Author: Denis Avetisyan
Researchers have developed a novel framework that boosts the accuracy and interpretability of how large language models assess the likelihood of their predictions.
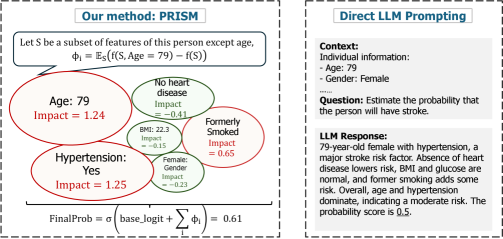
The PRISM framework utilizes Shapley values to provide feature attribution and improve calibration in probability estimation with large language models.
While Large Language Models (LLMs) hold promise for quantifying the probability of real-world events, their outputs are often unreliable and lack transparency. This work, ‘Interpretable Probability Estimation with LLMs via Shapley Reconstruction’, introduces PRISM, a novel framework that enhances both the accuracy and interpretability of LLM-based probability estimation by leveraging Shapley values to decompose and reconstruct predictions. Our experiments demonstrate PRISM’s superior performance across diverse domains, providing calibrated estimates and revealing the key factors driving each prediction. Could this approach unlock trustworthy, data-driven decision support systems in fields demanding nuanced probabilistic assessments?
The Illusion of Confidence: Unmasking Miscalibration
Despite achieving impressive accuracy on numerous tasks, contemporary machine learning models frequently struggle to provide reliable probability estimates. This disconnect between predictive performance and confidence scoring arises because models are typically optimized to minimize classification error, not to accurately reflect the true likelihood of an event. Consequently, a model might confidently predict a 90% probability for an outcome that, in reality, only occurs 60% of the time – a manifestation of overconfidence. Conversely, underestimation of risk is also common, where models express low confidence in predictions they actually get right. This miscalibration poses significant challenges, particularly in fields like medical diagnosis or financial modeling, where decisions are heavily influenced by the assessed probabilities, and inaccurate confidence levels can lead to suboptimal – or even dangerous – outcomes.
The consequences of miscalibrated confidence scores extend far beyond simple inaccuracies; they fundamentally jeopardize decision-making processes in high-stakes applications. Consider medical diagnosis, where an overconfident algorithm might falsely assure a clinician of a negative result, delaying crucial treatment, or in autonomous vehicles, where underestimation of risk could lead to unsafe maneuvers. These systems rely on probabilities not merely to make predictions, but to quantify the uncertainty surrounding those predictions, informing appropriate action. A miscalibration, therefore, isn’t just a statistical quirk-it’s a functional failure, eroding trust and potentially leading to catastrophic outcomes where accurate assessment of likelihood is paramount for safety, resource allocation, and responsible automation.
The pursuit of reliable prediction extends far beyond simply achieving high accuracy; a model can correctly identify outcomes while still providing misleading confidence estimates. Ideally, a prediction with an assigned probability of 70% should, over many similar events, occur approximately 70% of the time; however, many current machine learning methods deviate significantly from this expectation, producing what’s known as miscalibration. This disconnect between predicted probability and actual likelihood poses a critical problem, particularly in high-stakes fields like medical diagnosis or financial risk assessment, where decision-making relies heavily on the trustworthiness of these confidence scores. Current calibration techniques, while offering some improvement, often struggle to consistently align predicted probabilities with observed event frequencies across diverse datasets and complex models, highlighting the ongoing challenge of building truly reliable predictive systems.
Deconstructing Prediction: The Principles of PRISM
PRISM achieves probabilistic reconstruction by disassembling a model’s prediction into additive contributions representing the influence of each input factor. This decomposition allows for a granular understanding of the reasoning behind a specific prediction, moving beyond a simple output value to reveal the relative importance of each feature. The resulting attribution scores quantify how much each factor contributed to the predicted probability, facilitating interpretability and enabling users to trace the decision-making process of the model. This approach contrasts with black-box models where the basis for predictions remains opaque, and provides a mechanism for verifying model behavior and identifying potential biases or unexpected dependencies.
PRISM utilizes Shapley Values, a concept from cooperative game theory, to determine the contribution of each input feature to a model’s prediction. Shapley Values calculate the average marginal contribution of a feature across all possible combinations of other features; this ensures a fair and consistent attribution of predictive power. Specifically, for a given prediction, the Shapley Value for a feature is computed by considering all possible subsets of the remaining features, training the model on each subset with and without the target feature, and averaging the difference in prediction performance. This process yields a value representing the feature’s average impact, effectively quantifying its importance in the model’s decision-making process. The \phi_i represents the Shapley value for feature i.
PRISM demonstrates adaptability across diverse data types by utilizing a unified framework for feature attribution. The method operates on both structured, tabular datasets where features are explicitly defined, and unstructured text data, where features are extracted through techniques like word embeddings or topic modeling. This capability is achieved by representing all input features as a coalition in the Shapley Value calculation, regardless of their origin or data type. Consequently, PRISM can be applied to a wider range of machine learning models and datasets without requiring specific data pre-processing or feature engineering tailored to the data’s structure.

Revealing the Logic: Feature Contributions in Detail
PRISM utilizes contrastive explanations by assessing the change in a model’s prediction when a specific feature, or set of features, is removed from the input data. This is achieved by comparing the prediction on the original instance to the prediction on a modified instance lacking the target feature(s). The magnitude and direction of this predictive shift directly quantifies the feature’s influence; a substantial change indicates a strong contribution, while minimal variation suggests a lesser impact. This technique moves beyond simply identifying feature importance and allows for a granular understanding of how each feature actively contributes to the model’s output, revealing the feature’s true effect on the prediction.
PRISM’s analytical robustness is achieved through the use of a reference instance, which serves as a stable baseline for comparison when assessing feature contributions. By calculating the difference in prediction between the input instance and a perturbed version lacking a specific feature – relative to the difference between the reference instance and the same perturbed version – PRISM normalizes the impact of feature removal. This normalization mitigates the influence of inherent differences in scale or distribution between individual instances, preventing disproportionate weighting of features based on instance-specific characteristics. Consequently, the resulting feature attributions are more stable and representative of the feature’s general influence across the dataset, rather than its effect on a single, potentially anomalous example.
PRISM’s methodology explicitly addresses feature interactions by evaluating changes in model predictions not solely based on feature removal, but in the context of other features’ values. This is achieved through iteratively comparing predictions with and without a feature, while systematically varying the values of remaining features to observe conditional effects. By quantifying how the impact of a feature shifts depending on the state of others, PRISM avoids attributing predictive power incorrectly to individual features acting in isolation. The resulting interaction effects are then incorporated into the overall feature contribution score, providing a more accurate representation of each feature’s true influence on the model’s output.

Beyond Accuracy: Establishing Trust Through Calibration
PRISM addresses a critical challenge in machine learning: the misalignment between predicted probabilities and actual outcomes. Traditional models often fail to account for the inherent distribution of classes within a dataset – a phenomenon known as dataset prevalence. This method directly incorporates this true distribution to recalibrate predicted probabilities, effectively weighting them based on how frequently each class appears in reality. By acknowledging that rarer events are naturally harder to predict accurately, PRISM mitigates biases stemming from imbalanced datasets and ensures that predicted probabilities more closely reflect the true likelihood of an event. This recalibration not only improves the overall accuracy of predictions but also yields well-calibrated probabilities, crucial for reliable decision-making in applications where understanding the confidence of a prediction is paramount.
PRISM demonstrates remarkable versatility across a spectrum of machine learning applications, effectively managing both tabular and more complex data types and skillfully capturing nuanced feature interactions. Rigorous testing on benchmark datasets-including those focused on Adult Census, Heart Disease diagnosis, Lending risk assessment, and Stroke prediction-reveals that the method consistently achieves Area Under the Receiver Operating Characteristic curve (AUROC) scores competitive with, and often exceeding, those of existing state-of-the-art techniques. This broad applicability, coupled with consistently high performance, suggests PRISM is a robust solution for improving predictive accuracy and reliability in diverse real-world scenarios, extending beyond any single, specialized task.
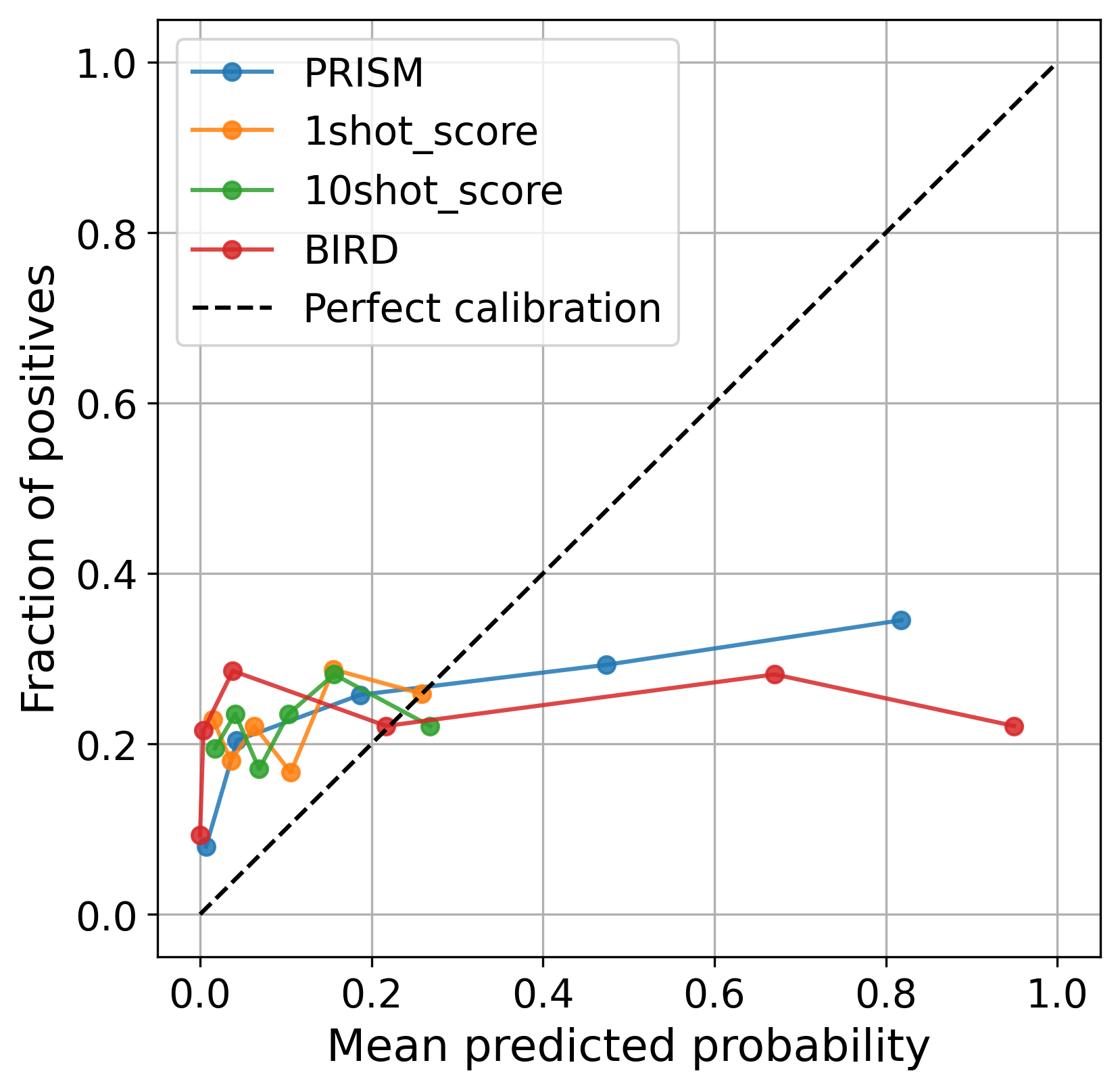
PRISM distinguishes itself by not only predicting outcomes but also quantifying the certainty behind those predictions, delivering probabilities that accurately reflect real-world frequencies. This focus on well-calibrated probabilities is crucial for building trust in machine learning systems, as it allows stakeholders to understand the level of confidence associated with each prediction and make more informed decisions accordingly. Rigorous testing demonstrates PRISM consistently aligns its predicted probabilities with observed outcomes across diverse datasets – from financial lending to healthcare diagnostics – remaining remarkably close to a perfect ‘reliability curve’ where predictions are as confident as they are accurate. This consistency, coupled with the interpretability of its probabilistic outputs, positions PRISM as a valuable tool for applications demanding both high performance and dependable uncertainty estimates.

The pursuit of reliable probability estimation, as detailed in this work concerning PRISM and Shapley values, echoes a fundamental tenet of rigorous computation. It isn’t sufficient for a model to appear calibrated; its estimations must be demonstrably sound, built upon provable foundations. As Marvin Minsky observed, “You can’t always get what you want, but you can try to understand why.” This sentiment applies directly to the core idea of the paper-understanding why a Large Language Model assigns a particular probability is as crucial as the accuracy of that probability itself. The framework aims to move beyond opaque predictions, revealing the underlying logic and ensuring that estimations aren’t merely statistical coincidences, but reflect genuine understanding of the input data.
What’s Next?
The pursuit of calibrated probability estimation from large language models, as exemplified by PRISM, remains a fundamentally difficult undertaking. The framework’s reliance on Shapley values, while theoretically sound, introduces computational burdens that scale poorly with model size and input complexity. The elegance of the mathematical formulation does not automatically translate to practical efficiency; a troubling, yet predictable, disconnect. Future work must address this scalability, perhaps through approximation techniques that sacrifice a degree of precision for computational tractability – a compromise that speaks more to engineering limitations than to algorithmic shortcomings.
More importantly, the very notion of ‘explainability’ requires re-evaluation. Attributing probabilities to input features, even with mathematical rigor, does not necessarily reveal why a model makes a particular prediction. It merely describes what features contribute. The quest for genuine understanding demands a move beyond feature attribution, toward a deeper investigation of the internal representations and decision boundaries within these models – a task that will likely require entirely new mathematical tools.
Ultimately, the success of approaches like PRISM will be judged not by their ability to mimic human intuition, but by their demonstrable correctness. A beautifully calibrated probability is meaningless if the underlying model remains a black box, operating on principles that defy logical scrutiny. The field must prioritize provability over performance, seeking solutions that are mathematically sound, even if they are less efficient in the short term.
Original article: https://arxiv.org/pdf/2601.09151.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Crimson Desert Guide – How to Pay Fines, Bounties & Debt
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
2026-01-16 00:26