Author: Denis Avetisyan
Researchers have developed a novel framework that blends physics-based modeling with advanced machine learning to anticipate equipment failures with improved accuracy and reliability.
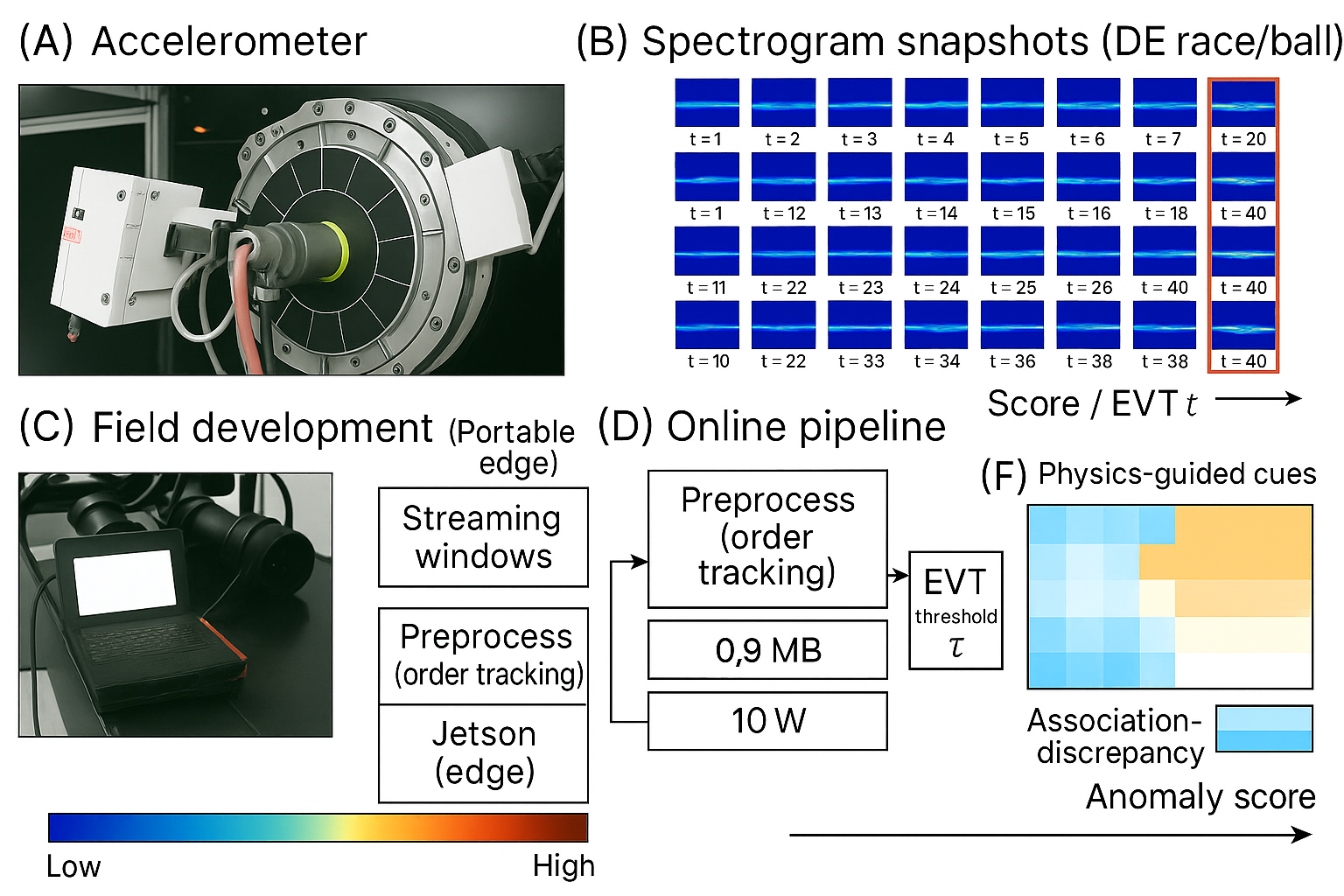
This work introduces a Physics-Guided Tiny-Mamba Transformer combined with Extreme Value Theory for reliable early fault warning in rotating machinery.
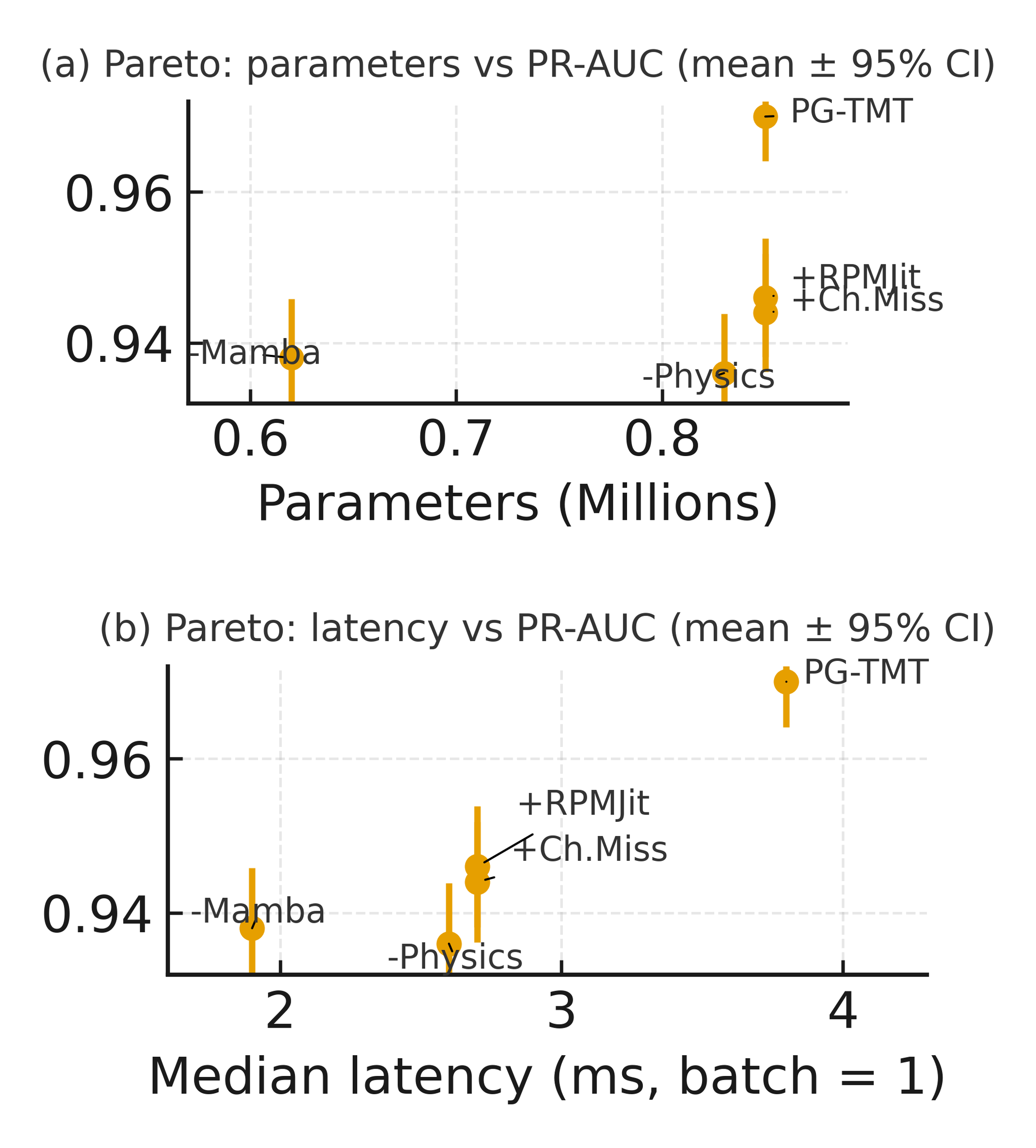
Achieving reliable early fault warnings in rotating machinery is challenged by non-stationary operating conditions, domain shifts, and imbalanced datasets. To address this, we introduce the ‘Physics-Guided Tiny-Mamba Transformer for Reliability-Aware Early Fault Warning’, a novel framework combining a compact neural network-featuring depthwise convolutions, state-space models, and local transformers-with extreme value theory for calibrated decision-making. This approach yields improved precision-recall and shorter detection times at matched false-alarm rates, alongside interpretable, physics-aligned representations. Could this integration of physics-informed machine learning and statistical rigor unlock a new era of proactive health management in critical industrial systems?
The Imperative of Precise Fault Identification
The relentless pursuit of system uptime drives a critical need for swift fault identification in complex infrastructures. Prolonged downtime isn’t merely inconvenient; it translates directly into substantial financial losses, compromised safety protocols, and eroded public trust-particularly within sectors like aerospace, healthcare, and modern energy grids. Consequently, substantial research focuses on developing methodologies that not only pinpoint anomalies but do so with minimal latency. The challenge lies in the inherent complexity of these systems, where cascading failures can originate from subtle deviations and propagate rapidly. Therefore, the ability to proactively detect and isolate faults before they escalate into catastrophic events is paramount, shifting the focus from reactive maintenance to predictive strategies and demanding innovations in real-time monitoring and diagnostic tools.
Conventional fault detection systems frequently face a fundamental trade-off between swiftness and precision. Many established methods prioritize speed, scanning for anomalies with minimal delay, but at the cost of increased false positive rates – triggering alarms for benign fluctuations that aren’t genuine failures. Conversely, techniques focused on high accuracy often demand extensive data analysis and complex calculations, introducing unacceptable latency and potentially missing critical, time-sensitive events. This inherent limitation poses a significant challenge for maintaining operational uptime in intricate systems where both rapid response and reliable identification of true faults are paramount; a delicate balance must be achieved to avoid either disruptive, unnecessary interventions or catastrophic failures going unnoticed.
Quantifying Risk Through Extreme Value Theory
The EVT-Based Decision Layer implements a statistical framework for evaluating anomaly severity by applying principles of Extreme Value Theory (EVT). Rather than treating all anomalies equally, this layer focuses on the tail of the distribution of anomalous data, characterizing events that deviate significantly from typical behavior. EVT allows for the modeling of the probability of extreme events-those beyond the scope of standard Gaussian distributions-by focusing on the exceedances over a defined threshold. This approach enables a probabilistic assessment of risk, moving beyond simple binary anomaly detection to provide a quantifiable measure of the potential impact associated with each anomalous observation. The core principle involves fitting statistical distributions, such as the Generalized Pareto Distribution (GPD), to these exceedances to estimate the likelihood of even more severe events occurring.
The Generalized Pareto Distribution (GPD) is employed to model the distribution of anomaly magnitudes exceeding a defined threshold. This is achieved by fitting the GPD to the exceedances – the values that surpass this threshold – allowing for extrapolation beyond observed data. The GPD is parameterized by a shape parameter ξ and a scale parameter σ, which determine the tail behavior of the distribution. Specifically, the GPD describes the probability of observing an exceedance of a given magnitude, enabling the calculation of return levels – the expected magnitude of an event occurring with a specific recurrence interval. Robust decision thresholds are then established by defining anomaly scores based on these return levels, effectively translating extreme value probabilities into actionable risk assessments.
The Anomaly Score represents a shift from binary alert systems to a continuous risk assessment. Rather than simply indicating the presence of an anomaly, the score provides a numerical value reflecting the severity and potential impact of the event. This score is derived from parameters estimated using the Generalized Pareto Distribution (GPD) applied to extreme observations, allowing for the probabilistic quantification of anomaly magnitude. Consequently, the Anomaly Score facilitates risk-based prioritization, enabling automated responses tailored to the quantified level of threat and supporting informed decision-making beyond simple alarm acknowledgment. This allows for the implementation of tiered response strategies, allocating resources efficiently based on the assessed risk level.
Stabilizing System Response with Adaptive Thresholds
The Extreme Value Theory (EVT)-based decision layer dynamically adjusts alarm thresholds to manage false alarm intensity. This is achieved by statistically modeling the distribution of extreme events – those representing genuine faults – and calibrating thresholds relative to this distribution. Rather than using fixed thresholds, the system continuously updates these values based on observed event characteristics, ensuring the system maintains a pre-defined target rate of false alarms. This adaptive approach accounts for variations in operational conditions and data quality, optimizing the balance between sensitivity to actual faults and minimizing nuisance alarms. The calibration process relies on parameters derived from the fitted extreme value distribution, allowing for precise control over the desired false alarm rate.
Hysteresis is implemented within the alarm decision layer as a method of stabilizing alarm state transitions. This is achieved by requiring a sensed value to move beyond a defined threshold and remain beyond it for a specified duration, or conversely, to fall below a threshold and remain there, before an alarm state changes. This prevents rapid, oscillating alarm activations – known as ‘chattering’ – that can occur due to minor signal fluctuations or noise. By requiring sustained deviations from normal operating parameters to trigger or clear an alarm, hysteresis significantly reduces nuisance alarms and the associated operator workload, improving overall system usability and operator effectiveness.
Survival Analysis is employed to quantitatively evaluate the effectiveness of alarm optimization techniques by modeling the time interval until a fault is detected. This statistical method allows for the creation of a ‘time-to-event’ distribution, enabling the calculation of metrics such as Mean Time To Detect (MTTD) and the probability of detection within a specific timeframe. By analyzing the survival function and hazard rate, we can rigorously compare the performance of different alarm configurations and calibration strategies, demonstrating improvements in fault detection speed and reliability. The technique accounts for ‘censored’ data – instances where faults haven’t been detected within the observation period – providing a more accurate assessment than methods that only consider fully observed events.
Demonstrating System Resilience Through Predictive Modeling
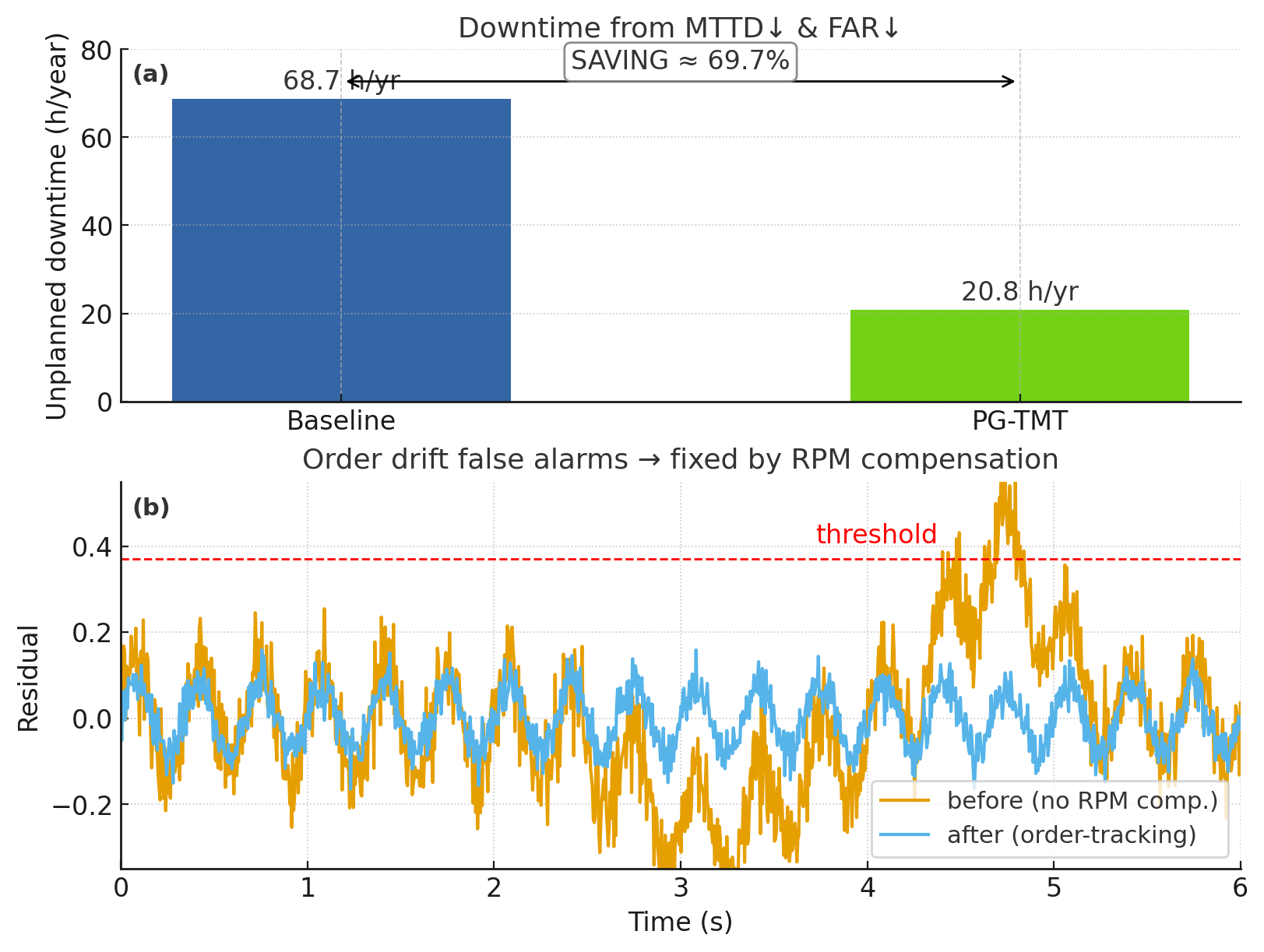
The early-warning system significantly enhances system availability modeling by directly addressing the core issues of false positives and detection latency. Through meticulous refinement, the system minimizes spurious alerts, thereby reducing unnecessary interventions and wasted resources. Simultaneously, improvements in detection speed demonstrably lower the Mean\ Time\ To\ Detect\ (MTTD), representing the average time required to identify a critical system issue. This dual reduction in false alarms and delayed detections allows for a more accurate representation of system health, enabling proactive maintenance strategies and ultimately contributing to a more reliable and consistently operational infrastructure. The resulting model provides a clearer, more trustworthy picture of potential failures, moving beyond reactive responses to a predictive, preventative approach.
The system’s resilience stems from a synergistic integration of Extreme Value Theory (EVT) and hysteresis – a combined approach designed to anticipate and neutralize potential failures before they escalate. EVT allows the system to model the probability of rare, high-impact events – those most likely to cause catastrophic failures – by extrapolating beyond historical data. This predictive capability is then reinforced by hysteresis, a mechanism that introduces a ‘memory’ into the system’s response. Rather than reacting immediately to every fluctuation, hysteresis demands a sustained deviation from normal parameters before triggering an alert, effectively filtering out transient noise and preventing false alarms. This deliberate delay, combined with EVT’s rare-event modeling, creates a robust framework that proactively mitigates risks, ensuring continuous operation and minimizing the potential for system-wide failures.
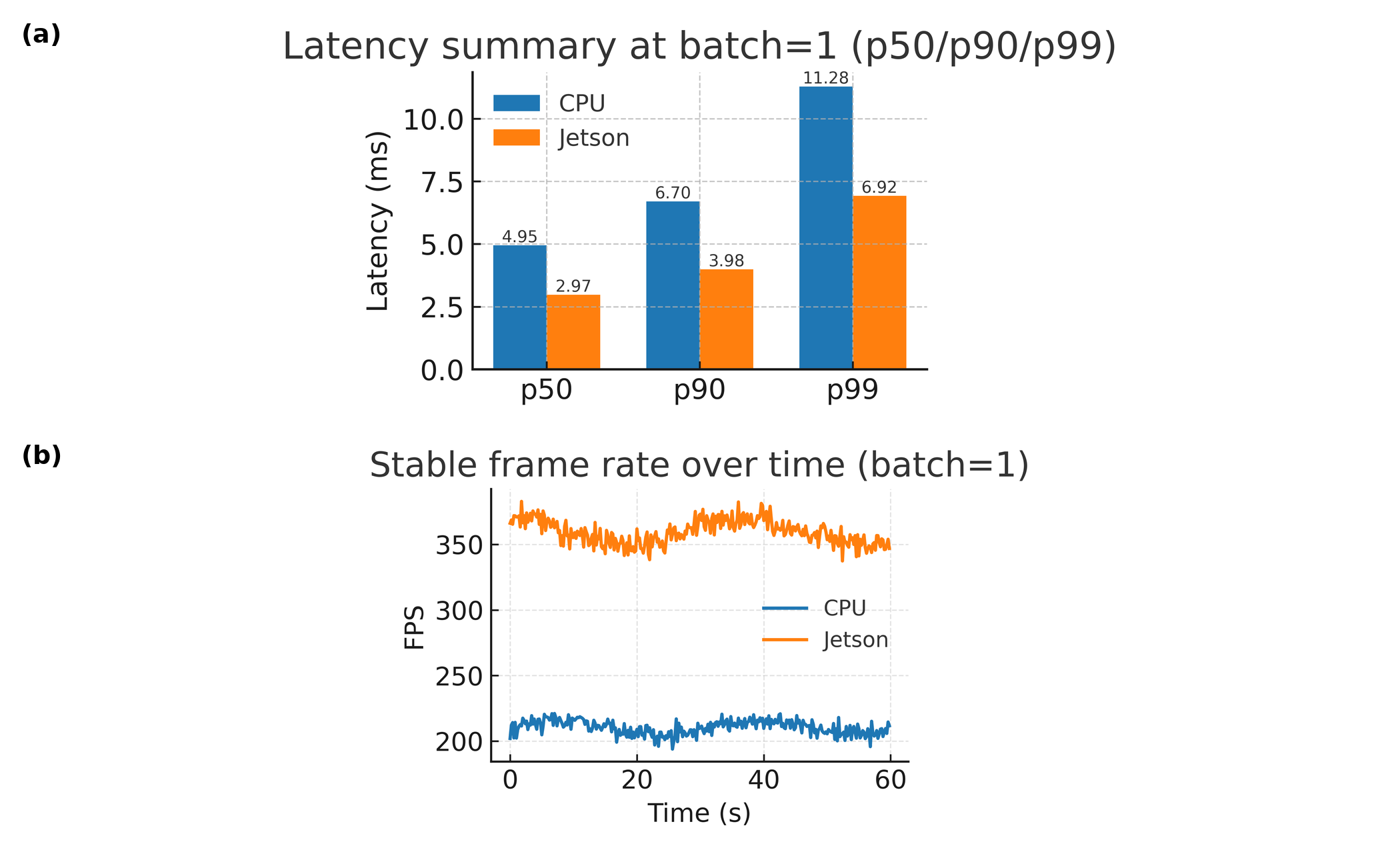
Accurate modeling of Time-to-Detect is now achievable without sacrificing computational efficiency. This system demonstrates the capacity to predict the duration between a system perturbation and its detection, enabling proactive maintenance strategies tailored to specific risk profiles. Critically, this predictive capability is delivered within remarkably constrained resources – the model occupies less than 1MB of storage and achieves end-to-end latency under 10ms. This minimal footprint facilitates deployment on edge devices and resource-limited infrastructure, maximizing uptime and minimizing costly downtime through precisely timed interventions and optimized scheduling, ultimately shifting maintenance from reactive repair to preventative care.

The pursuit of robust early fault detection, as demonstrated in this framework, echoes a fundamental principle of mathematical rigor. The integration of physics-informed machine learning with Extreme Value Theory isn’t merely about achieving high accuracy; it’s about establishing a provable understanding of system behavior under stress. As Carl Friedrich Gauss stated, “If other sciences are to be advanced, mathematics must be advanced first.” This sentiment perfectly encapsulates the approach detailed in the paper – the algorithm’s reliability stems from a foundation built on mathematical principles, ensuring not just predictive power, but also a verifiable and scalable solution for condition monitoring in rotating machinery. The focus on controlling false alarm rates underscores a commitment to precision, a hallmark of elegant mathematical modeling.
What Remains Constant?
The pursuit of early fault detection, as demonstrated by this work, frequently prioritizes incremental improvements in predictive accuracy. Yet, let N approach infinity – what remains invariant? The fundamental challenge isn’t merely detecting the anomaly, but quantifying the uncertainty inherent in its prediction. While the integration of physics-informed learning and Extreme Value Theory offers a promising route towards reliability, the framework’s sensitivity to the accuracy of the underlying physical models remains a critical limitation. A perfectly accurate model is, of course, an asymptote, never reached.
Future work must address the propagation of model error through the entire inference pipeline. Simply achieving high precision on a finite dataset is insufficient; the system’s behavior as the operational lifespan extends, and data distributions shift, requires rigorous investigation. Consideration should be given to developing methods for adaptive model refinement, or, more radically, to systems capable of explicitly flagging instances where the physical model’s assumptions are demonstrably violated.
The ambition to predict failure is, at its core, an attempt to impose order on a fundamentally stochastic process. Therefore, the ultimate metric of success isn’t the number of correctly predicted faults, but the system’s ability to consistently and accurately estimate its own degree of ignorance. That, and only that, will hold constant as N approaches infinity.
Original article: https://arxiv.org/pdf/2601.21293.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- How to Get to the Undercoast in Esoteric Ebb
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Warframe Voruna Prime access begins on April 8 for all platforms, new deluxe cosmetic Warframe skins revealed
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- Zendaya’s 4 Big 2026 Movies Could Beat Brie Larson’s Box 2019 Office Record
- Dakota County’s plan to end hunger involves locking mayors in escape rooms
- All Itzaland Animal Locations in Infinity Nikki
2026-02-01 19:01