Author: Denis Avetisyan
Researchers have developed a method to significantly improve the accuracy and reliability of machine learning models used to forecast complex fluid dynamics over extended periods.
This work introduces a conserved quantity correction for auto-regressive neural operators solving the compressible Navier-Stokes equations, enhancing long-rollout predictions of turbulent flows.
While deep learning offers a promising avenue for accelerating the numerical simulation of complex physical systems, accurately modeling long-term dynamics remains a significant challenge due to error accumulation and the difficulty in enforcing physical constraints. This is addressed in ‘Benchmarking Long Roll-outs of Auto-regressive Neural Operators for the Compressible Navier-Stokes Equations with Conserved Quantity Correction’, which introduces a model-agnostic conserved quantity correction technique to improve the stability and accuracy of auto-regressive neural operators when applied to fluid dynamics. The results demonstrate consistent performance gains across various architectures, highlighting the critical role of physical conservation in long-horizon predictions. Given the limitations revealed in modeling high-frequency components, future work must prioritize neural operator architectures specifically designed to capture the nuances of turbulent flow phenomena.
The Inevitable Complexity of Fluidity
The behavior of fluids – liquids and gases – profoundly impacts a vast range of scientific and engineering disciplines, making its accurate modeling paramount. This modeling relies heavily on the Compressible Navier-Stokes Equations, a set of partial differential equations describing the motion of viscous fluids. From predicting weather patterns and optimizing aircraft designs to simulating the complex processes within internal combustion engines, these equations form the foundation for understanding and predicting fluid dynamics. \nabla \cdot \mathbf{v} = 0 represents the incompressibility condition, a simplified, yet crucial, aspect often used in these models. Consequently, advancements in accurately solving these equations directly translate to improvements in diverse fields, including climate science, biomedical engineering, and even astrophysical simulations of stellar phenomena – highlighting the ubiquitous importance of fluid dynamics.
Simulating fluid dynamics presents a significant computational hurdle due to the inherent complexities of modeling high-dimensional systems, a challenge acutely felt when attempting to resolve turbulent flows. Traditional numerical methods, such as finite difference or finite volume schemes, discretize the governing Navier-Stokes equations onto a grid; however, capturing the wide range of spatial and temporal scales present in turbulence demands exceedingly fine grids, leading to a dramatic increase in computational cost. This scaling issue arises because the number of grid points often needs to increase exponentially with the desired resolution, quickly exceeding the capabilities of even the most powerful supercomputers. Consequently, researchers often resort to simplifying assumptions or turbulence models, which, while reducing computational burden, introduce inaccuracies and limit the predictive power of the simulations. The difficulty in resolving these fine-scale turbulent structures remains a primary obstacle in advancing fields reliant on accurate fluid dynamic predictions.
The inability to efficiently model complex fluid dynamics presents significant obstacles to advancement in several critical fields. Accurate weather forecasting, for instance, relies on predicting atmospheric flows, but computational constraints limit the resolution and range of these predictions – hindering the ability to anticipate severe weather events. Similarly, aerodynamic design, crucial for developing more efficient aircraft and vehicles, demands precise simulations of airflow around complex geometries, which are often beyond the reach of conventional methods. Perhaps most critically, progress in combustion modeling – essential for designing cleaner and more efficient engines – is hampered by the difficulty of capturing the turbulent mixing and chemical reactions that govern the process; this impacts everything from vehicle fuel efficiency to power generation technologies.
Beyond Discretization: The Promise of Neural Operators
Neural operators represent a departure from conventional numerical methods for solving partial differential equations (PDEs). Traditional techniques typically discretize both the spatial domain and the function space, leading to high computational costs and potential inaccuracies, particularly with increasing resolution. In contrast, neural operators learn a mapping directly between function spaces – specifically, a mapping from input functions (e.g., initial/boundary conditions) to output functions (the solution of the PDE). This is achieved by approximating the solution operator \mathcal{S} such that \mathcal{S}: X \rightarrow Y, where X and Y are function spaces. By operating directly on functions, neural operators offer the potential for significantly improved efficiency and accuracy, especially for problems with high dimensionality or complex geometries, as the computational cost does not scale directly with the discretization resolution.
DeepONet, a core architecture in neural operator development, functions by decoupling the input function’s domain and range via a branch and trunk network structure. The branch network \Phi_{\theta} maps the input function’s domain to a high-dimensional feature space, effectively encoding spatial information. Concurrently, the trunk network \Psi_{\gamma} learns to map the coordinates of the output space to corresponding function values. The universal approximation theorem supports the capacity of this architecture to approximate any continuous operator; the final output is computed as an inner product between the branch and trunk network outputs, allowing DeepONet to directly learn the mapping between functions without requiring discretized data or explicit specification of boundary conditions.
Extending the capabilities of DeepONet architectures necessitates focused development in two key areas. Current implementations exhibit limitations in accurately representing high-frequency components of solution spaces, impacting performance on problems with rapid oscillations or fine details. Addressing this requires innovations in network architecture – such as incorporating Fourier Neural Operators or adaptive wavelet transforms – to improve spectral representation. Simultaneously, computational efficiency remains a significant hurdle, particularly when dealing with high-dimensional problems or requiring real-time predictions. Strategies to mitigate this include model pruning, quantization, and the development of more efficient kernel functions, as well as exploiting parallelization techniques to reduce training and inference times.

DPOT: Decoding Fluidity Through Spectral Attention
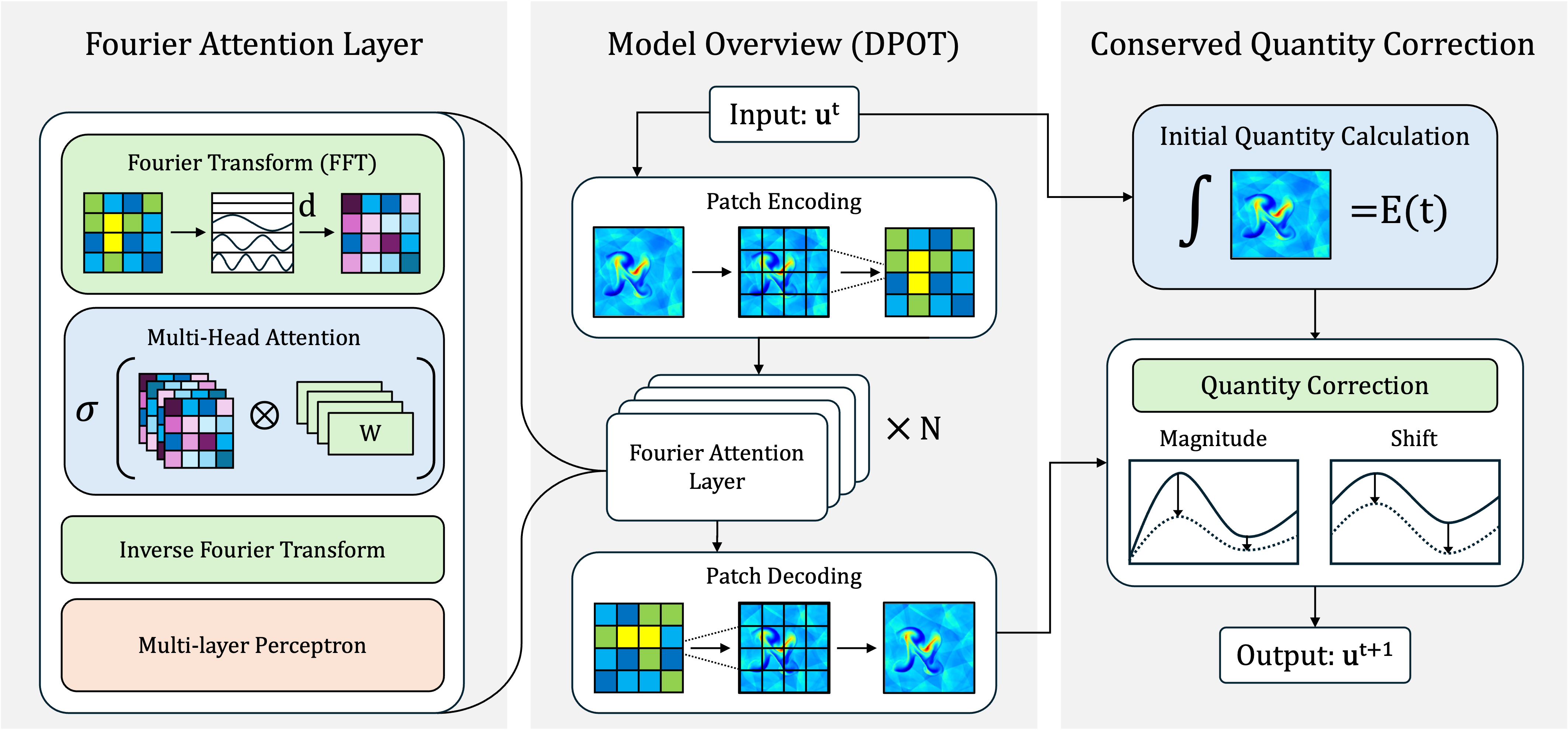
The DPOT model employs the Fourier Transform to convert fluid dynamics data from the spatial domain to the frequency domain. This decomposition allows the model to represent the data as a superposition of sinusoidal waves of varying frequencies and amplitudes. By operating in the frequency domain, DPOT can efficiently capture spectral characteristics – patterns related to the distribution of energy across different frequencies – which are crucial for understanding and predicting fluid behavior. This approach facilitates the identification of dominant flow structures and enables the model to generalize to unseen data by focusing on underlying spectral features rather than specific spatial configurations. The transformed data is represented as \hat{u}(k) , where u is the original signal and k represents the frequency.
The attention mechanism integrated into DPOT selectively weights frequency components derived from the Fourier Transform of fluid dynamics data. This is achieved through learned attention weights applied to the spectral representation, allowing the model to prioritize salient frequencies for prediction. By focusing on the most relevant frequency bands, the attention mechanism reduces the impact of noise and irrelevant details, thereby enhancing both the accuracy and robustness of the model’s predictions, particularly in scenarios with complex or incomplete data. This adaptive weighting process enables DPOT to effectively capture and utilize the spectral information inherent in fluid dynamics simulations and observations.
Patch Embedding within the DPOT architecture facilitates the encoding of local features from the input fluid dynamics data prior to global transformations. This process divides the input data into discrete patches, each of which is then linearly projected into an embedding space. By processing localized regions initially, the model captures fine-grained details and spatial relationships. This localized feature extraction is crucial for representing multiscale dynamics, as it allows the model to identify and encode features at varying resolutions. The resulting patch embeddings serve as input to subsequent layers, enabling the model to integrate local information into a global representation and effectively learn complex flow patterns.
Conserved Quantity Correction (CQC) is implemented within the model to enforce adherence to fundamental physical principles and enhance solution stability. This technique directly constrains the model’s predictions to satisfy established conservation laws, such as the conservation of mass and momentum. CQC operates by calculating the discrepancy between predicted and true conserved quantities at each time step and applying a corrective term to the model’s output. This correction minimizes the violation of these laws, preventing the development of non-physical artifacts and improving the long-term accuracy and reliability of the simulations, particularly in scenarios with complex flow dynamics. The magnitude of the correction is dynamically adjusted based on the severity of the conservation violation, allowing for a balance between enforcing physical consistency and preserving the model’s learned behavior.
A New Benchmark: DPOT’s Performance on PDEBench
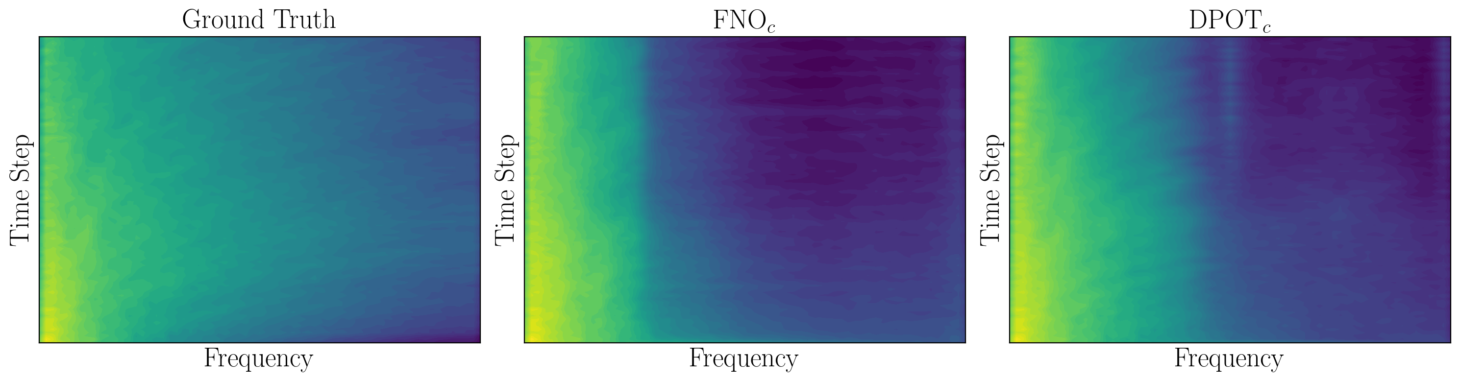
DPOT establishes a new benchmark in solving partial differential equations (PDEs), as evidenced by its state-of-the-art performance on PDEBench. This widely-used dataset rigorously tests the accuracy and efficiency of PDE solvers, and DPOT consistently outperforms existing methods in predicting complex physical phenomena. The model’s success isn’t merely incremental; it represents a significant leap forward in the field, offering substantially more accurate solutions with improved computational efficiency. By excelling on PDEBench, DPOT demonstrates its potential for broad application across diverse scientific and engineering domains, from fluid dynamics and heat transfer to materials science and beyond, promising more reliable simulations and accelerated discovery.
The training of this model leverages an auto-regressive rollout technique, a process wherein the model’s own predictions are iteratively fed back into itself as input for subsequent predictions. This recursive approach is crucial for enhancing the long-term stability of the solver, effectively allowing it to build upon its previous inferences. By continually refining its understanding of the partial differential equation through self-consistent predictions, the model minimizes error accumulation over extended prediction horizons. This method fosters a feedback loop that promotes both accuracy and robustness, enabling the model to maintain reliable solutions even after multiple iterative steps – a key requirement for many real-world scientific applications.
The training of DPOT benefits from the implementation of a One-Cycle Learning Rate Scheduler, a technique designed to accelerate convergence and improve model generalization. This scheduler dynamically adjusts the learning rate throughout the training process, initially increasing it to quickly navigate the loss landscape and then gradually decreasing it to fine-tune the model parameters. By varying the learning rate in this cyclical manner, the scheduler effectively escapes local minima and converges more efficiently towards an optimal solution, ultimately minimizing the L_2 Relative Error between the model’s predictions and the established ground truth data. This optimized training process results in a more accurate and robust PDE solver, capable of producing reliable results with reduced computational cost.
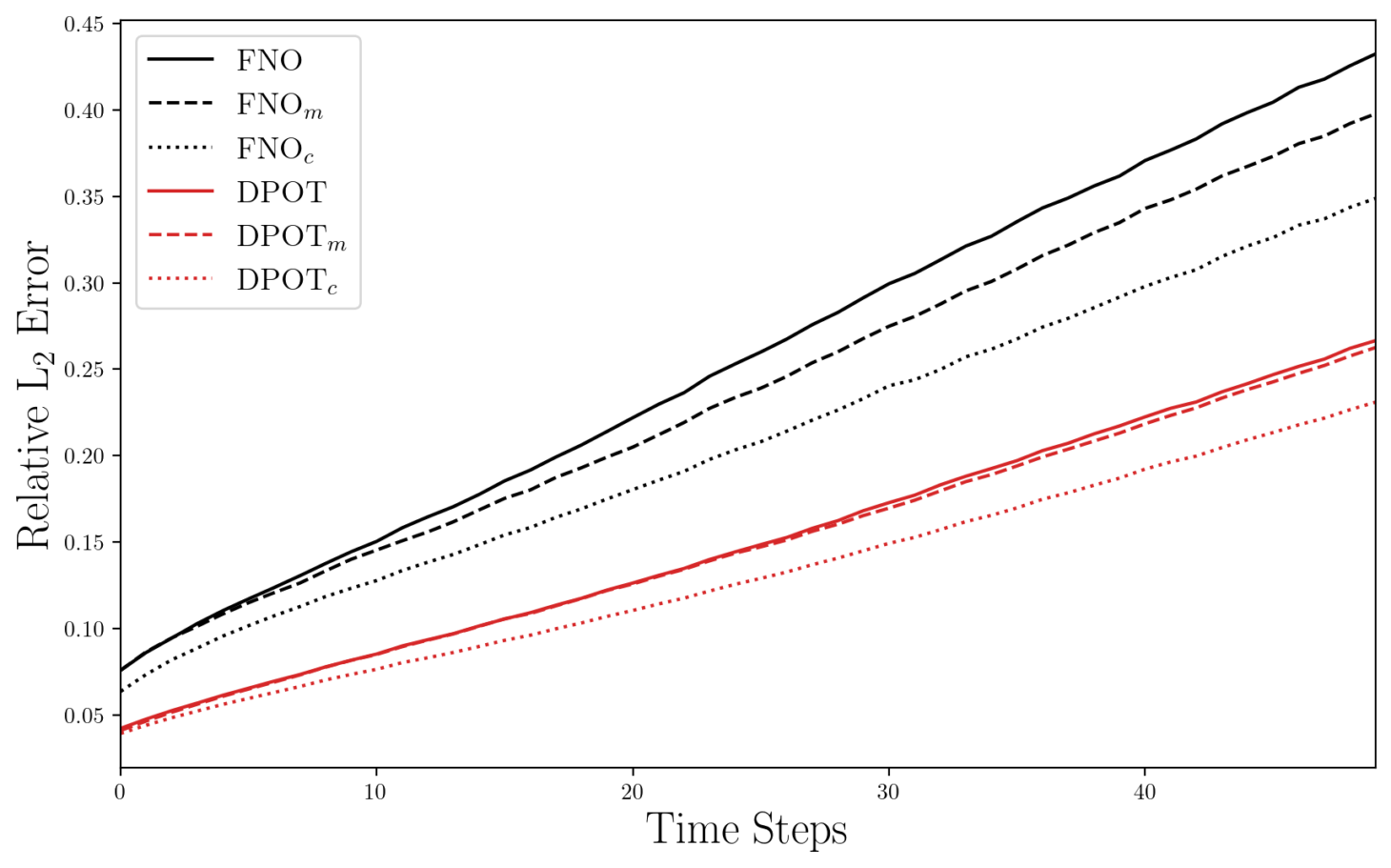
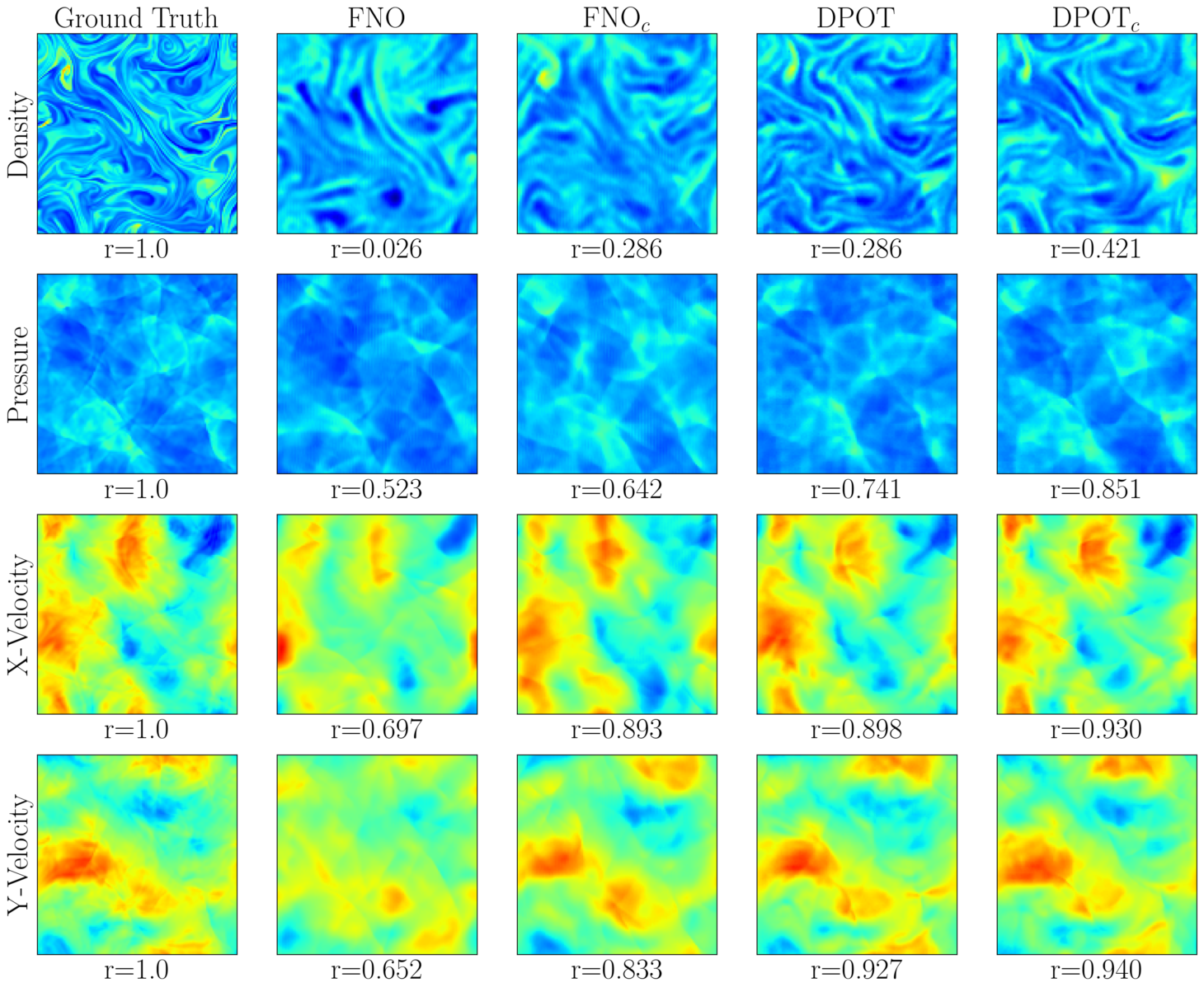
DPOT’s predictive capability is significantly enhanced through the implementation of Conserved Quantity Correction, a technique that enforces physical principles within the model’s predictions. This results in a remarkably low relative L2 error of only 7.8% after a sequence of ten auto-regressive predictions – a substantial improvement in accuracy for complex partial differential equations. Beyond immediate precision, the correction method also promotes long-term stability; the model maintains a strong correlation with ground truth data for an extended duration of 28 timesteps. This sustained accuracy over time highlights DPOT’s ability to not only predict initial states correctly but also to reliably extrapolate solutions forward, proving its effectiveness in scenarios requiring prolonged simulations and forecasts.
The demonstrated capacity of the model to reduce relative error by 0.4% for each subsequent timestep during extended predictions signifies a substantial advancement in predictive accuracy for complex systems. This consistent reduction, achieved over long rollouts, isn’t merely incremental; it suggests the model effectively learns and leverages temporal dependencies within the data to refine its forecasts. Unlike many predictive methods which experience compounding errors over time, this approach exhibits a self-correcting behavior, maintaining a higher degree of fidelity even as the prediction horizon extends. The consistent error reduction is particularly valuable in applications where long-term forecasting is crucial, such as climate modeling, fluid dynamics, and financial analysis, where even small improvements in accuracy can have significant downstream effects.
The pursuit of increasingly complex models, as demonstrated by this work on neural operators for fluid dynamics, inevitably leads to intricate dependencies. The researchers attempt to mitigate inherent instability through conserved quantity correction-a fascinating, if temporary, reprieve. This echoes a fundamental truth: systems aren’t built, they evolve, and every architectural choice, even one designed to enforce physical laws, is a prediction of future failure. As Brian Kernighan observed, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” The complexity introduced to maintain conservation, while improving prediction, simultaneously adds layers of potential fragility, ensuring that the system’s fate is interwoven with its inherent limitations.
What Lies Ahead?
The pursuit of long-horizon prediction in fluid dynamics, even with techniques like auto-regressive neural operators and conserved quantity correction, is not a convergence toward truth, but a refinement of controlled error. This work demonstrates improved stability, yet stability is merely a prolonged deferral of inevitable divergence. The conserved quantities enforced today will become the seeds of tomorrow’s unpredictable behavior as the system explores states unanticipated by the training data. Long stability is the sign of a hidden disaster.
Future effort will not resolve the fundamental problem – that these models are, at their core, approximations of infinitely complex phenomena. Instead, attention will likely shift toward more sophisticated methods of characterizing how these models fail. Expect to see greater emphasis on uncertainty quantification, not as a means of achieving perfect prediction, but as a means of gracefully managing unavoidable error. The goal will not be to prevent evolution, but to understand its trajectory.
The most interesting developments may not lie in improving the operators themselves, but in the ecosystems surrounding them. Hybrid approaches – combining these learned models with traditional simulation techniques, or even with real-time data assimilation – offer a path toward resilience, acknowledging that no single method can capture the full complexity of turbulent flow. Systems don’t fail – they evolve into unexpected shapes.
Original article: https://arxiv.org/pdf/2601.22541.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Mewgenics vinyl limited editions now available to pre-order
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Does Mark survive Invincible vs Conquest 2? Comics reveal fate after S4E5
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- How to Get to the Undercoast in Esoteric Ebb
2026-02-03 02:59