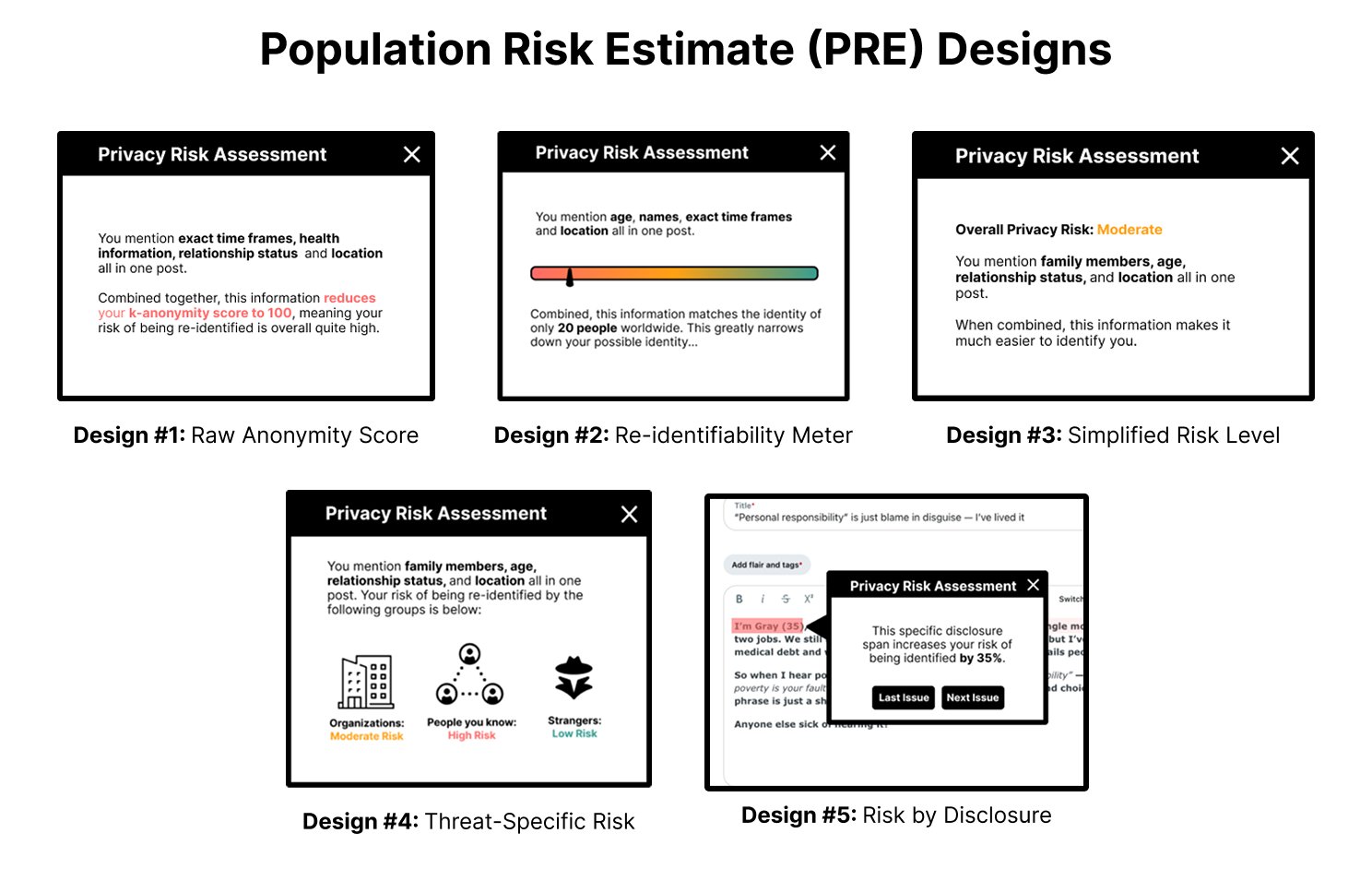
From Awareness to Action: Empowering Users Through Mitigation
Effective risk mitigation strategies are predicated on the delivery of ActionableGuidance, meaning users require precise and readily implementable steps to enhance their privacy. Generalized advice regarding data protection is insufficient; instead, systems should provide concrete instructions such as enabling multi-factor authentication, adjusting specific privacy settings within an application, or utilizing a provided data encryption tool. The effectiveness of these measures is directly correlated to the clarity and specificity of the guidance provided; vague recommendations will likely result in non-adoption or incorrect implementation, thereby failing to adequately address the identified privacy risks. This necessitates a shift from simply informing users about risks to actively guiding them through the process of mitigating those risks with defined actions.
Usability testing is a fundamental component in validating the effectiveness of risk mitigation strategies by directly observing user interaction with proposed protective measures. These tests assess whether users can readily understand the presented risks and, crucially, successfully execute the recommended actions to address them. Metrics gathered during usability testing include task completion rates, error rates, and time-on-task, providing quantifiable data on the ease of implementation. Testing should involve representative users from the target demographic and encompass a range of technical proficiencies to identify potential barriers to adoption. Findings from these tests directly inform iterative design improvements, ensuring that privacy tools are not only technically sound but also accessible and user-friendly, ultimately maximizing their protective value.
ComicBoarding, a usability testing technique, involves presenting users with a sequence of sketched storyboard panels depicting interactions with a privacy tool. Participants are asked to narrate their thought process as they “use” the interface represented by the sketches, providing verbal feedback on clarity, potential roadblocks, and perceived usefulness of the mitigation strategies. This method allows designers to identify usability issues early in the development process, before significant coding has begun, and iteratively refine the tool’s design based on direct user input regarding how they interpret and interact with the proposed privacy features. The technique focuses on understanding the user’s mental model and identifying areas where the interface may cause confusion or friction.
Design friction, representing the effort required to complete a task, directly impacts user adoption of privacy-enhancing technologies. Studies indicate that increased cognitive load or excessive steps in a process correlate with significantly lower completion rates for security measures. Specifically, requiring multiple logins, complex permission settings, or unclear explanations for data requests introduces friction that discourages consistent use. Minimizing this friction necessitates streamlined interfaces, pre-configured optimal settings where possible, and just-in-time educational prompts that contextualize privacy choices within the user’s immediate activity. Addressing design friction is therefore not merely a usability concern, but a critical factor in effectively translating privacy awareness into protective user behavior.
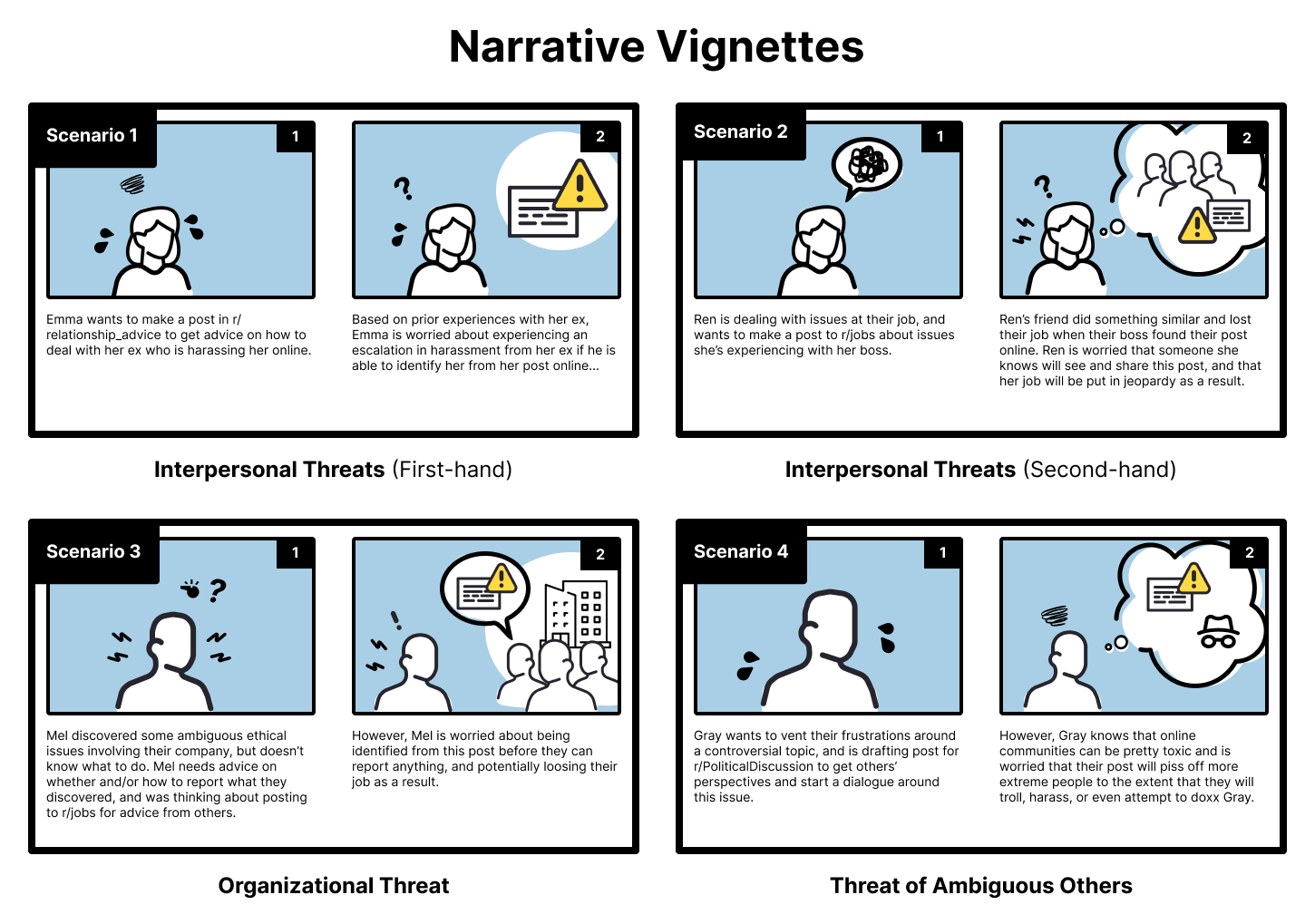
The research meticulously outlines a path toward enhancing user awareness of population risk estimates, essentially probing the boundaries of how information impacts self-disclosure. This mirrors a sentiment echoed by Paul Erdős: “A mathematician knows a lot of things, but he doesn’t know everything.” The study doesn’t propose absolute certainty regarding privacy breaches, but instead focuses on providing users with estimates – acknowledging inherent unknowns. Just as a mathematician continually refines understanding through approximation, this work seeks to refine user perception, not deliver definitive answers. The core concept of presenting probabilities, rather than certainties, embodies a similar spirit of intellectual honesty and iterative understanding, revealing the system’s limitations as much as its strengths.
Beyond the Estimate
The pursuit of presenting population risk estimates reveals, predictably, that the problem isn’t the estimate itself. It’s the assumption of a rational actor receiving it. This work has illuminated design principles for communicating risk, but implicitly acknowledges the far messier reality of human decision-making. Future investigations should abandon the pretense of pure information delivery and embrace the inherent contradictions of self-disclosure. Consider, for example, designs that deliberately introduce calibrated uncertainty – not to obscure, but to mirror the probabilistic nature of digital existence.
The field now faces a choice: refine the signal, or investigate the noise. A more fruitful path may lie in acknowledging that privacy isn’t a calculable quantity, but a negotiated performance. Designs that facilitate playful exploration of risk – perhaps through speculative scenarios or ‘design fiction’ interventions – could prove more effective than striving for objective accuracy. The architecture of privacy isn’t about preventing breaches, but about understanding the shape of the vulnerability itself.
Ultimately, this line of inquiry forces a re-evaluation of “informed consent.” Perhaps the goal isn’t to provide comprehensive risk assessments, but to cultivate a pervasive sense of ambient awareness – a constant, low-level recognition that every digital act leaves a trace, and that control is, at best, an illusion. The challenge isn’t to minimize risk, but to design for resilience in the face of inevitable exposure.
Original article: https://arxiv.org/pdf/2601.20161.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Euphoria Season 3’s New R-Rated Sydney Sweeney Scene Proves The Show Is Trolling Us
- Hideo Kojima says Metal Gear Solid 2 became the future he hoped would not happen
- Dragon Quest II HD-2D Remake: Where to get the Magic Key
- HSR Banner Schedule (Honkai Star Rail)
- Gold Rate Forecast
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- How to Get to the Undercoast in Esoteric Ebb
2026-01-30 04:39