Author: Denis Avetisyan
New research suggests that the unique processing style of spiking neural networks provides inherent resistance to data reconstruction attacks in federated learning scenarios.

Spiking Neural Networks demonstrate significantly improved privacy against gradient inversion attacks compared to conventional Artificial Neural Networks due to their event-based, temporal dynamics.
Despite the increasing prevalence of federated learning for on-device intelligence, a critical vulnerability remains: the potential for reconstructing sensitive training data from shared model updates. This work, ‘Privacy in Federated Learning with Spiking Neural Networks’, investigates this privacy threat in the emerging field of neuromorphic computing, specifically exploring the resilience of spiking neural networks (SNNs) to gradient inversion attacks. Our empirical study reveals that SNNs, trained with surrogate gradients, exhibit substantially reduced gradient informativeness compared to conventional artificial neural networks, yielding noisy reconstructions that fail to capture meaningful data structure. These findings suggest that the unique event-driven dynamics and training methodologies of SNNs offer an inherent degree of privacy preservation – but how can these benefits be further maximized and integrated into robust federated learning frameworks?
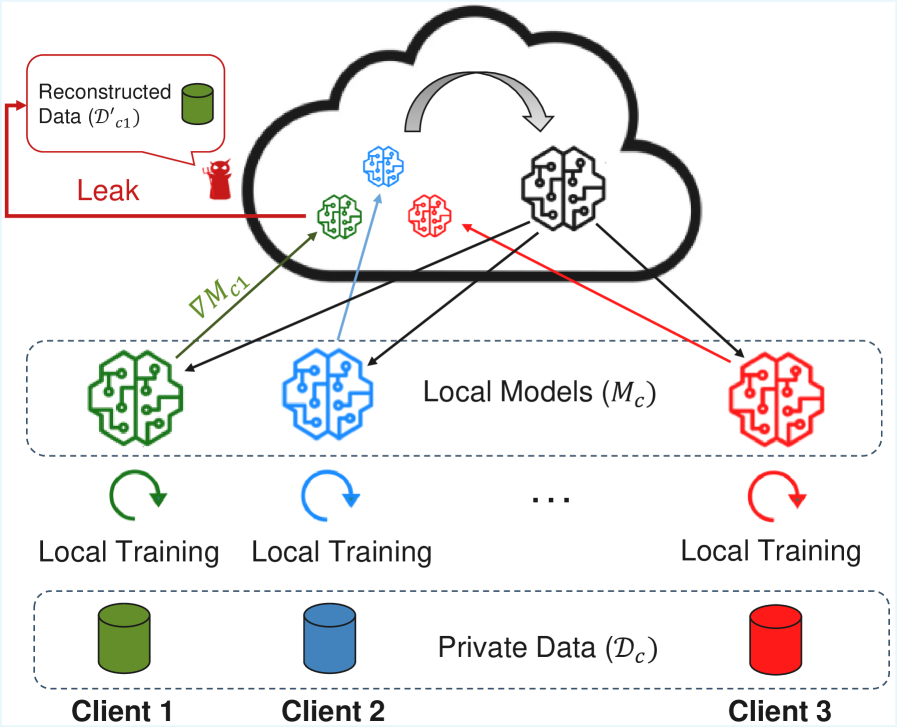
The Inevitable Leak: When Collaboration Breeds Vulnerability
Contemporary machine learning frequently employs a distributed training paradigm, where multiple parties collaborate to build a shared model. This process necessitates the exchange of model updates, specifically gradients, which detail how the model’s parameters should be adjusted to improve performance. While efficient, this collaborative approach introduces a significant privacy vulnerability; the very act of sharing these gradients can inadvertently leak information about the private data used to train the model. Because these gradients aren’t simply abstract mathematical adjustments, but rather encode traces of the data that influenced them, malicious actors can potentially reconstruct or infer sensitive details about the original training dataset. This poses a considerable risk, particularly in applications dealing with confidential information such as healthcare records, financial data, or personal identifiers, and highlights the need for robust privacy-preserving techniques in distributed machine learning.
The collaborative nature of modern machine learning, while enabling powerful models, introduces a significant privacy risk through a phenomenon called gradient leakage. When models are trained using distributed systems, only updates to the model’s parameters – the gradients – are typically shared, not the original training data itself. However, research demonstrates that these gradients inadvertently encode information about the private data used during training. Malicious actors can exploit this by analyzing the shared gradients to reconstruct, or at least infer, sensitive details about the original training dataset, potentially revealing personal information or proprietary data. This reconstruction isn’t a perfect copy, but even partial inference can compromise privacy and intellectual property, highlighting the need for robust privacy-preserving techniques in collaborative machine learning environments.
The very mechanism enabling collaborative machine learning – the sharing of gradients – inadvertently creates a privacy risk because these gradients aren’t simply instructions for model improvement; they are echoes of the training data itself. Each gradient represents the model’s response to a specific data point, and this response, while optimizing performance, also encodes characteristics of that data. Essentially, the model’s adjustments – the gradients – reveal information about the data that caused those adjustments. This isn’t a direct reproduction of the data, but rather a statistical fingerprint, allowing an attacker to reconstruct, with varying degrees of accuracy, sensitive details about the original training set through sophisticated inference techniques. The extent of this “gradient leakage” depends on factors like the model’s complexity, the training process, and the attacker’s capabilities, but the fundamental principle remains: model updates inherently carry data-related information.
Unmasking the Data: How Gradients Reveal Secrets
Gradient Inversion Attacks are a specific type of data extraction attack targeting machine learning models. These attacks function by exploiting the gradients – values indicating the direction of steepest ascent of a loss function – shared during Federated Learning or other distributed training paradigms. By analyzing these shared gradients, an attacker aims to reconstruct the original training data used to build the model. The core principle relies on iteratively adjusting a synthetic data sample to minimize the difference between its calculated gradient and the observed shared gradient, effectively ‘inverting’ the forward pass of the training process to reveal information about the private training set. The reconstructed samples are not necessarily identical to the original data, but can contain significant features allowing for identification or inference of sensitive information.
Gradient inversion attacks function by utilizing optimization algorithms to create synthetic data points that yield gradients – the values indicating the direction of steepest ascent of a loss function – closely matching those observed during the training of a machine learning model. Specifically, an attacker aims to minimize the difference between the gradients calculated on the synthetic data and the gradients shared by the model during training, often employing gradient descent or similar iterative methods. This process effectively reverses the typical training procedure, where data is used to compute gradients; instead, gradients are used to reconstruct an approximation of the original data. The reconstructed data is not necessarily identical to any single training example but represents a plausible sample that would have resulted in a similar gradient calculation, potentially revealing sensitive information about the training dataset.
Gradient inversion attacks are not constrained by data simplicity; successful reconstructions have been demonstrated with complex data types including images, audio, and natural language text. Research indicates that attacks targeting image data have achieved high fidelity reconstructions, while similar attacks on audio data have enabled the recovery of intelligible speech samples. Furthermore, advancements in large language models have shown that gradients from text-based training can be inverted to partially reconstruct sensitive training phrases. This broad applicability stems from the fundamental principle of these attacks – exploiting the relationship between data and the gradients used for model optimization – which remains consistent regardless of the data modality. Consequently, the threat extends beyond traditional image classification scenarios to encompass a wide range of machine learning applications.
Testing the Limits: Datasets and Attack Performance
Gradient Inversion Attacks have been successfully implemented against a range of image datasets, establishing the broad applicability of this privacy vulnerability. Initial demonstrations utilized the MNIST dataset, consisting of 70,000 grayscale images of handwritten digits, to validate the attack methodology. Subsequent research expanded to more complex datasets, including CIFAR-100 – a dataset of 60,000 32×32 color images categorized into 100 classes – and large-scale facial recognition datasets such as LFW, containing over 13,000 images of faces. These successful attacks across diverse datasets confirm that gradient information can be leveraged to reconstruct approximations of training data, raising concerns about the privacy of models trained on sensitive information.
Gradient Inversion Attacks are not limited to simple datasets; their efficacy extends to more complex image classifications. Datasets such as CIFAR-100, comprising 100 distinct image classes, have demonstrated vulnerability, indicating the attacks’ ability to function with increased data dimensionality and feature complexity. Furthermore, facial recognition datasets like LFW (Labeled Faces in the Wild) are also susceptible, suggesting the vulnerability isn’t limited to object recognition but extends to biometric data. This broader applicability demonstrates that the underlying gradient leakage is a systemic issue, impacting various machine learning applications beyond basic image classification tasks.
Event-based datasets, such as DVS128 Gesture, have been shown to be vulnerable to gradient inversion attacks, indicating the broad applicability of this privacy threat beyond traditional frame-based image data. However, our research demonstrates that Spiking Neural Networks (SNNs) exhibit significantly improved resilience against these attacks compared to Artificial Neural Networks (ANNs). Across multiple datasets, including DVS128 Gesture, CIFAR-100, and LFW, SNNs achieve an approximate 49% reduction in Attack Success Rate (ASR). This indicates a substantial decrease in the ability to reconstruct sensitive input data from gradient information when using SNNs, suggesting their potential as a more privacy-preserving neural network architecture.
Analysis of the DVS128 Gesture dataset reveals a limited capacity for successful gradient inversion attacks. Following optimization and thresholding, the reconstructed images exhibit a high $ℓ_2$ distance, ranging from approximately 70 to 85, which indicates significant degradation in reconstruction quality. Correspondingly, the Attack Success Rate (ASR) on this dataset is limited to ≤ 10%. This performance is comparable to random guessing, with a baseline success rate of 9% given the 11 gesture classes within the dataset, suggesting minimal information leakage via gradient inversion on event-based data.

Beyond Band-Aids: Designing for Privacy from the Start
The increasing sophistication of machine learning models brings with it a growing vulnerability to attacks that compromise the privacy of training data. Specifically, Gradient Inversion Attacks demonstrate a concerning ability to reconstruct sensitive information – such as images or personal details – simply by analyzing the gradients released during the model training process. This threat necessitates a fundamental shift in how machine learning systems are developed, moving away from reactive security measures and towards Privacy-Preserving-by-Design principles. This proactive approach emphasizes building inherent privacy protections directly into the system’s architecture, rather than attempting to bolt them on as an afterthought. By prioritizing privacy from the outset, developers can significantly reduce the attack surface and mitigate the risk of data reconstruction, fostering greater trust and responsible innovation in the field.
A fundamental shift in machine learning security prioritizes building privacy directly into system design, rather than attempting to retrofit protections later. This “Privacy-by-Design” approach recognizes that adding security as an afterthought often proves insufficient against increasingly sophisticated attacks, such as gradient inversion. By proactively incorporating privacy-enhancing technologies and principles from the outset – considering data handling, model architecture, and training procedures – systems can inherently limit the potential for sensitive information leakage. This preventative strategy aims to minimize the attack surface and create more resilient models, fostering user trust and responsible AI development by ensuring privacy is not an added feature, but a core characteristic of the system.
Mitigating the escalating threat of data reconstruction attacks demands a fundamental shift towards privacy-preserving system design. Rather than retrofitting security measures, proactive techniques like differential privacy and secure multi-party computation offer inherent safeguards by introducing controlled noise or distributing computations. Recent investigations highlight the potential of Spiking Neural Networks (SNNs) as a particularly effective architectural choice in this regard; results demonstrate a substantial reduction in the Attack Success Rate (ASR) – approximately 49% – when compared to conventional Artificial Neural Networks (ANNs). This significant decrease suggests that SNNs, with their event-driven and sparse computations, present a promising pathway towards building machine learning systems that are both powerful and demonstrably more resilient to privacy breaches, offering a vital step towards responsible AI development.
The pursuit of novel architectures often overlooks a fundamental truth: complexity breeds vulnerability. This research into Spiking Neural Networks and their resilience against gradient inversion attacks exemplifies this principle. While conventional Artificial Neural Networks readily leak information through shared gradients, the discrete, event-driven nature of SNNs introduces a natural obfuscation. It’s a temporary reprieve, of course. As the authors demonstrate improved privacy, one anticipates production environments will devise methods to circumvent these defenses. As Linus Torvalds once stated, “Most developers think they’re building features. They’re really building tech debt.” The elegance of privacy-preserving computation will, inevitably, encounter the brute force of real-world exploitation.
What’s Next?
The observation that Spiking Neural Networks present a somewhat elevated bar for gradient inversion attacks is, predictably, not a final solution. It merely shifts the battlefield. Anyone celebrating inherent privacy is operating under the delusion that obscurity equals security. The discrete nature of events, the temporal dynamics… these are complexities production systems will inevitably find ways to exploit, or sidestep with efficient approximations. The real question isn’t whether these defenses can be broken, but how long it will take and what novel attack vector will emerge.
Further work will undoubtedly focus on quantifying this increased resilience. Benchmarking against increasingly sophisticated attacks is a given. But the more interesting challenge lies in understanding why these attacks are harder, not just that they are. Is it merely the noise introduced by surrogate gradients? Or is there something fundamentally different about the information leakage in event-based computation? Expect a flurry of papers attempting to formalize this ‘privacy by obscurity’, and a corresponding surge in adversarial examples specifically tailored to exploit the peculiarities of SNNs.
Ultimately, the field will circle back to the usual suspects: differential privacy, homomorphic encryption, secure multi-party computation. These are the tools that address the root problem – data exposure – rather than attempting to hide behind architectural quirks. If a bug is reproducible, the system is stable; if data reconstruction is possible, privacy has failed. Anything self-healing just hasn’t broken yet.
Original article: https://arxiv.org/pdf/2511.21181.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- How to Get to the Undercoast in Esoteric Ebb
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- NASA astronaut reveals horrifying tentacled alien is actually just a potato
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
- Does Mark survive Invincible vs Conquest 2? Comics reveal fate after S4E5
2025-11-30 02:35