Author: Denis Avetisyan
A new study explores whether large language models can effectively translate the complex logic behind credit risk predictions into human-understandable explanations.
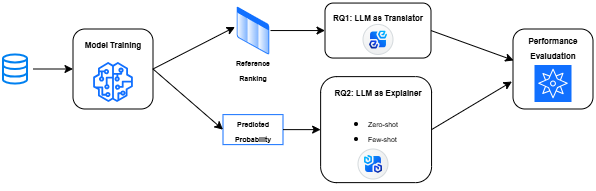
Research indicates large language models excel at reproducing explanations but struggle with independent interpretation of feature importance in credit risk models.
Despite increasing regulatory scrutiny, translating complex credit risk model outputs for non-technical stakeholders remains a persistent challenge. This paper, ‘Could Large Language Models work as Post-hoc Explainability Tools in Credit Risk Models?’, investigates whether large language models (LLMs) can bridge this communication gap by functioning as post-hoc explainers through in-context learning. Our findings demonstrate that while LLMs excel at translating existing model attributions into narrative explanations, their capacity to autonomously infer feature importance is limited. Could this position LLMs not as replacements for rigorous explainability techniques, but as powerful interfaces for democratizing access to model insights within credit risk governance frameworks?
Navigating the Opacity of Modern Credit Risk Models
Contemporary credit risk assessments increasingly rely on powerful machine learning algorithms, such as XGBoost, celebrated for their remarkable predictive capabilities. However, this enhanced accuracy comes at a cost: a significant lack of transparency. These models operate as ‘black boxes’, meaning the complex interactions of numerous variables make it difficult, if not impossible, to discern why a particular credit decision was reached. While highly effective at identifying risk, the internal logic remains obscured, presenting challenges for both regulators demanding accountability and applicants seeking clear explanations for adverse decisions. This opacity isn’t a flaw in the algorithms themselves, but rather an inherent trade-off between model complexity and human understanding, prompting a search for techniques that can illuminate these intricate processes.
The lack of transparency in modern credit risk models presents significant challenges to both consumer trust and regulatory adherence. When a credit application is denied by a complex ‘black box’ algorithm, individuals are often left without a clear understanding of the factors contributing to that decision, fostering distrust in the financial institution. Simultaneously, regulations such as the Equal Credit Opportunity Act demand that lenders provide specific, justifiable reasons for adverse actions. Failing to do so – particularly when explanations rely on the inscrutable inner workings of a machine learning model – can lead to legal repercussions and damage to a lender’s reputation. This necessitates a careful consideration of explainability alongside predictive power, prompting research into methods that can illuminate the decision-making processes of these increasingly sophisticated algorithms.
While techniques like Logistic Regression offer the benefit of clear, understandable predictions – revealing exactly how each factor influences a decision – their simplicity often limits performance when faced with the intricate patterns of modern credit risk. These traditional methods struggle to capture non-linear relationships and complex interactions within data, leading to lower accuracy compared to more sophisticated, yet opaque, algorithms. Consequently, a critical challenge arises in selecting models; it’s no longer simply about maximizing predictive power, but about finding the optimal equilibrium between a model’s ability to accurately assess risk and the crucial need for transparency and justification in lending decisions. This balance is vital for maintaining trust with applicants and satisfying increasingly stringent regulatory requirements.
Unveiling the Drivers: Feature Importance Techniques
Post-hoc Explainable AI (XAI) techniques, including SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations), function by creating simplified representations of a trained machine learning model’s decision-making process. These methods do not alter the model itself; instead, they analyze the model’s existing behavior to estimate how each input feature influences its predictions for specific instances or globally. SHAP utilizes principles from game theory to assign each feature a value representing its contribution to the prediction, while LIME approximates the model locally with a simpler, interpretable model – typically a linear model – around the prediction of interest. Both techniques aim to provide insights into why a model made a particular prediction, enabling users to understand the key drivers behind its output and assess its trustworthiness.
Feature Importance Ranking, central to post-hoc Explainable AI techniques, assigns a numerical value to each input feature, representing its contribution to the model’s predictive output. This quantification is typically achieved by assessing the change in model prediction when a feature’s value is perturbed or removed. Higher absolute values in the ranking indicate a stronger influence on the model’s decisions; features with values near zero suggest minimal impact. The specific method for calculating this contribution varies – SHAP values, for example, utilize game-theoretic principles to distribute prediction differences, while LIME employs local linear approximations – but the ultimate goal is to provide a relative ordering of feature significance, enabling users to understand which variables are driving the model’s behavior.
Robust data preprocessing is critical for reliable feature importance rankings derived from post-hoc explainable AI techniques. Data quality issues – including missing values, outliers, and inconsistencies – can introduce noise and bias into the model, distorting the calculated feature contributions. Specifically, inconsistent data scaling or categorical variable encoding can disproportionately inflate or deflate the perceived importance of certain features. Furthermore, insufficient data cleaning can lead to model instability, resulting in fluctuating feature rankings across different model training runs or slight data variations. Addressing these issues through techniques like imputation, outlier removal, normalization, and appropriate encoding schemes ensures that the derived feature importances accurately reflect the true relationships within the data and provide a stable basis for model interpretation.
Bridging the Gap: Leveraging Language Models for Explanation
Large Language Models (LLMs) present a new method for converting quantitative feature importance scores into explanations accessible to human users. Traditional feature importance techniques often output numerical values or simple rankings, requiring significant interpretation to understand the underlying drivers of a model’s predictions. LLMs, however, can ingest these feature importance values – or the data used to derive them – and generate natural language explanations detailing why specific features are influential. This capability bypasses the need for manual interpretation and allows for the creation of customized explanations tailored to different stakeholder groups, potentially improving model transparency and trust. The core innovation lies in the LLM’s ability to map abstract numerical importance to concrete, human-interpretable rationales.
Large Language Models (LLMs) facilitate explanation generation through In-Context Learning, a process where the LLM adapts its output based on provided examples within the prompt. This allows for audience-specific explanations by conditioning the model on demonstrations of desired explanation styles or levels of detail. Two primary prompting strategies are employed: Zero-Shot Prompting, which requests an explanation without providing examples, and Few-Shot Prompting, which includes a limited number of input-explanation pairs to guide the LLM’s response. The efficacy of these methods depends on the complexity of the data and the desired granularity of the explanation; however, both approaches leverage the LLM’s pre-trained knowledge and ability to generalize from limited data to produce coherent and contextually relevant explanations.
Our research indicates that Large Language Models (LLMs) exhibit a high capacity for reproducing provided feature importance rankings. Specifically, when supplied with reference rankings, LLMs consistently achieved near-perfect overlap – approaching a 1.0 score – for the top-K features identified as most influential. However, performance significantly diminishes when LLMs are tasked with independently generating feature importance rankings without any pre-existing reference attributions; in these scenarios, the generated rankings often fail to align with established ground truth or expert evaluations, indicating a reliance on provided examples rather than inherent analytical capability.
Toward Responsible AI: Enhancing Risk Management and Validation
The integration of Large Language Models (LLMs) with post-hoc Explainable AI techniques represents a significant advancement in bolstering model risk management practices. By leveraging LLMs to interpret and articulate the reasoning behind model predictions, organizations gain a deeper understanding of potential biases, vulnerabilities, and unexpected behaviors. This synergy allows for more effective model validation, as explanations can be scrutinized for logical consistency and alignment with domain expertise. The resulting transparency not only fosters trust in model outputs but also facilitates proactive identification and mitigation of risks, ultimately enhancing the reliability and responsible deployment of increasingly complex machine learning systems. This approach moves beyond traditional statistical validation to encompass a more nuanced, human-understandable assessment of model behavior.
Rigorous validation of model explanations is crucial when deploying updated versions of machine learning models, and statistical tests offer a quantitative approach to ensure consistency. Researchers are increasingly employing techniques like the Kolmogorov-Smirnov statistic to compare the distributions of feature importances or other explanation metrics between different model iterations. This test determines whether two samples-in this case, explanations from two models-are drawn from the same distribution, providing a measurable indication of whether the models are relying on similar reasoning. A statistically significant difference suggests a shift in the model’s decision-making process, prompting further investigation into potential risks or unintended consequences associated with the updated version. By establishing a formal statistical framework for explanation validation, organizations can enhance model risk management and maintain confidence in the reliability of their deployed systems.
Analysis reveals a crucial limitation in leveraging Large Language Models for feature importance explanation: the accuracy of reproducing feature rankings diminishes as the number of ranked features-represented by ‘K’-increases. This suggests that while LLMs can effectively identify the most influential factors driving a model’s decisions, their reliability decreases when attempting to comprehensively rank a larger set of features. Consequently, focusing analytical efforts and validation procedures on the top-K features-those deemed most important-provides a more robust and dependable approach to model explainability and risk management, ensuring that insights remain consistent and trustworthy even as model complexity grows.
The study highlights a critical limitation of large language models: their reliance on provided information rather than genuine inference. This echoes Aristotle’s observation that “The ultimate value of life depends upon awareness and the power of contemplation rather than merely upon mere survival.” While LLMs excel at translating existing explanations-reproducing feature importance rankings as the paper demonstrates-they falter when tasked with independently determining those rankings. This isn’t a failure of technical capability, but a reinforcement of a fundamental philosophical point: efficiency without understanding-or, in this case, explanation derived from true insight-is ultimately an illusion. The research subtly suggests that LLMs, in the realm of credit risk model explainability, function best as sophisticated interfaces, translating existing interpretations rather than generating novel ones.
Where Do We Go From Here?
The pursuit of explainable AI often feels like a translation exercise – converting the opaque logic of algorithms into human-understandable terms. This work suggests large language models excel at performing that translation, provided the underlying meaning is already established. However, the inability of these models to independently deduce feature importance raises a critical point: are they truly explaining, or simply mirroring pre-existing interpretations? The risk lies in mistaking fluency for understanding, particularly within high-stakes domains like credit risk assessment.
Future research should move beyond evaluating the accuracy of explanations and focus on their robustness. How susceptible are LLM-generated explanations to adversarial manipulation, or subtle shifts in the underlying model? Furthermore, a crucial, often overlooked question pertains to the values encoded within these explanations themselves. Data itself is neutral, but models reflect human bias, and tools without values are weapons. Simply making a decision seem transparent does not guarantee it is just.
The long-term trajectory may not lie in automating explanation entirely, but in augmenting human expertise. LLMs could serve as powerful interfaces, facilitating dialogue between models and decision-makers, but always with a critical human in the loop – one equipped to question, interpret, and ultimately, take responsibility for the outcomes. Progress without ethics is acceleration without direction, and in the realm of automated decision-making, the destination matters profoundly.
Original article: https://arxiv.org/pdf/2602.18895.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
- Does Mark survive Invincible vs Conquest 2? Comics reveal fate after S4E5
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Crimson Desert Guide – How to Pay Fines, Bounties & Debt
2026-02-24 12:35