Author: Denis Avetisyan
New research reveals that machine learning models protecting critical systems are surprisingly vulnerable to subtle attacks, and that improving their resilience can impact how easily we understand their decisions.
This paper presents an empirical analysis of adversarial robustness and explainability drift in cybersecurity classifiers, utilizing perturbation analysis and SHAP values to evaluate the trade-offs between security and interpretability.
Despite increasing reliance on machine learning for critical tasks like phishing detection and intrusion prevention, these systems remain surprisingly vulnerable to subtle, deliberately crafted input perturbations. This vulnerability is explored in ‘Empirical Analysis of Adversarial Robustness and Explainability Drift in Cybersecurity Classifiers’, which presents an empirical investigation into the coupled degradation of both accuracy and interpretability under adversarial attack. The study quantifies robustness using a novel Robustness Index and reveals consistent trends across cybersecurity datasets, demonstrating that adversarial training can improve resilience while highlighting feature sensitivity to manipulation. Can we develop truly trustworthy AI-driven cybersecurity systems that are both robust and transparent, even in the face of sophisticated adversarial threats?
The Fragility of Machine Intelligence
Modern cybersecurity increasingly relies on the analytical power of machine learning. These algorithms are no longer confined to theoretical applications; they are actively deployed in critical defense mechanisms. Specifically, machine learning models excel at identifying patterns indicative of malicious activity, making them essential for tasks like phishing URL detection, where algorithms analyze website characteristics to flag fraudulent sites, and network intrusion detection, where anomalous network traffic is identified as potential threats. The ability of these models to rapidly process vast datasets and adapt to evolving attack vectors has positioned them as a cornerstone of contemporary security infrastructure, offering a proactive defense against increasingly sophisticated cyber threats. This reliance, however, introduces new vulnerabilities that are currently under intense scrutiny.
Machine learning models, while demonstrating impressive capabilities in cybersecurity applications, exhibit a surprising fragility when confronted with adversarial attacks. These attacks don’t rely on brute force or exploiting software bugs, but instead involve subtly manipulating input data – crafting inputs that are intentionally designed to mislead the model. A phishing URL, for example, might be altered with imperceptible characters or cleverly disguised links, remaining visually identical to a legitimate site for a human user, yet causing the machine learning algorithm to incorrectly classify it as safe. Similarly, network intrusion detection systems can be fooled by slightly modified network packets that bypass security protocols. This vulnerability arises from the models’ reliance on statistical patterns rather than genuine understanding, meaning even minor, carefully calculated perturbations can lead to misclassification and compromise system security. The implications are significant, as attackers can effectively evade detection by exploiting these weaknesses, highlighting a critical need for robust defenses against adversarial machine learning.
The increasing reliance on machine learning for cybersecurity creates a paradoxical vulnerability: systems designed to protect against threats can be subverted through cleverly disguised attacks. Adversarial examples, subtly altered inputs imperceptible to humans, can consistently fool these models, allowing malicious traffic to pass undetected or legitimate activity to be flagged as suspicious. This isn’t a theoretical concern; researchers have demonstrated successful bypasses of sophisticated phishing detectors and intrusion prevention systems using these techniques. Consequently, attackers need only manipulate data, not necessarily compromise the underlying algorithms, to bypass defenses, representing a significant and evolving threat to digital security and potentially allowing widespread breaches of sensitive information and critical infrastructure.
The Art of Deception: Crafting Adversarial Inputs
Adversarial perturbation refers to the intentional modification of input data – such as images, audio, or text – by introducing small, carefully crafted alterations. These changes are typically designed to be minimally perceptible to human observers, often falling below the threshold of noticeable difference. However, despite their subtlety, these perturbations can cause machine learning models to make incorrect predictions with high confidence. The magnitude of these changes is often measured using metrics like the L_p norm, quantifying the distance between the original and perturbed inputs. The goal is not to introduce random noise, but to find specific, targeted alterations that exploit vulnerabilities in the model’s decision boundary.
Algorithms such as the Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) generate adversarial perturbations by calculating the gradient of the loss function with respect to the input data. FGSM creates a perturbation by moving in the direction of the sign of the gradient, multiplied by an epsilon value controlling the perturbation magnitude. PGD is an iterative method that refines this process, applying multiple small perturbations and projecting the resulting input onto a permissible range to remain within valid data boundaries. Both methods systematically search for minimal alterations to the input that cause the largest possible increase in the model’s error, effectively maximizing the loss function and leading to misclassification.
Despite achieving high accuracy rates on standard datasets, current machine learning models demonstrate a notable lack of robustness to adversarial examples. These attacks, which introduce minimal, intentionally crafted perturbations to input data, consistently cause misclassification, even in models with documented performance exceeding 99% on clean data. This vulnerability isn’t necessarily indicative of overfitting to training data, but rather a fundamental sensitivity to input distributions outside of those encountered during training. The success of adversarial attacks across diverse model architectures – including deep neural networks, support vector machines, and decision trees – suggests that the issue stems from the models’ reliance on potentially brittle feature representations and decision boundaries, rather than a specific algorithmic flaw.
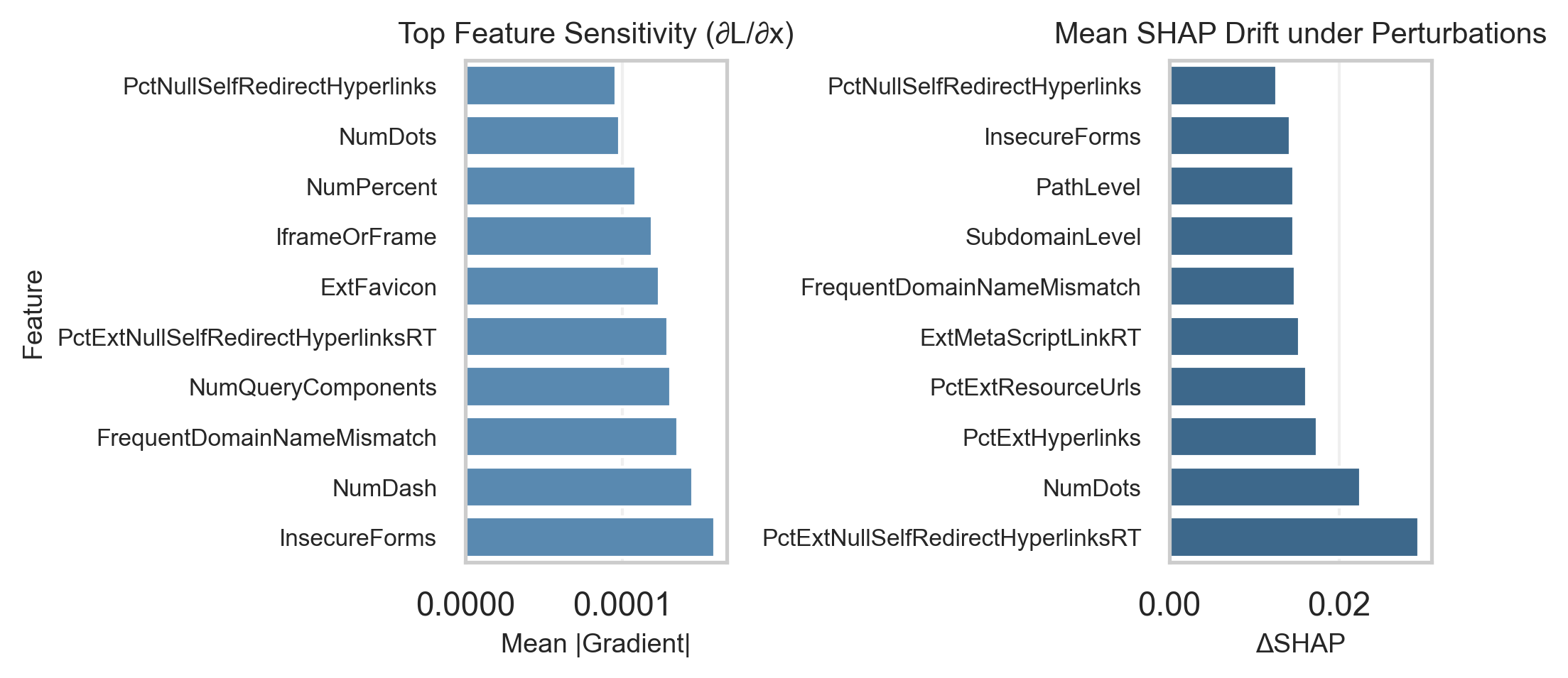
Unveiling Instability: Feature Sensitivity and Attribution Drift
Feature sensitivity quantifies the degree to which a model’s output changes in response to alterations in specific input features. This metric is calculated by perturbing each input feature, either individually or in combination, and observing the resulting change in the model’s prediction. A higher degree of sensitivity indicates the model is more reliant on that feature for its decision-making process; conversely, low sensitivity suggests the model is less affected by changes to that input. Analyzing feature sensitivity can reveal potential vulnerabilities or biases within the model, highlighting features that exert disproportionate influence on predictions and potentially indicating a lack of robustness to input variations.
SHAP (SHapley Additive exPlanations) values assign each feature an importance value for a particular prediction. These values are based on concepts from cooperative game theory and represent the average marginal contribution of each feature across all possible combinations of features. Specifically, a feature’s SHAP value indicates the degree to which that feature pushes the model’s output away from the base value (the average model prediction). Higher absolute SHAP values signify greater influence on the prediction; positive values indicate a feature increased the prediction, while negative values indicate a decrease. By calculating SHAP values for each feature in a dataset, one can determine which features are most impactful in driving the model’s decision-making process for individual instances and overall.
SHAP Attribution Drift quantifies the instability of feature importance by measuring the change in SHAP values when subjected to small, intentionally crafted input perturbations – known as adversarial perturbations. These perturbations, designed to be imperceptible to humans, can significantly alter the SHAP values assigned to features, even if the model’s prediction remains the same. A high degree of SHAP Attribution Drift indicates that the model’s explanations are not robust and are sensitive to minor changes in the input, casting doubt on the trustworthiness of those explanations and suggesting that the model may be relying on spurious correlations rather than genuine relationships within the data. This instability challenges the use of SHAP values for critical decision-making where reliable and consistent explanations are paramount.
![A heatmap reveals that feature importance, as measured by the mean SHAP attribution drift <span class="katex-eq" data-katex-display="false">\Delta\phi_i</span>, varies considerably across <span class="katex-eq" data-katex-display="false">\epsilon\in[0, 0.3]</span>, with redder regions indicating greater instability.](https://arxiv.org/html/2602.06395v1/figures/shap_drift_heatmap_unsw.png)
Building Resilient Systems: Towards Robust Machine Learning
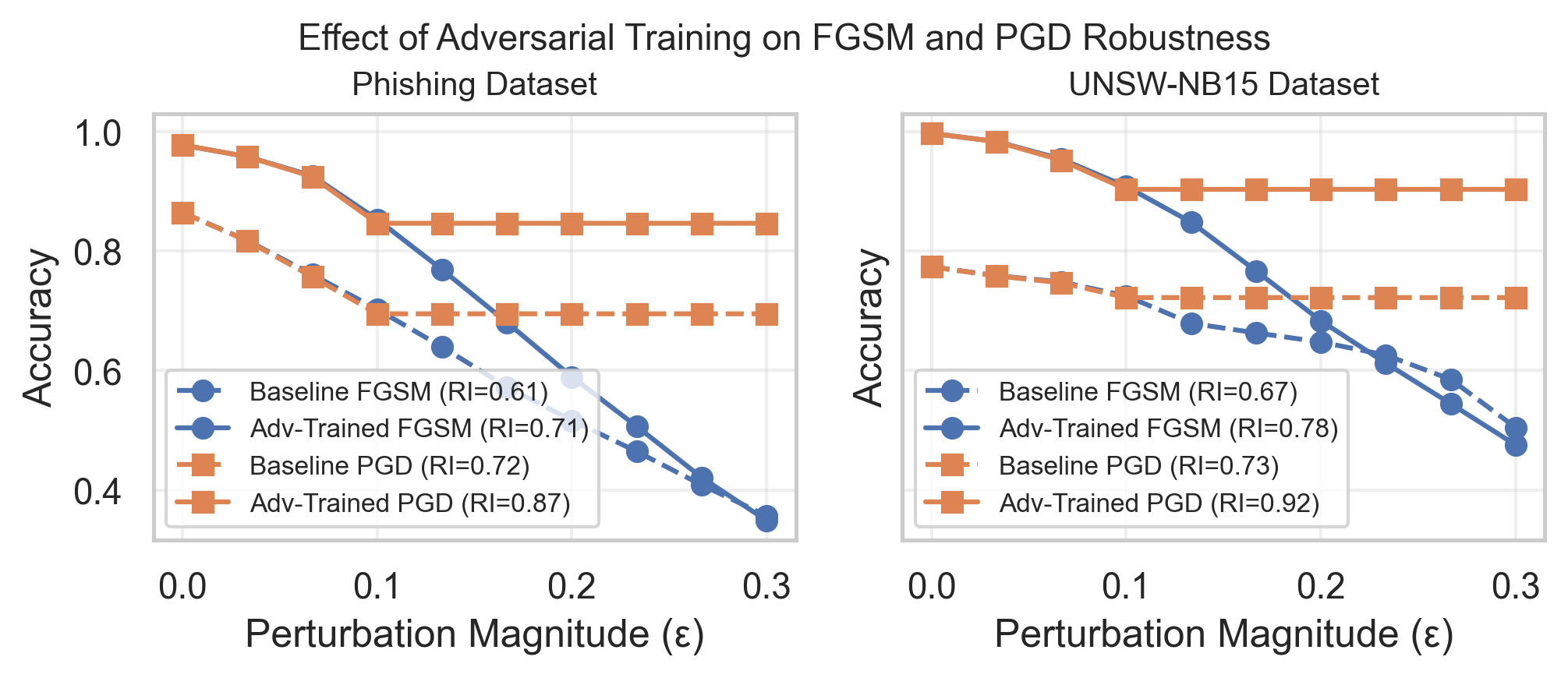
Adversarial training enhances machine learning model robustness by augmenting the training dataset with adversarial examples – inputs intentionally crafted to cause misclassification. This process exposes the model to perturbations it might encounter during deployment, forcing it to learn more resilient features. By training on both clean and adversarial examples, the model reduces its sensitivity to input noise and improves its ability to correctly classify data even when subjected to malicious manipulation. The technique effectively minimizes the decision boundary’s susceptibility to small, intentional changes in the input space, thereby improving generalization performance under attack.
Z-Score Normalization is a preprocessing technique applied to feature data prior to model training, specifically benefiting algorithms like Multilayer Perceptrons (MLPs). This method centers the data around a mean of zero and scales it to have a standard deviation of one, effectively standardizing feature ranges. By reducing the impact of varying feature scales, Z-Score Normalization improves the stability of the training process and can enhance model performance, particularly in scenarios where features exhibit significantly different ranges or distributions. The technique mitigates the dominance of features with larger magnitudes, allowing the model to learn more effectively from all input variables.
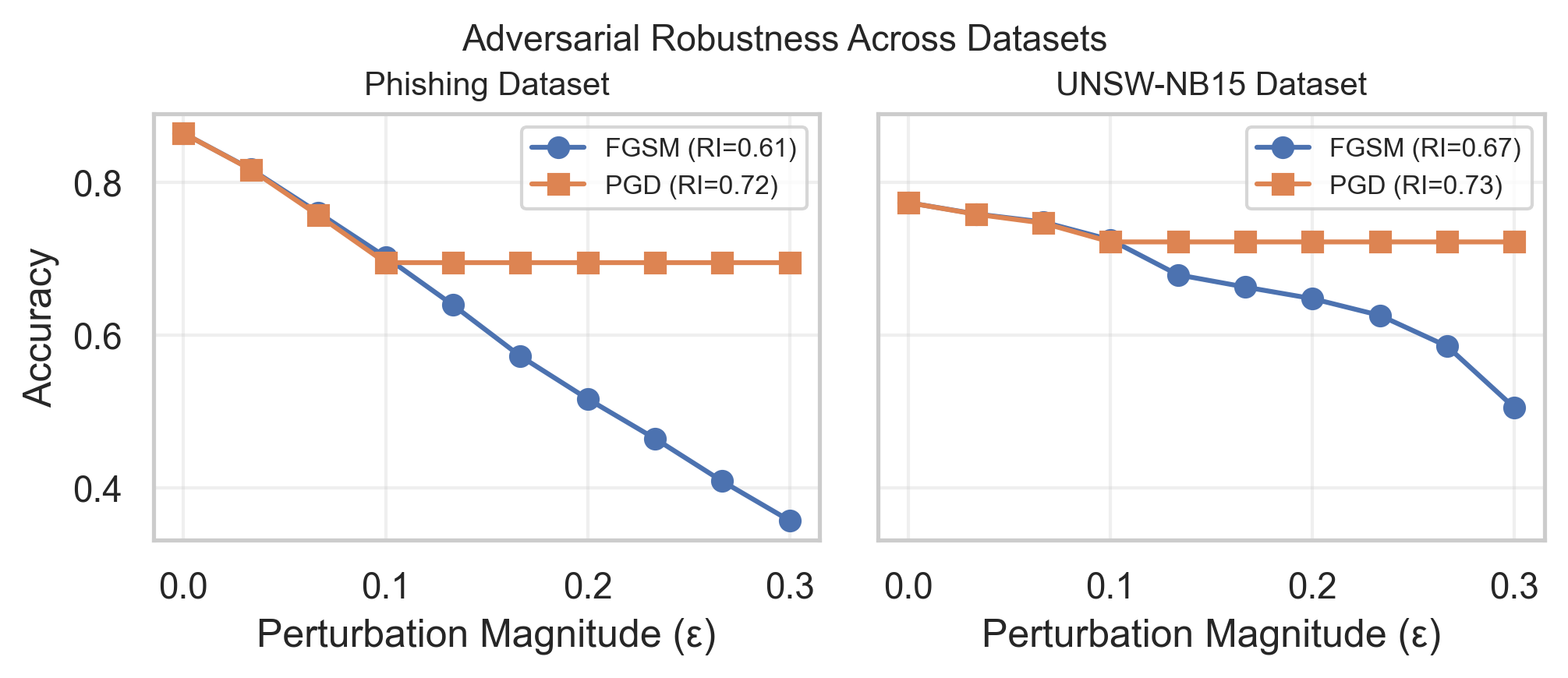
A Robustness Index (RI) has been developed to provide a standardized quantitative metric for evaluating the resilience of machine learning models against adversarial attacks. Empirical results demonstrate that implementing adversarial training can significantly improve a model’s RI score. Specifically, across phishing and intrusion detection datasets, adversarial training yielded RI increases of 0.10 for Phishing websites under Fast Gradient Sign Method (FGSM) attack, 0.15 with Projected Gradient Descent (PGD), 0.11 for the UNSW-NB15 dataset under FGSM, and a maximum improvement of 0.19 with PGD, indicating a measurable and consistent enhancement in robustness achieved through this training technique.
Adversarial training demonstrably improves model robustness, as quantified by the Robustness Index (RI). Empirical results indicate a performance increase of 0.10 in RI for models evaluating Phishing websites subjected to the Fast Gradient Sign Method (FGSM) attack, and 0.15 when attacked with the Projected Gradient Descent (PGD) method. Similarly, performance on the UNSW-NB15 dataset improved by 0.11 with FGSM and 0.19 with PGD attacks, following adversarial training implementation. These RI values represent the measured increase in resilience achieved through the inclusion of adversarial examples during the model training process.
Future Directions: Securing the Next Generation of AI
Advancing the field of artificial intelligence requires a concentrated effort on bolstering the resilience of machine learning models against adversarial attacks. Current adversarial training methods, while effective in principle, often demand substantial computational resources and struggle to scale with increasingly complex models and datasets. Researchers are actively investigating techniques to improve this efficiency, including methods that prioritize identifying the most impactful perturbations during training and developing more streamlined optimization algorithms. Innovations in areas like knowledge distillation and transfer learning offer promising avenues for reducing the computational burden while maintaining robust performance. Ultimately, the development of scalable and efficient adversarial training is paramount for deploying trustworthy AI systems in real-world applications where security and reliability are critical.
The true test of any adversarial training technique lies in its performance against authentic threats, necessitating application to real-world cybersecurity datasets. Researchers are increasingly focusing on benchmarks like the UNSW-NB15 Dataset, which simulates modern network traffic including malicious activity, and datasets comprised of actual phishing websites. Evaluating AI models on these resources allows for a quantifiable assessment of their resilience against evolving cyberattacks, moving beyond theoretical robustness to practical efficacy. Success in these trials isn’t simply about achieving high accuracy; it requires demonstrating sustained performance even when confronted with the nuanced and cleverly disguised threats present in these datasets, ultimately building confidence in the dependability of next-generation AI security systems.
The development of truly reliable artificial intelligence necessitates a shift in focus towards both robustness and interpretability. Systems demonstrating robustness consistently maintain performance even when confronted with unexpected or adversarial inputs, crucial for security applications where malicious actors actively seek to exploit vulnerabilities. However, performance alone is insufficient; interpretability – the ability to understand why an AI system reached a particular conclusion – is equally vital. Without it, potential biases or flawed reasoning remain hidden, eroding trust and hindering effective deployment in critical domains. Prioritizing these qualities isn’t merely about building more accurate algorithms, but about forging AI systems that are demonstrably safe, accountable, and aligned with human values, ultimately paving the way for a more secure and beneficial digital future.
The study meticulously dissects the vulnerabilities inherent in cybersecurity classifiers, revealing a concerning drift in explainability as adversarial robustness increases. This pursuit of fortification, while necessary, often introduces complexity, obscuring the very mechanisms intended to safeguard systems. As Bertrand Russell observed, “The point of education is to teach people to think, not to memorize facts.” Similarly, this research emphasizes that simply building robust models is insufficient; understanding how those models arrive at decisions – maintaining interpretability – is crucial. The framework proposed isn’t merely about defending against attacks, but about illuminating the decision-making process itself, resisting the temptation to trade clarity for perceived security.
Where Do We Go From Here?
The pursuit of adversarial robustness in cybersecurity classifiers often resembles an escalating arms race, each defense prompting a more ingenious attack. This work, while valuable in mapping the interplay between robustness and explainability, doesn’t so much solve the problem as illuminate its inherent complexity. They called it a framework to hide the panic, perhaps, but a simpler truth emerges: perfect security, like perfect explanation, is an asymptotic ideal. The focus now must shift from simply detecting perturbations to understanding why certain features prove so susceptible, and whether that susceptibility is a symptom of a deeper flaw in the modeling process itself.
Current methods largely treat interpretability-SHAP values, feature sensitivity analyses-as an afterthought, a diagnostic tool applied to a finished system. A more fruitful path lies in building interpretability into the model from the start. Constraints on model complexity, a willingness to sacrifice marginal accuracy for demonstrable clarity, and a rejection of opaque, overparameterized architectures could yield surprisingly resilient systems. The field too often chases novelty; it might benefit from a period of enforced austerity.
Finally, the reliance on perturbation analysis, while necessary, risks becoming a local maximum. Adversaries will, inevitably, adapt. Future work should explore methods for assessing generalizable robustness-a classifier’s ability to maintain performance across a broader range of unforeseen threats-rather than optimizing for specific attack vectors. The goal is not merely to withstand today’s assault, but to build a foundation for enduring security.
Original article: https://arxiv.org/pdf/2602.06395.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- How to Get to the Undercoast in Esoteric Ebb
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- TikToker’s viral search for soulmate “Mike” takes brutal turn after his wife responds
- All Itzaland Animal Locations in Infinity Nikki
- ‘Timur’ Trailer Sees Martial Arts Action Collide With a Real-Life War Rescue
- Mewgenics vinyl limited editions now available to pre-order
- Gold Rate Forecast
2026-02-09 17:10