Author: Denis Avetisyan
A new framework leverages the power of large language models and real-time data to rapidly assess property damage after flooding events.
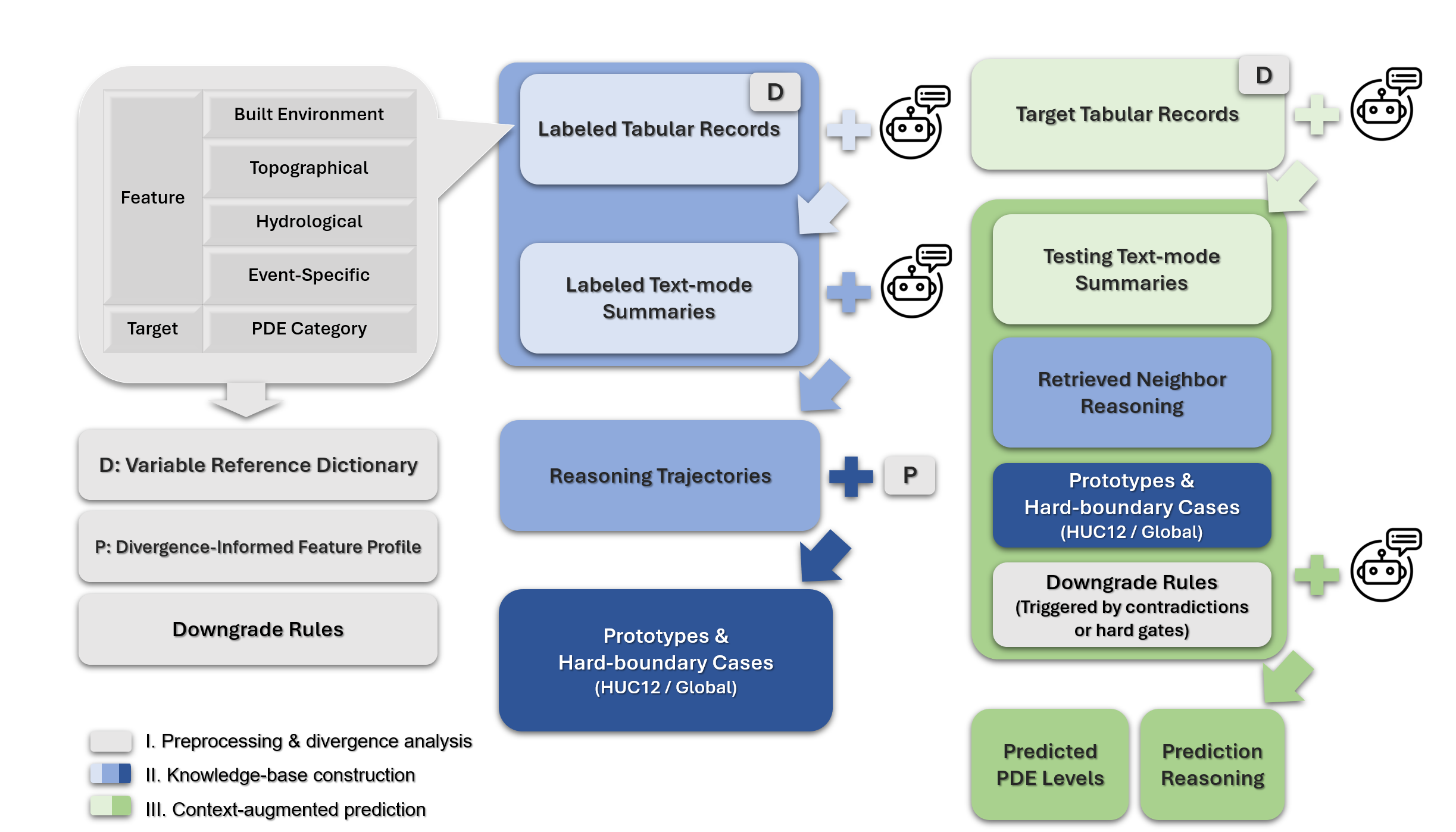
R2RAG-Flood is a training-free retrieval-augmented generation framework that improves post-storm property damage extent nowcasting by integrating reasoning and a knowledge base.
Accurate and timely post-storm damage assessment remains a critical challenge despite advances in predictive modeling. This is addressed in ‘R2RAG-Flood: A reasoning-reinforced training-free retrieval augmentation generation framework for flood damage nowcasting’, which introduces a novel approach leveraging large language models and a reasoning-centric knowledge base to improve property damage extent nowcasting without task-specific training. By retrieving and adapting prior reasoning from geospatial neighbors and canonical examples, R2RAG-Flood achieves competitive accuracy while providing interpretable rationales for each prediction-and demonstrates substantial efficiency gains over traditional supervised methods. Could this training-free framework represent a scalable solution for rapid damage assessment in the face of increasing climate-related disasters?
The Imperative of Accurate Flood Damage Assessment
Effective disaster response hinges on swiftly determining the scope of property damage following a flood, a process known as Property Damage Extent (PDE) nowcasting. However, current techniques often fall short when confronted with the intricacies of real-world flood events. Traditional methods, frequently reliant on manual assessments or limited aerial imagery, struggle to capture the full spatial extent of damage, particularly in areas with complex terrain or obscured views. This is further compounded by the sheer speed with which floodwaters can rise and recede, overwhelming the capacity for timely data collection and analysis. Consequently, emergency responders often operate with incomplete information, hindering their ability to prioritize resources and deliver aid to the most affected communities. The demand for rapid, accurate PDE nowcasting is therefore paramount, but necessitates a departure from conventional approaches that prove inadequate in the face of complex, dynamic flood scenarios.
Current methods for assessing property damage following floods frequently depend on training datasets meticulously compiled for specific locations or types of inundation. This reliance presents a significant limitation, as models developed for, say, riverine flooding in one region often perform poorly when applied to coastal storm surges elsewhere, or even to different river systems. The specificity of these training datasets hinders the development of broadly applicable damage assessment tools; a model expertly calibrated for damage patterns in one city may struggle to accurately interpret the same damage in a different geographic or climatic context. Consequently, disaster response teams often face the challenge of needing to create entirely new, localized datasets after each unique flooding event, a process that is both time-consuming and resource-intensive, ultimately slowing down effective aid delivery and recovery efforts.
Given the escalating frequency and unpredictable nature of flood events linked to climate volatility, the capacity to rapidly determine the extent of property damage – a process known as Property Damage Extent (PDE) nowcasting – is becoming increasingly vital. Current PDE methods often demand substantial, highly specific training datasets, hindering their adaptability to previously unseen regions or novel flood scenarios. This limitation poses a significant challenge as climate change introduces increasingly complex and varied flooding patterns. Therefore, a shift toward data-efficient approaches is paramount; techniques capable of generating accurate damage assessments with minimal reliance on extensive, localized training data will be crucial for effective disaster response and resource allocation in an era defined by heightened climatic instability.
R2RAG-Flood: A Framework Founded on First Principles
R2RAG-Flood distinguishes itself from traditional flood damage assessment systems by eliminating the requirement for dedicated, task-specific training datasets. This is achieved through the utilization of pre-trained large language models (LLMs) – termed “LLM Backbones” – which possess inherent capabilities in natural language understanding and generation. Rather than retraining these models for the specific task of flood damage analysis, R2RAG-Flood employs a robust retrieval mechanism to supply the LLM with relevant contextual information. This information, sourced from external datasets, is used by the LLM to formulate responses and assess damage, effectively adapting a general-purpose model to a specialized application without the computational expense and data requirements of fine-tuning.
The R2RAG-Flood framework employs a Variable Reference Dictionary to standardize the interpretation of predictor data inputs. This dictionary dynamically adjusts data representations based on contextual variables, specifically hydrological characteristics within each HUC12 Watershed Group. By mapping diverse data sources to a consistent internal format, the dictionary mitigates ambiguity and ensures that the same input values are interpreted identically across different analyses and time periods. This standardization is critical for achieving reliable and reproducible results, as it minimizes the potential for errors arising from inconsistent data handling and allows for accurate comparisons of damage assessments across varying geographical locations and environmental conditions.
R2RAG-Flood establishes localized contextual understanding by employing a Neighbor Retrieval process within HUC12 Watershed Groups. This method identifies geographically proximate watersheds exhibiting similar hydrological characteristics – including factors such as land cover, slope, and soil type – to serve as analogs for damage assessment. By retrieving data from these neighboring watersheds, the framework accounts for localized variations in flood response and damage patterns that would be missed by broader, less granular analyses. This approach allows for a more nuanced evaluation of damage, factoring in hydrological features specific to the impacted area and improving the accuracy of predictions compared to models relying solely on global datasets or generalized assumptions.
Strategic Example Selection: Augmenting Intelligence
R2RAG-Flood utilizes a technique called Free-Shots to improve the relevance of retrieved information for the Large Language Model (LLM). This involves supplementing the standard retrieval process with specifically curated examples. These examples consist of both representative cases, illustrating typical input-output relationships, and hard-boundary cases, which define the limits of the predictor’s applicability. By explicitly presenting the LLM with these critical scenarios, R2RAG-Flood aims to focus the model’s attention on the most informative data points, thereby enhancing prediction accuracy and robustness, particularly in edge cases or when encountering out-of-distribution inputs.
Feature Distribution Divergence Analysis is employed to assess the dissimilarity between the distributions of predictor outputs for different input samples. This quantification utilizes metrics to measure the separation – or divergence – of these distributions, providing a numerical value indicating the degree of difference in predicted outcomes. A higher divergence score signals greater discrepancy and identifies instances where the model’s predictions are most uncertain or varied. These high-divergence cases then inform two key processes: the selection of informative “Free-Shot” examples for retrieval-augmented generation, and the targeted generation of natural language descriptions from tabular data to improve LLM interpretability and focus on critical scenarios.
Text-Mode Generation addresses the challenge of presenting structured, tabular data to Large Language Models (LLMs). LLMs are fundamentally designed to process natural language; directly inputting tabular data requires the model to infer relationships and meaning from numerical and categorical values. This conversion process translates the data into descriptive, natural language sentences, effectively pre-interpreting the information for the LLM. For example, a table row representing a patient’s health data might be converted into a sentence like “Patient age is 62, blood pressure is 140/90, and cholesterol level is 220.” This facilitates more accurate and efficient analysis, as the LLM receives information in a format aligned with its training and capabilities, reducing the need for complex in-context learning or prompting strategies.
Refining Predictions: Validation and Practical Impact
The system incorporates a Downgrade Check, a rule-based post-processing step designed to enhance the reliability of its predictions. This check functions by systematically identifying and resolving internal inconsistencies within the initial output, effectively prioritizing evidence and mitigating conflicting signals. Rather than simply accepting the initial prediction, the Downgrade Check scrutinizes the reasoning behind it, downgrading or revising conclusions when presented with contradictory information. This refinement process ensures a more coherent and logically sound final assessment, improving the overall trustworthiness of the flood risk analysis and bolstering the system’s ability to deliver consistent, dependable results even in complex scenarios.
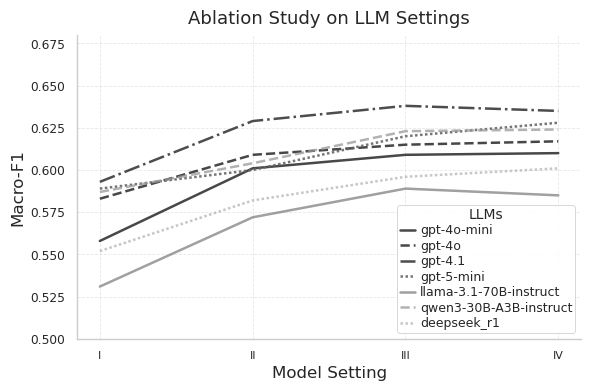
R2RAG-Flood distinguishes itself through a notable capacity for generalization, exhibiting robust performance across a variety of flood events without requiring specialized training for each scenario. This adaptability is reflected in its achieved metrics: a Macro-F1 score of 0.668 when paired with the gpt-4.1 model, and an even more impressive Damage-Class Accuracy of 0.867 utilizing gpt-5-mini. These results demonstrate the system’s ability to accurately identify and categorize flood-related damage, even when presented with previously unseen conditions, highlighting a significant step towards a universally applicable flood assessment tool.
Evaluations reveal that R2RAG-Flood attains a Severity Score of 0.844, effectively mirroring the performance of the supervised FloodDamageCast* benchmark. Importantly, this comparable accuracy is coupled with superior cost-efficiency; the system demonstrates the highest Severity-per-Cost ratio among those tested. This indicates that R2RAG-Flood not only provides a reliable assessment of flood severity, but also achieves this at a reduced computational expense, presenting a pragmatic and scalable solution for widespread flood risk analysis and response.
The pursuit of accurate post-storm damage assessment, as demonstrated by R2RAG-Flood, echoes a fundamental principle of mathematical rigor. The framework’s emphasis on a reasoning-centric knowledge base isn’t merely about data accumulation, but about establishing a provable foundation for prediction. As Paul Erdős aptly stated, “A mathematician knows a lot of things, but a physicist knows a few.” This sentiment translates to the need for a clearly defined, logically structured knowledge base-akin to mathematical axioms-before attempting to extrapolate damage extent. R2RAG-Flood’s training-free approach further highlights the power of inherent reasoning when grounded in a solid, well-constructed foundation, rather than relying solely on empirical observation or vast datasets.
Beyond Immediate Forecasts
The presented framework, while demonstrating a functional approach to post-storm damage nowcasting, ultimately sidesteps the core challenge inherent in all data-driven predictive models: generalization. The reliance on a pre-constructed knowledge base, however meticulously curated, introduces a static bias. True elegance would lie in a system capable of deducing damage correlations from first principles – physical models of flood propagation and structural vulnerability – rather than simply recalling observed instances. The current architecture treats knowledge as a lookup table; a provably correct solution would synthesize it.
Furthermore, the ‘training-free’ aspect, while pragmatically appealing, obscures a fundamental trade-off. Avoiding parameter updates sidesteps the statistical rigor required to quantify uncertainty. Every prediction, therefore, remains an assertion, not a probability. Future work must address this by incorporating Bayesian inference or similar techniques, even if it necessitates a degree of supervised learning. The cost of computation is trivial compared to the cost of incorrect assumptions.
The pursuit of ‘reasoning’ in large language models is often a semantic exercise. This work’s focus on a reasoning-centric knowledge base is a step in the right direction, but it should not be mistaken for genuine logical deduction. The ultimate benchmark will not be performance on curated datasets, but the ability to extrapolate to entirely novel scenarios – to predict damage in situations never before encountered, based on verifiable physical laws, not statistical correlations. Only then will such a system transcend mere pattern recognition and approach true understanding.
Original article: https://arxiv.org/pdf/2602.10312.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- Gold Rate Forecast
- How to Solve the Glenbright Manor Puzzle in Crimson Desert
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Crimson Desert: 8 Best Skills to Unlock First
- $2B AI cow collars use “cowgorithm” to herd cattle with no fences
- ‘Send Help’ Sets Digital Streaming Release Date With Gory Deleted Scene From Horror Hit [Exclusive]
2026-02-13 03:46