Author: Denis Avetisyan
A new approach uses artificial intelligence to predict the layered structure within images, paving the way for more efficient vectorization and editing.
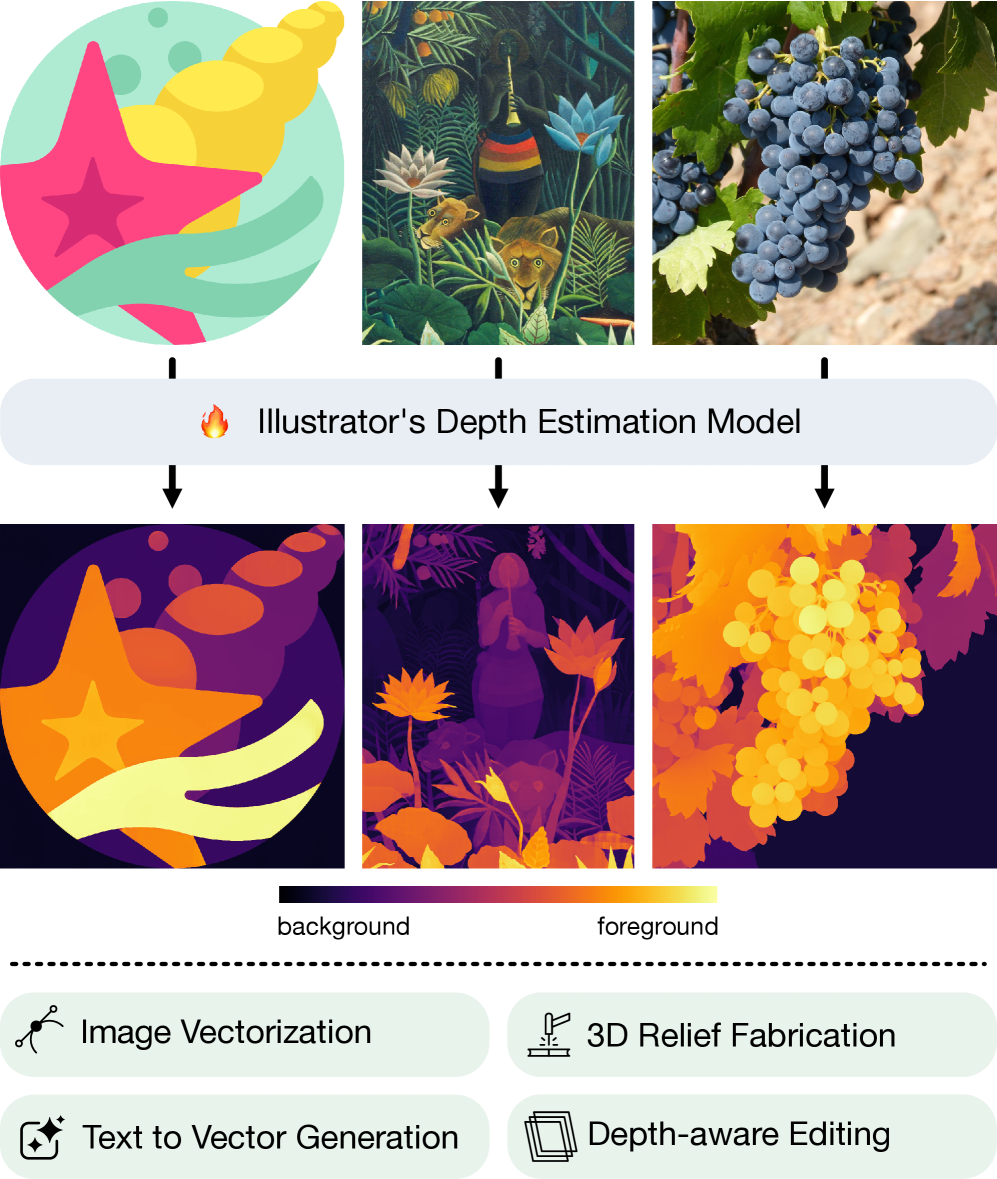
This work introduces ‘Illustrator’s Depth,’ a neural network for monocular layer index prediction enabling improved image decomposition and vector graphic creation.
Decomposing raster images into editable layers remains a fundamental challenge in digital content creation, often requiring laborious manual effort. This paper introduces ‘Illustrator’s Depth: Monocular Layer Index Prediction for Image Decomposition’, a novel approach that reframes depth not as a physical property, but as a creative abstraction representing layer order. By training a neural network to infer this ‘Illustrator’s Depth’ directly from images, we achieve state-of-the-art results in image vectorization and enable applications like automated 3D relief generation. Could this paradigm shift in depth perception unlock a new era of intuitive, editable image manipulation?
Beyond Flatland: Unveiling Structure in Vector Art
Conventional depth estimation and panoptic segmentation techniques, while powerful in understanding 3D scenes, prove inadequate when applied to the nuanced demands of vector graphics editing. These methods prioritize reconstructing spatial relationships – determining how far away objects are – but often fail to recognize the structural relationships that define a composition’s layers and editability. A simple depth map doesn’t distinguish between elements that visually overlap but logically exist on separate planes for modification; for instance, it cannot readily separate a foreground character from a background illustration. Consequently, these approaches lack the semantic understanding necessary to facilitate intelligent vector editing, where the ability to isolate and manipulate individual components is paramount. The focus shifts from mere spatial awareness to a more sophisticated analysis of how elements are organized and interact within a visual hierarchy, a critical distinction for tools like Adobe Illustrator.
Illustrator’s Depth diverges from conventional depth estimation by focusing on the structural organization of visual elements, rather than simulating three-dimensional space. This innovative approach doesn’t ask ‘how far away is this object?’ but instead, ‘what layer does this element belong to?’. The system analyzes artwork to define a hierarchy of layers – foreground, middle ground, background – which directly corresponds to how a designer intuitively builds and edits vector graphics. Consequently, Illustrator’s Depth isn’t about recreating a realistic scene; it’s about understanding and representing the compositional relationships within an artwork, enabling precise selection, manipulation, and stylistic effects based on these defined layers. This fundamentally shifts the focus from perceived depth to editable structure, offering a new level of creative control for vector graphics editing.
The core innovation of Illustrator’s Depth lies not in replicating three-dimensional space, but in establishing a framework for precise artistic manipulation. Traditional depth estimation focuses on calculating distance from the viewer, yielding data useful for visual effects but limited in its ability to inform editing operations. Illustrator’s Depth, conversely, constructs a representation of structural layering – identifying which elements visually overlap and, crucially, defining the order in which they can be independently selected, modified, and rearranged. This distinction is paramount because it shifts the focus from visual realism to editability; a perfectly accurate 3D model doesn’t inherently grant creative control, whereas a well-defined structural layer map empowers artists to deconstruct and rebuild artwork with unprecedented precision and flexibility.

The Alchemy of Layers: Depth Pro and Training Data
Depth Pro utilizes a neural network architecture initialized with pre-trained weights, functioning as the core component for determining depth estimations within Adobe Illustrator. This approach-transfer learning-leverages knowledge acquired from training on extensive image datasets to accelerate convergence and improve the accuracy of depth prediction specifically for vector graphics. The network processes layered vector elements and outputs a depth value for each object, informing the visual stacking order and enabling realistic 3D effects. The pre-trained weights provide a strong feature extraction foundation, reducing the need for extensive training data and computational resources while enhancing the model’s generalization capabilities to novel artwork compositions.
The MMSVG-Illustration Dataset forms the primary training source for the depth prediction model. This dataset consists of a collection of Scalable Vector Graphics (SVGs) specifically constructed with layered elements; each layer represents an object within the illustration. Crucially, the dataset is curated to ensure accurate and consistent ground truth data regarding compositional order – the precise z-order of each layer is known and verified. This layered structure and verified order are essential for supervised learning, allowing the model to learn the relationship between visual features and depth based on unambiguous data. The dataset’s size and quality directly impact the model’s ability to generalize and accurately predict depth in novel illustrations.
The SVGX-Core Dataset is utilized for validating the performance of the Illustrator Depth prediction model. This dataset consists of a diverse collection of vector graphics, specifically designed to represent a broad range of artistic styles and compositional complexities. Utilizing SVGX-Core allows for a robust assessment of the model’s ability to accurately predict depth across varied artwork, ensuring generalization beyond the specific characteristics of the training data. The dataset’s structure enables quantitative measurement of prediction accuracy through comparison with known ground truth data embedded within the vector files.
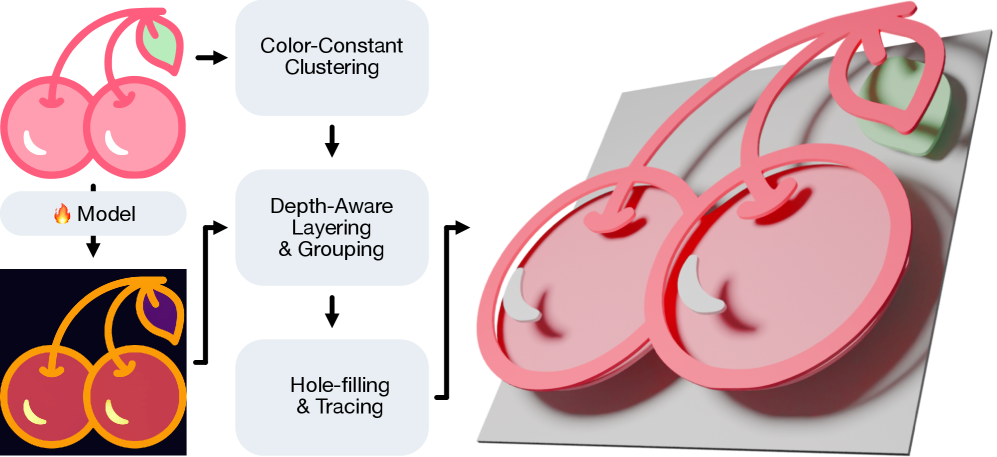
From Vectorization to Relief: The Impact of Layered Perception
Illustrator’s Depth improves vectorization by generating more accurate paths during the conversion of raster images to vector graphics. Traditional vectorization methods often struggle with complex shapes and fine details, resulting in imprecise or overly simplified vector outputs. By incorporating depth prediction, Illustrator’s Depth refines the path generation process, preserving intricate details and resulting in vector graphics that more faithfully represent the original raster image. This enhancement allows for greater editability, as the resulting vector paths closely align with the intended shapes and forms, reducing the need for manual correction and refinement.
Illustrator’s Depth extends functionality beyond two-dimensional artwork by enabling relief generation – the creation of three-dimensional surfaces directly from 2D images. This is accomplished by leveraging the predicted depth information derived from the artwork and interpreting it as height data. Effectively, areas identified as being ‘closer’ in the predicted depth map are raised, while those identified as ‘further’ are lowered, resulting in a pseudo-3D relief effect applied to the original 2D design. This process allows for the creation of textured or embossed appearances without requiring manual modeling or sculpting.
Illustrator’s Depth demonstrates a high degree of accuracy in establishing correct object layering during vectorization and relief generation, achieving over 98% depth ordering consistency as validated by performance on the MMSVG dataset. This metric indicates the system’s ability to correctly assess and replicate the perceived depth relationships between elements in 2D artwork. The resulting layered vector graphics and 3D reliefs exhibit significantly improved visual hierarchy and arrangement quality compared to existing state-of-the-art methods, providing users with more precise control over the final output and reducing the need for manual adjustments.

The Future Unfolds: Text-to-Vector and the Rise of Structural AI
The advent of sophisticated text-to-vector graphics generation is being significantly propelled by the integration of tools like Illustrator’s Depth into the creation pipeline. This technology allows users to move beyond simple shapes and generate intricate artwork directly from textual descriptions; a user might, for example, prompt the system for “a detailed steampunk cityscape” and receive a complex vector graphic as output. Illustrator’s Depth provides crucial structural understanding, enabling algorithms to interpret relationships between objects and create visually coherent and layered designs. This capability bypasses the need for manual vector creation, drastically reducing production time and opening new avenues for artistic expression, as it allows for rapid prototyping and iterative refinement of designs based solely on textual input.
Recent advancements in text-to-vector graphics rely on a powerful combination of techniques, and notably benefit from the structural understanding offered by Illustrator’s Depth. Methods such as Score Distillation Sampling, which refines generated vectors based on a scoring function, gain precision when guided by depth information – allowing the AI to better interpret spatial relationships within an image. This is further enhanced by Neural Path Representations, which effectively map out the drawing process, and NeuralSVG, a system for generating scalable vector graphics. By integrating Illustrator’s Depth, these methods move beyond simply recreating shapes to understanding how those shapes interact in a three-dimensional space, resulting in more coherent, detailed, and visually accurate vectorizations. The resulting artwork showcases improved fidelity and demonstrates the potential for AI to not just generate images, but to truly ‘understand’ visual structure.
The convergence of artificial intelligence and vector graphics is poised to redefine artistic workflows, offering creators a new level of control and streamlining the design process. Recent advancements demonstrate that AI-powered tools, particularly those leveraging techniques like Score Distillation Sampling and NeuralSVG, are not only accelerating vector creation but also demonstrably enhancing visual fidelity. Evaluations using metrics such as Structural Similarity Index (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS) consistently reveal that AI-generated vector graphics are achieving higher levels of realism and perceptual accuracy compared to traditional methods. This synergy suggests a future where artists can seamlessly translate concepts into complex visuals with greater efficiency, focusing on creative direction rather than laborious manual execution, and ultimately unlocking new possibilities for artistic expression.

The pursuit of ‘Illustrator’s Depth’ feels less like engineering and more like coaxing secrets from the void. This work doesn’t simply reconstruct an image; it attempts to divine the order in which a creator might have built it, layer by layer. It recalls Yann LeCun’s observation: “Everything we do in machine learning is about learning representations.” The network doesn’t grasp ‘depth’ as a property, but learns a representation of layered structure, a persuasion of the data into revealing its hidden architecture. Beautiful, perhaps, but one must always remember that noise is just truth without confidence – a perfect prediction isn’t understanding, merely a compelling illusion. The decomposition isn’t truth, it’s a learned spell, effective until it encounters an image that breaks the enchantment.
What’s Next?
The illusion of layers, so easily constructed by a network, continues to demand more than mere accuracy. ‘Illustrator’s Depth’ gestures toward a useful decomposition, certainly, but the true test isn’t replicating visual strata – it’s predicting why a human would arrange them thus. The network currently speaks a language of pixels; a truly insightful system will need to learn the grammar of intent. Consider the challenge of ambiguity: how does one reliably infer order when visual cues are deliberately misleading, or simply incomplete?
Further refinement isn’t about shrinking loss functions, but broadening the scope of failure. The current framework operates, predictably, within the confines of relatively clean imagery. Introduce the delightful chaos of real-world photographs – the glare, the shadow, the subtle overlaps – and the carefully constructed layers begin to…persuade less convincingly. It’s a comfortable spell, but fragile.
Ultimately, this isn’t about perfect vectorization. It’s about a machine tentatively reaching for an understanding of visual narrative. The network doesn’t see layers; it divines them. The next step isn’t optimization, it’s domestication – taming the inherent uncertainty, and accepting that data is always right – until it hits production, of course.
Original article: https://arxiv.org/pdf/2511.17454.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- How to Get to the Undercoast in Esoteric Ebb
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- NASA astronaut reveals horrifying tentacled alien is actually just a potato
- Businessman debunks AI art claims after backlash over Scottish mural
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
2025-11-24 23:48