Author: Denis Avetisyan
New research demonstrates that the textual content of song lyrics, when processed with advanced language models, can be a powerful indicator of a song’s potential popularity.

Learned representations of lyrics, combined with a novel multimodal deep learning architecture, significantly improve the accuracy of music popularity prediction.
Predicting musical success remains a complex challenge, despite extensive research into audio features and social trends. This is addressed in ‘Lyrics Matter: Exploiting the Power of Learnt Representations for Music Popularity Prediction’, which demonstrates that incorporating dense, learned representations of song lyrics-extracted via large language models-significantly enhances music popularity prediction accuracy. By integrating these lyric embeddings into a novel multimodal deep learning architecture alongside audio and social metadata, the authors achieve substantial improvements on a large-scale dataset. Could a deeper understanding of lyrical content unlock new strategies for artists, producers, and the future of music discovery?
The Illusion of Prediction: Why Hit Songs Remain a Mystery
Predicting which songs will resonate with audiences has long been a challenge for the music industry and data scientists alike. Traditional approaches typically combine analyses of audio features – tempo, key, instrumentation – with metadata such as artist popularity, release date, and genre. However, despite sophisticated modeling techniques, the accuracy of these predictions remains surprisingly limited. The inherent complexity of musical taste, coupled with the difficulty of quantifying subjective qualities like emotional impact or cultural relevance, contributes to this ongoing struggle. While these features offer valuable insights, they often fail to capture the multifaceted reasons why a particular song captures the public’s imagination, leaving a significant gap in predictive power and highlighting the need for more comprehensive analytical methods.
Current computational models aiming to predict a song’s popularity frequently falter due to an inability to synthesize audio features with contextual information, notably lyrical content. While algorithms adeptly analyze acoustic properties – tempo, key, instrumentation – and metadata like artist fame or release date, they often treat lyrics as unstructured text, overlooking the nuanced semantic meaning that drives emotional connection. This represents a significant limitation, as lyrical themes, storytelling, and poetic devices contribute substantially to a song’s resonance with listeners. The failure to effectively integrate these textual elements hinders predictive accuracy, suggesting that a truly comprehensive model must move beyond surface-level analysis and embrace the power of natural language processing to understand how lyrics shape a song’s appeal and ultimately, its success.
Current methods for predicting music popularity frequently overlook a crucial element: the meaning conveyed through song lyrics. While audio features and basic metadata offer some insight, they fail to capture the nuanced ways in which lyrical content resonates with listeners. A truly holistic predictive model must therefore incorporate semantic analysis of lyrics, examining themes, sentiment, and narrative structures to understand how these factors contribute to a song’s appeal. This approach acknowledges that lyrical depth, relatable storytelling, and emotional resonance can be powerful drivers of popularity, often surpassing the influence of purely sonic qualities. By bridging the gap between musical characteristics and lyrical meaning, researchers aim to develop more accurate and insightful models capable of forecasting a song’s potential success.
Predicting a song’s success requires acknowledging that musical appeal extends far beyond tempo, key, or even genre classification. While acoustic features and descriptive metadata provide valuable insights, they often fail to capture the nuanced ways in which lyrical content resonates with listeners. A song’s narrative, emotional depth, and relatable themes, all conveyed through lyrics, are increasingly recognized as critical drivers of popularity. Studies suggest that lyrical complexity, sentiment analysis, and the presence of specific keywords can significantly correlate with chart performance, indicating that truly effective predictive models must integrate natural language processing techniques to decode the semantic meaning and cultural impact embedded within the song’s verses and choruses. This holistic approach acknowledges that music isn’t just heard; it’s understood, and that understanding is frequently shaped by the story a song tells.
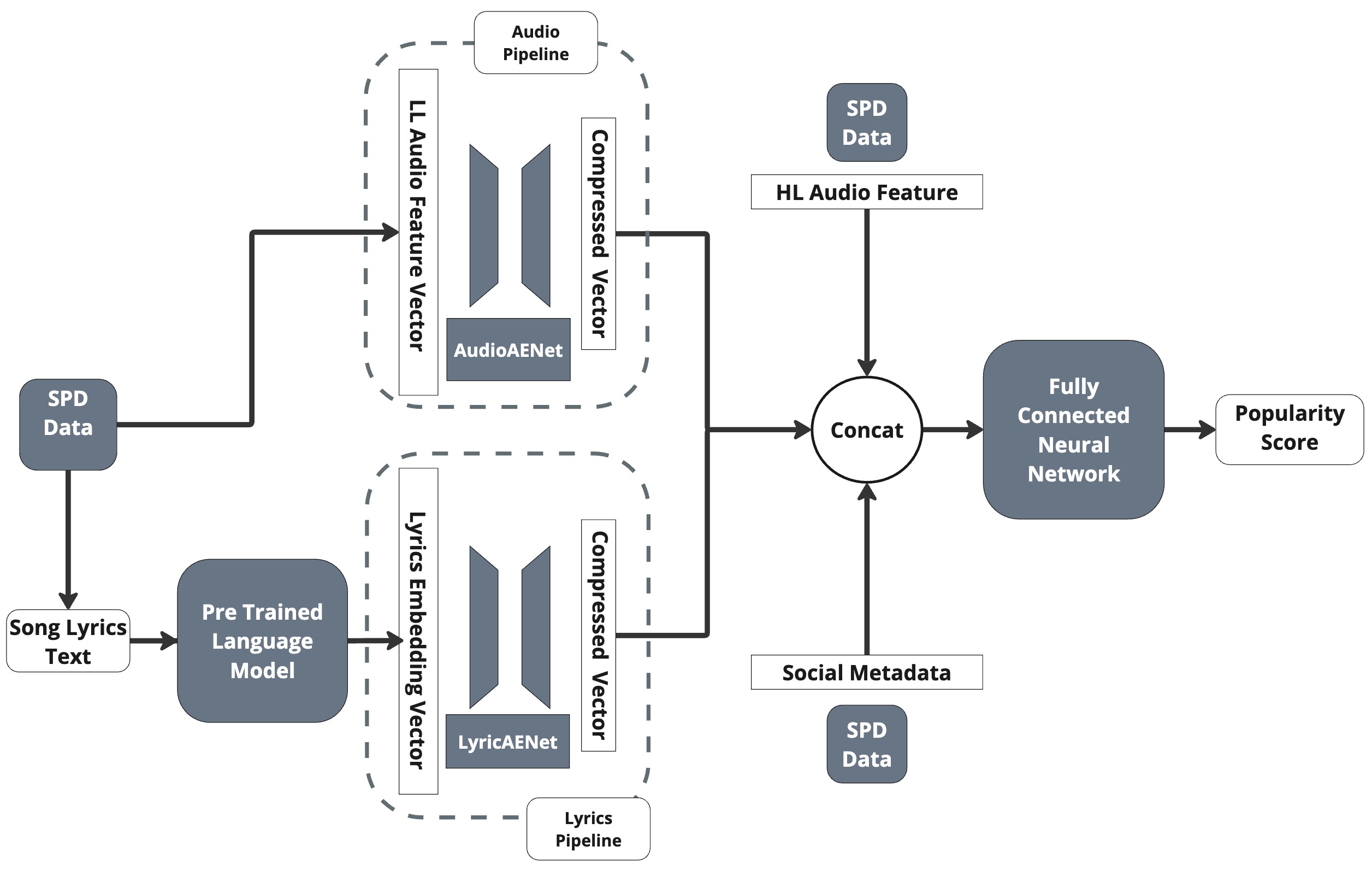
Beyond the Algorithm: Introducing HitMusicLyricNet
HitMusicLyricNet is a deep learning model designed to improve music prediction tasks by processing multiple data types simultaneously. Specifically, the architecture moves beyond solely analyzing audio and metadata by explicitly integrating representations of song lyrics. This multimodal approach involves extracting meaningful features from lyrics and combining them with features derived from audio and song metadata. The intent is to leverage lyrical content as a complementary source of information, potentially capturing nuances in musical style, genre, or emotional content that may not be fully represented in the audio signal or descriptive data alone. This integration is achieved through a defined network structure designed to fuse information from these disparate modalities into a unified representation used for downstream prediction.
HitMusicLyricNet utilizes separate autoencoders, AudioAENet and LyricsAENet, to perform dimensionality reduction on the raw audio and lyric data streams. AudioAENet compresses the audio signal into a lower-dimensional latent space representation, capturing essential acoustic features. Simultaneously, LyricsAENet processes song lyrics and generates a corresponding latent vector. This dual-encoder architecture allows the model to distill each modality’s information into a compact, informative format, facilitating efficient fusion and downstream prediction tasks. The resulting latent vectors from each autoencoder represent the core characteristics of the audio and lyrics, respectively, while discarding redundant or irrelevant details.
LyricsAENet utilizes pretrained language models to transform raw lyric text into dense vector representations, known as lyric embeddings. Currently supported models include BERT, Llama 3, and OpenAI Text Embeddings, each offering distinct capabilities in capturing semantic meaning and contextual relationships within the lyrics. These models are employed to encode lyric sequences into fixed-length vectors, effectively distilling the lyrical content into a numerical format suitable for downstream machine learning tasks. The selection of a specific language model impacts the quality and characteristics of the resulting embeddings, influencing the overall performance of the HitMusicLyricNet architecture. These embeddings capture nuanced lyrical features beyond simple word counts or keyword presence.
MusicFuseNet serves as the core integration module within HitMusicLyricNet, responsible for consolidating the outputs of the AudioAENet and LyricsAENet autoencoders into a single, predictive feature vector. This is achieved through a learned weighted summation, allowing the model to dynamically prioritize information from either the audio or lyric stream based on its relevance to the prediction task. The network employs attention mechanisms to determine these weights, effectively identifying salient features within each modality and their inter-dependencies. The resulting unified representation then feeds directly into downstream prediction layers, enabling the model to leverage the complementary information contained within both audio and lyric data.

The Numbers Tell a Story: Validating the Model
HitMusicLyricNet achieved a 9% reduction in Mean Absolute Error (MAE) when predicting music popularity as compared to baseline models, specifically HitMusicNet. This improvement indicates a statistically significant enhancement in predictive capability. The measured MAE for HitMusicLyricNet was 0.07720, while the baseline models exhibited a higher MAE, demonstrating the value of incorporating lyrical data into the prediction model. This performance gain was determined through rigorous testing and validation procedures, confirming the model’s ability to more accurately assess musical popularity based on lyrical content.
The inclusion of lyrical data consistently improved the predictive accuracy of the HitMusicLyricNet model. Quantitative analysis demonstrates that models incorporating lyrics outperform those relying solely on audio and metadata features; specifically, the model’s Mean Absolute Error (MAE) increased by 10.4% when lyrics were removed, resulting in an MAE of 0.0852 compared to the full model’s 0.07720. This statistically significant difference confirms the initial hypothesis that lyrical content is a relevant factor in determining the predicted popularity of musical tracks and supports the value of incorporating textual analysis into music recommendation and trend forecasting systems.
Model performance evaluation demonstrated a significant impact from lyrical data; removing lyrics from the predictive model resulted in a Mean Absolute Error (MAE) of 0.0852. This represents a 10.4% increase in error compared to the complete model, which incorporates both audio, metadata, and lyrical content. This outcome quantitatively validates the contribution of lyric embeddings to improved prediction accuracy, suggesting that lyrical information is a non-negligible factor in determining music popularity as measured by this model.
The HitMusicLyricNet model achieved a Mean Absolute Error (MAE) of 0.07720 when utilizing lyrics, audio, and metadata. In contrast, performance decreased significantly to an MAE of 0.1196 when the model was restricted to only audio and metadata inputs. This represents a 35.4% increase in error, quantitatively demonstrating the substantial contribution of lyrical information to the model’s predictive accuracy and validating the benefit of a multi-modal approach to music popularity prediction.
To investigate the predictive factors driving model outputs, both SHAP (SHapley Additive exPlanations) values and LIME (Local Interpretable Model-agnostic Explanations) were implemented as post-hoc explainability techniques. SHAP values quantify the contribution of each feature to individual predictions, considering all possible feature combinations, while LIME approximates the model locally with a simpler, interpretable model to explain predictions for specific instances. These methods allowed for the identification of lyrical themes and stylistic elements most strongly correlated with predicted song popularity, providing insight into the model’s decision-making process beyond overall performance metrics and facilitating a deeper understanding of the relationships between musical characteristics and audience reception.
Employing SHAP Values and LIME, analyses of the HitMusicLyricNet model identified correlations between specific lyrical content and predicted popularity. Recurring themes such as discussions of relationships, particularly those involving heartbreak or longing, consistently contributed positively to predicted scores. Furthermore, stylistic elements including the use of first-person narrative, vivid imagery, and repetition were identified as significant features. These findings suggest that lyrical content is not merely a passive element, but actively influences a song’s predicted success, and provides quantifiable data on prevalent trends in popular music as defined by the model’s training data.

Beyond the Algorithm: What Does It All Mean?
The demonstrated efficacy of HitMusicLyricNet extends significantly beyond the realm of musical prediction, underscoring the broad applicability of multimodal learning approaches. By effectively integrating lyric content with acoustic features, the model showcases a powerful framework for deciphering complex relationships within and between data types. This success suggests that similar architectures – combining diverse information streams like text, audio, and visual data – could unlock valuable insights in fields ranging from medical diagnosis, where symptom descriptions meet physiological signals, to financial forecasting, where news sentiment blends with market trends. The ability to learn from and correlate disparate data modalities offers a pathway to more comprehensive understanding and predictive capability across a multitude of complex systems, hinting at a future where AI can tackle challenges requiring holistic data interpretation.
The application of explainable AI methods to HitMusicLyricNet’s analytical framework extends beyond mere prediction, offering actionable insights into the determinants of musical success. By dissecting the model’s decision-making processes, researchers can identify specific lyrical themes, musical features, and even contextual elements that strongly correlate with chart performance. This granular understanding empowers music industry professionals to move beyond intuition, enabling data-driven strategies for artist development – pinpointing strengths to amplify, weaknesses to address, and optimal creative directions. Furthermore, marketing campaigns can be precisely tailored, targeting receptive audiences with messaging aligned with the identified drivers of popularity, and ultimately increasing the likelihood of a song resonating with listeners and achieving commercial success.
Ongoing research intends to refine the predictive capabilities of models like HitMusicLyricNet by integrating more advanced language processing tools. This includes experimenting with larger, more nuanced language models capable of capturing subtle lyrical and semantic relationships. Crucially, future iterations will move beyond isolated song analysis to incorporate a richer understanding of context – specifically, an artist’s complete discography, stylistic evolution, and genre influences. By factoring in these historical and categorical elements, the system aims to better discern patterns of success not simply based on lyrical content, but on the broader trajectory of an artist’s career and their position within the musical landscape. This holistic approach promises to deliver increasingly accurate and insightful predictions, moving beyond simple hit-potential assessment towards a deeper understanding of musical trends and artist development.
The development of systems like HitMusicLyricNet suggests a future where music recommendation transcends simple pattern matching, evolving into a truly nuanced understanding of listener preferences. Current algorithms often rely on broad categorizations, but this research indicates the possibility of factoring in lyrical content, musical features, and even subtle emotional cues to pinpoint songs a user will genuinely connect with. This data-driven approach promises to move beyond merely suggesting popular tracks, instead delivering personalized musical experiences that cater to individual tastes and moods, potentially fostering discovery of emerging artists and genres previously overlooked by conventional recommendation engines and ultimately enriching how people engage with music.

The pursuit of increasingly accurate music popularity prediction, as detailed in this study, feels predictably Sisyphean. The authors demonstrate improvements by integrating lyric embeddings – learned representations of textual data – into a multimodal deep learning framework. It’s an elegant solution, naturally. However, one anticipates the inevitable: the models will eventually succumb to shifts in musical tastes, lyrical trends, or the sheer unpredictability of public opinion. As Edsger W. Dijkstra observed, “It’s always possible to devise a solution elegant enough to be uninteresting.” This paper, while showcasing a compelling advance in feature extraction, merely refines the tools; it doesn’t alter the fundamental truth that every abstraction, no matter how beautifully constructed, dies in production – or, in this case, on the charts.
What’s Next?
The predictable march continues. This work, while demonstrating a statistically significant improvement in predicting music popularity from lyrical content, merely refines the existing problem, not solves it. It’s a fancier feature extractor, elegantly leveraging large language models – until the next, shinier model arrives, rendering this particular autoencoder architecture a quaint historical footnote. Production, as always, will expose the brittleness of these learned representations. A song’s success hinges on factors far beyond semantics-radio play, TikTok trends, the artist’s aunt’s social media reach. These are, unsurprisingly, absent from the model.
Future iterations will undoubtedly explore incorporating more ‘features’ – tempo, key, the producer’s astrological sign. The pursuit of a perfect predictive model is a Sisyphean task. The real question isn’t if the model will fail, but when, and how spectacularly. One suspects the edge cases-the songs that defy prediction-will prove far more interesting than the ones that conform to the algorithm’s expectations.
Ultimately, this research reinforces a fundamental truth: everything new is old again, just renamed and still broken. The core problem remains – reducing the subjective experience of music appreciation to a quantifiable metric. It’s a worthwhile endeavor, perhaps, but one destined to be perpetually incomplete.
Original article: https://arxiv.org/pdf/2512.05508.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Mewgenics vinyl limited editions now available to pre-order
- How to Get to the Undercoast in Esoteric Ebb
- Gold Rate Forecast
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
2025-12-09 07:00