Author: Denis Avetisyan
A new study rigorously benchmarks the performance of physics-informed neural networks on simulating dynamical systems, highlighting strengths and limitations across different complexities.

Researchers evaluate Hamiltonian, Lagrangian, and Symplectic neural networks for their ability to accurately model conservative, chaotic, and dissipative dynamics.
Despite advances in physics-informed deep learning, a systematic evaluation of these methods across diverse dynamical systems-particularly those exhibiting chaotic or dissipative behavior-remains largely unexplored. This work, ‘Deepmechanics’, benchmarks three prominent architectures-Hamiltonian Neural Networks (HNNs), Lagrangian Neural Networks (LNNs), and Symplectic Recurrent Neural Networks (SRNNs)-using the DeepChem framework to assess their performance on six classical and non-conservative mechanical systems. Our results reveal strong performance on conservative systems but demonstrate that all benchmarked models struggle to maintain stability when applied to chaotic or dissipative dynamics, highlighting a critical gap in the robustness of current approaches. What architectural innovations or training strategies are needed to enable physics-informed deep learning to reliably model the full spectrum of classical mechanical systems?
The Limits of Calculation: Confronting Dynamical Complexity
Traditionally, simulating the behavior of complex physical systems – from weather patterns to fluid dynamics – has presented significant computational hurdles. Researchers often rely on numerical methods that discretize continuous processes, approximating solutions step-by-step. This approach, while versatile, demands substantial processing power, particularly as accuracy requirements increase or system complexity grows. Furthermore, to make these calculations tractable, scientists frequently employ simplifying assumptions – neglecting certain variables or interactions – which inevitably introduce inaccuracies and limit the model’s fidelity to the real world. These simplifications, though necessary for practical computation, can mask crucial system behaviors and hinder a complete understanding of the underlying physics, creating a trade-off between computational feasibility and model accuracy. \Delta t represents the crucial time-step size, directly impacting both computational cost and the potential for error accumulation.
Traditional dynamical systems modeling frequently encounters significant hurdles when applied to chaotic systems, where even minute changes in initial conditions can lead to drastically different outcomes. This sensitivity necessitates extraordinarily precise inputs – often impossible to achieve in real-world measurements – and demands computational power far exceeding what is readily available. Consequently, obtaining solutions of even moderate accuracy often requires extensive computation time, potentially spanning days, weeks, or even months for complex models. The computational cost isn’t merely a matter of processing speed; it’s fundamentally linked to the need to iteratively refine approximations, a process that escalates rapidly with increasing system complexity and the desire for greater precision. \Delta x \approx f'(x_0) \Delta x_0 This inherent limitation underscores the need for novel approaches that can efficiently navigate the complexities of chaotic dynamics without sacrificing accuracy or practicality.
Traditional dynamical systems modeling, while valuable, often presents a simplified view of reality, inadvertently obscuring critical nuances within complex systems. This reduction in dimensionality and reliance on averaged parameters can lead to inaccuracies in both predictive capability and effective control strategies. The inherent richness of system dynamics – encompassing subtle interactions, nonlinear feedback loops, and sensitivity to initial conditions – is frequently lost in the translation to manageable mathematical formulations. Consequently, predictions may diverge significantly from observed behavior, and control interventions, based on incomplete models, can yield unintended or suboptimal outcomes. This limitation is particularly pronounced in areas like climate modeling, fluid dynamics, and biological systems, where intricate, multi-scale interactions govern overall behavior and require capturing the full spectrum of dynamic possibilities for truly reliable forecasting and manipulation.
Embracing Constraint: Physics-Informed Deep Learning
Physics-Informed Deep Learning (PIDL) represents a departure from traditional deep learning approaches by explicitly incorporating known physical laws and constraints into the network’s structure and training process. Rather than relying solely on data-driven learning, PIDL utilizes these constraints – often expressed as partial differential equations (PDEs) or integral equations – to regularize the learning process and improve generalization. This integration can be achieved through various methods, including modifying the loss function to penalize deviations from physical principles, or by designing network architectures that inherently satisfy certain physical symmetries or conservation laws. The core principle is to guide the neural network towards solutions that are not only consistent with the observed data, but also physically plausible, thereby reducing the need for vast amounts of training data and enhancing the robustness and interpretability of the model.
Lagrangian Neural Networks (LNNs) and Hamiltonian Neural Networks (HNNs) represent a class of neural networks designed to incorporate known physical laws into their structure and training process. LNNs utilize the Lagrangian formalism, expressing system dynamics through scalar functions representing kinetic and potential energy, and enforcing constraints via automatic differentiation of the Lagrangian with respect to generalized coordinates. HNNs, conversely, are based on Hamiltonian mechanics, employing a Hamiltonian function – representing the total energy of the system – and leveraging symplectic integrators to preserve phase space volume during time evolution. Both approaches parameterize the potential and kinetic energy terms with neural networks, allowing the network to learn system dynamics from data while simultaneously adhering to the fundamental principles of classical mechanics, as expressed by \frac{d}{dt} \frac{\partial L}{\partial \dot{q}} - \frac{\partial L}{\partial q} = 0 for LNNs and Hamilton’s equations for HNNs.
Physics-Informed Neural Networks (PINNs), including Hamiltonian Neural Networks (HNN), Lagrangian Neural Networks (LNN), and Split-Reversible Neural Networks (SRNN), exhibit the capability to directly learn underlying system dynamics from observational data. Systematic benchmarking studies have demonstrated that these networks can achieve superior accuracy and computational efficiency compared to traditional numerical methods for solving differential equations and modeling physical systems. This performance gain stems from the integration of physical laws into the network’s loss function or architecture, effectively constraining the solution space and reducing the reliance on large datasets. The demonstrated advantages include faster convergence rates, improved generalization to unseen data, and the ability to accurately model complex, high-dimensional systems where conventional methods struggle.
Preserving Integrity: Symplectic Structures and Recurrence
Symplectic Recurrent Neural Networks (Symplectic RNNs) are a class of neural networks specifically constructed to maintain the symplectic structure inherent in Hamiltonian dynamical systems. Hamiltonian systems, described by H(q,p), evolve in phase space defined by generalized coordinates q and their conjugate momenta p. The symplectic structure is a mathematical property ensuring consistent evolution of these systems, typically expressed through a symplectic form ω. Traditional recurrent neural networks do not inherently preserve this structure, potentially leading to instability or inaccuracies in long-term simulations. Symplectic RNNs address this by incorporating symplectic integrators, such as the Leapfrog integrator, into their recurrent connections, thereby explicitly enforcing the preservation of ω during each time step and maintaining the geometric properties of the underlying dynamical system.
Symplectic Recurrent Neural Networks (Symplectic RNNs) achieve long-term stability and accurate time evolution by incorporating symplectic integrators, such as the Leapfrog Integrator, into their architecture. Traditional numerical methods for solving Hamiltonian systems often suffer from energy drift, leading to inaccurate simulations over extended periods. Symplectic integrators, however, are designed to preserve key invariants of the system, notably the volume-preserving property of phase space. The Leapfrog Integrator, a common symplectic algorithm, approximates the Hamiltonian flow while maintaining this invariance, resulting in bounded energy and improved long-term accuracy compared to non-symplectic methods. This preservation of the symplectic structure is crucial for reliably modeling physical systems governed by Hamiltonian dynamics.
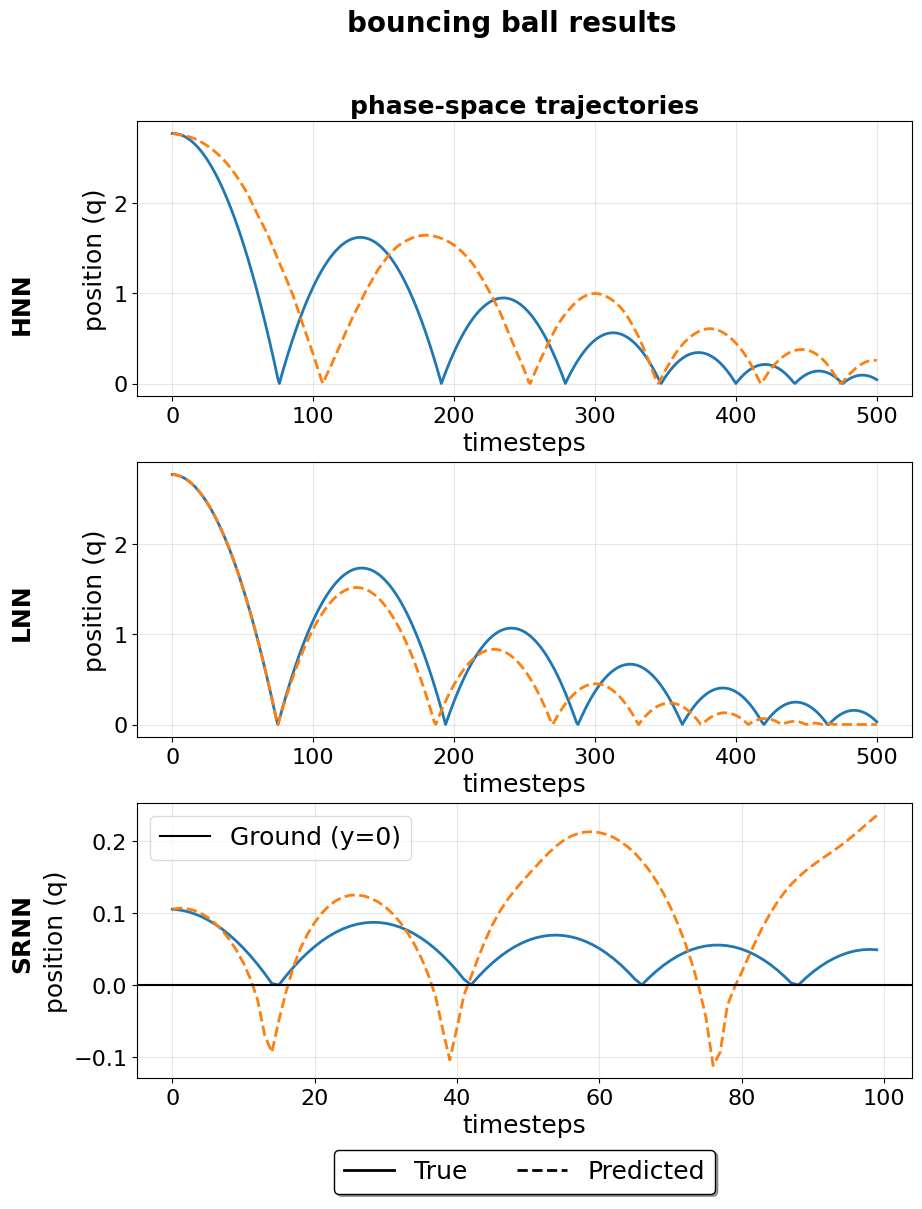
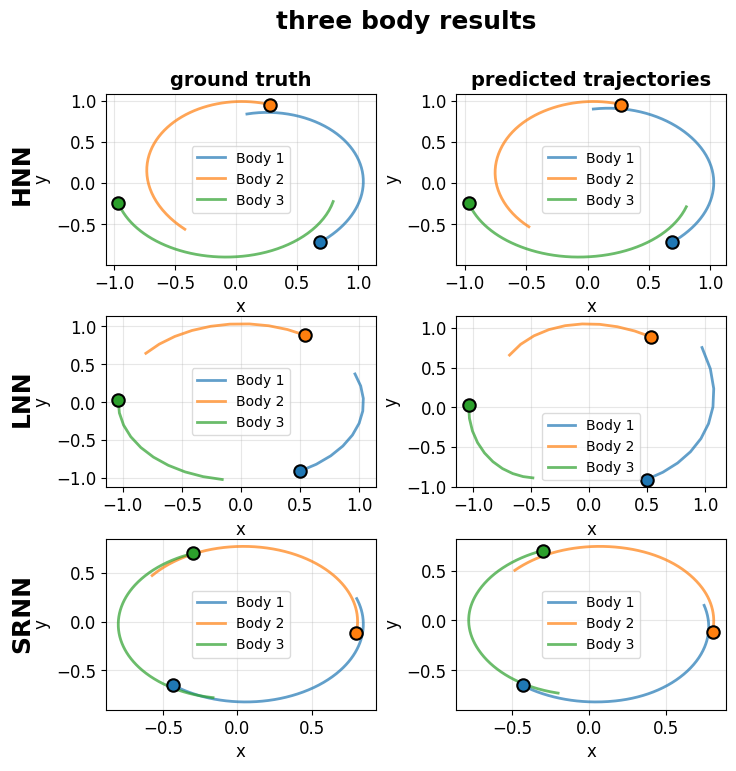
Performance benchmarking of Symplectic RNN architectures across several dynamical systems indicates task-specific efficacy. The Hamiltonian Neural Network (HNN) generally achieved a lower Mean Squared Error (MSE) when simulating the three-body problem, suggesting its suitability for gravitational interactions. Conversely, the Leapfrog Neural Network (LNN) exhibited the lowest error rates on both the bouncing ball and simple pendulum systems, as measured by both MSE and Root Mean Squared Error (RMSE). These results demonstrate that no single architecture universally outperforms others, and optimal performance is contingent on the characteristics of the modeled dynamical system.
A Platform for Dynamical AI: DeepChem
DeepChem establishes a robust and adaptable framework designed to facilitate the construction and training of physics-informed deep learning models. This platform integrates seamlessly with popular machine learning libraries, enabling researchers to leverage the power of deep learning while incorporating fundamental physical principles into model architectures. By offering pre-built components and streamlined workflows, DeepChem significantly reduces the complexities associated with developing these specialized models. The platform’s modular design allows for easy customization and extension, catering to a broad range of scientific applications-from molecular property prediction and materials discovery to drug design and quantum chemistry. Ultimately, DeepChem empowers scientists to efficiently explore complex systems and accelerate innovation through the convergence of physics and artificial intelligence.
DeepChem simplifies the complex undertaking of developing physics-informed deep learning models through its core classes, TorchModel and NumpyDataset. These tools fundamentally streamline the workflow, beginning with efficient data handling via NumpyDataset, which facilitates the loading, preprocessing, and organization of datasets directly from NumPy arrays. This data is then seamlessly integrated into the TorchModel class, designed for building and training deep learning architectures using PyTorch. By abstracting away much of the boilerplate code typically associated with data preparation, model definition, and training loops, DeepChem enables researchers to focus on the scientific problem at hand, accelerating the development and evaluation of predictive models for dynamical systems and beyond. The platform’s modular design further supports customization and experimentation, fostering rapid iteration and robust model validation.
Investigations into model performance revealed significant variations in Standard Deviation (STD) and Variance (VAR) across diverse systems and model architectures. This finding underscores a critical limitation of relying solely on traditional error metrics – such as mean squared error – to evaluate predictive capabilities. While error metrics quantify the average deviation between predictions and ground truth, STD and VAR capture the dispersion of those predictions. A model with low error can still exhibit high variance, indicating inconsistent performance and potential unreliability, particularly when extrapolating beyond the training data. Therefore, a comprehensive assessment requires consideration of both the central tendency and the spread of predictions, offering a more nuanced understanding of a model’s robustness and generalizability, especially in dynamical systems where small changes in initial conditions can lead to dramatically different outcomes-a phenomenon known as sensitivity to initial conditions.
Expanding the Horizon: Future Directions in Dynamical AI
Investigations are poised to extend dynamical AI techniques to notoriously complex systems previously intractable to simulation. Researchers anticipate significant advancements in modeling multi-body problems – encompassing everything from granular materials and robotic manipulation to celestial mechanics – and in capturing the chaotic behavior of turbulent flows, which governs weather patterns, engine efficiency, and astrophysical phenomena. These endeavors will necessitate innovative approaches to data assimilation and model reduction, potentially leveraging sparse representations and adaptive sampling strategies to manage computational demands. Success in these areas promises not only more accurate predictions but also a deeper understanding of the fundamental principles governing these complex physical processes, opening doors to novel designs and control strategies.
The convergence of physics-informed deep learning and established numerical methods represents a promising avenue for advancing scientific computing. Rather than replacing traditional techniques, hybrid approaches leverage the strengths of both worlds: deep learning’s capacity to learn complex patterns from data and numerical methods’ proven ability to enforce physical laws and ensure stability. This synergy allows for the creation of algorithms that are both more accurate and computationally efficient, particularly when dealing with systems where obtaining sufficient training data is challenging or expensive. By integrating prior physical knowledge into the learning process, these hybrid models can generalize better to unseen scenarios and require less data for training, ultimately accelerating scientific discovery across diverse fields. The resulting algorithms can potentially solve problems currently intractable for either approach alone, opening new possibilities for modeling and simulation.
The advent of Dynamical AI signals a transformative leap beyond conventional simulation and modeling, poised to revolutionize diverse scientific domains. This new paradigm offers the potential to design more adaptable and robust robotic systems capable of navigating complex, unpredictable environments, while simultaneously accelerating materials discovery by predicting material properties with unprecedented accuracy. Furthermore, the framework promises more nuanced and reliable climate models, enabling improved predictions of long-term weather patterns and the impacts of climate change. Even the vast complexities of astrophysics stand to benefit, with Dynamical AI potentially unlocking new understandings of turbulent flows in stars, the dynamics of galaxies, and the evolution of the universe itself – representing a fundamental shift in how scientific inquiry is conducted and knowledge is generated.
The pursuit of modeling dynamical systems with neural networks reveals a fundamental tension. While architectures like Hamiltonian Neural Networks demonstrate promise on conservative systems – preserving energy as expected – their efficacy diminishes when confronted with chaos or dissipation. This aligns with a core tenet of elegant design. As Ken Thompson observed, “Simplicity is prerequisite for reliability.” The article’s benchmarking highlights how quickly complexity – adding layers or novel architectures – fails to address inherent limitations in representing truly complex dynamics. Abstractions age, principles don’t; a network’s performance must be anchored in foundational physics, not merely layers of learned parameters.
Further Refinements
The observed aptitude of physics-informed neural networks for conservative dynamical systems is not surprising. Such systems, by definition, offer inherent constraints-a scaffolding upon which learning can readily proceed. The difficulty encountered with dissipative and chaotic systems, however, exposes a fundamental limitation. Current architectures appear to excel at preserving what is, rather than understanding how things change. Clarity is the minimum viable kindness; current methods lack clarity regarding the nature of instability.
Future work must address this. Benchmarking, while valuable, offers only a snapshot. The field requires a shift from merely demonstrating competence on established tasks to developing architectures capable of generalization-systems that learn the principles of dynamics, not merely their manifestations. The pursuit of ever-larger datasets will yield diminishing returns; the focus should instead be on minimizing the data needed to capture essential behavior.
Ultimately, the goal is not to build neural networks that simulate physics, but to build systems that embody it. A network that truly understands a dynamical system should be able to predict not just its trajectory, but its susceptibility to perturbation, its resonant frequencies, and the very nature of its stability. Such a network would be, in a sense, a digital echo of the universe’s underlying order.
Original article: https://arxiv.org/pdf/2602.18060.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Does Mark survive Invincible vs Conquest 2? Comics reveal fate after S4E5
- How to Get to the Undercoast in Esoteric Ebb
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
2026-02-24 07:37