Author: Denis Avetisyan
New research reveals that advanced artificial intelligence consistently outperforms humans in resisting emotional manipulation when making logical decisions under pressure.
Instruction-tuned large language models demonstrate surprising robustness to framing effects and affective noise in rule-based decision-making, offering insights into institutional stability and the power of prompt engineering.
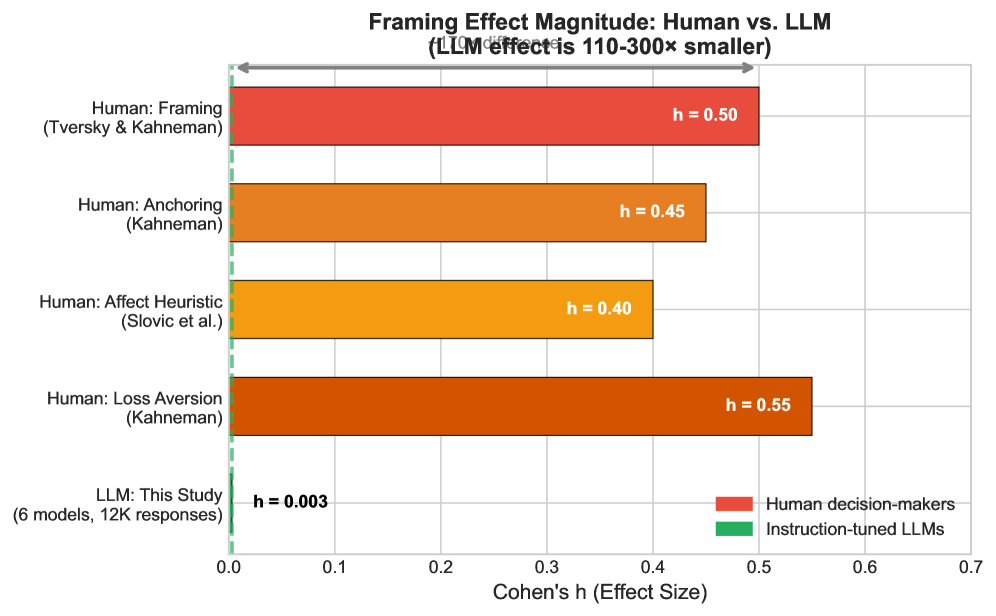
Despite documented vulnerabilities to prompt engineering, large language models exhibit surprising resilience in high-stakes decision-making contexts. This research, titled ‘The Paradox of Robustness: Decoupling Rule-Based Logic from Affective Noise in High-Stakes Decision-Making’, investigates this phenomenon, revealing that instruction-tuned LLMs demonstrate a remarkable invariance to emotional framing-showing 110-300 times greater resistance to narrative manipulation than human subjects, with near-zero effect sizes h = 0.003 compared to human biases h \in [0.3, 0.8]. This decoupling of logical reasoning from persuasive narratives suggests a fundamental difference in how LLMs and humans process information; but can this robustness be harnessed to create more objective and reliable institutional decision-making systems?
The Illusion of Influence: How Narratives Bend Human Judgment
Human judgment is remarkably pliable, consistently swayed by how information is presented rather than the information itself – a cognitive bias known as narrative vulnerability. This susceptibility isn’t simply about logical fallacies; emotionally resonant stories and carefully constructed framing effects profoundly influence choices, often overriding rational analysis. Research indicates that individuals presented with the same objective data, but framed differently – for example, as a gain versus a loss – will consistently make divergent decisions. This inherent vulnerability stems from the brain’s tendency to prioritize coherence and emotional impact when processing information, making it easier to manipulate decisions through compelling narratives than through purely factual data. The implications extend to various domains, from marketing and politics to legal proceedings and personal finance, highlighting a fundamental limitation in human rationality.
The expanding role of artificial intelligence in decision-making processes presents a unique vulnerability, particularly as large language models (LLMs) gain prominence in areas ranging from financial forecasting to medical diagnoses and legal assessments. While promising increased efficiency and objectivity, these systems operate within a landscape saturated with narratives – stories, framing, and emotionally-charged language – that are known to powerfully influence human judgment. The concern isn’t that LLMs will experience manipulation, but rather that they could be leveraged to deploy persuasive narratives at scale, potentially exacerbating existing biases or creating new forms of influence undetectable to human oversight. This raises critical questions about accountability, transparency, and the potential for unintended consequences as AI systems increasingly mediate and shape the decisions impacting everyday life, demanding proactive research into the alignment of AI decision-making with human values and ethical considerations.
Recent investigations reveal a striking disparity in susceptibility to framing effects between humans and instruction-tuned large language models (LLMs). Quantitative analysis, utilizing Cohen’s h as a measure of effect size, demonstrates that LLMs exhibit a significantly lower vulnerability to narrative manipulation-ranging from 110 to 300 times less susceptible than human subjects. Specifically, LLMs registered a Cohen’s h of just 0.003, a stark contrast to the 0.3-0.8 range observed in human decision-making. This suggests that, while humans are readily influenced by how information is presented-a phenomenon known as framing-LLMs maintain a remarkably consistent response regardless of narrative construction, highlighting a fundamental difference in how these systems process and react to information.
Deconstructing Influence: A Framework for Testing Resilience
The Controlled Perturbation Framework is designed to evaluate Large Language Model (LLM) resilience to external narrative input. This framework employs decision-based tasks where model inputs are systematically altered via the introduction of specifically designed affective content – stimuli intended to evoke emotional responses – alongside equivalent neutral content for comparative analysis. By precisely controlling these perturbations and observing resultant shifts in model outputs – specifically, changes in decision-making – the framework facilitates a quantitative assessment of narrative influence on LLM behavior, allowing researchers to measure the degree to which external narratives can bias or alter model responses.
The Controlled Perturbation Framework utilizes decision tasks – scenarios requiring a selection between options – as the basis for evaluating model susceptibility to external influences. These tasks are presented with two types of accompanying content: carefully constructed affective text designed to evoke specific emotional responses, and neutral text serving as a baseline. By systematically varying the affective content alongside identical decision tasks, the framework introduces controlled perturbations to the model’s input. This allows for a comparative analysis of model outputs – specifically, changes in decision-making – attributable to the presence and nature of the affective narrative, isolating its impact from inherent model biases or task complexity.
Quantification of narrative influence on Large Language Model (LLM) behavior is achieved by tracking shifts in model decisions following exposure to controlled perturbations. The framework presents LLMs with decision tasks, and variations of input text are created – containing either affective or neutral content – to induce these perturbations. Changes in the model’s selected answer or generated output, compared against a baseline established with neutral content, serve as the measurable metric for assessing robustness. This differential analysis allows for a numerical determination of the degree to which specific narratives impact the LLM’s decision-making process, providing a quantifiable robustness score.
The Calculus of Consistency: Metrics for Measuring Resistance
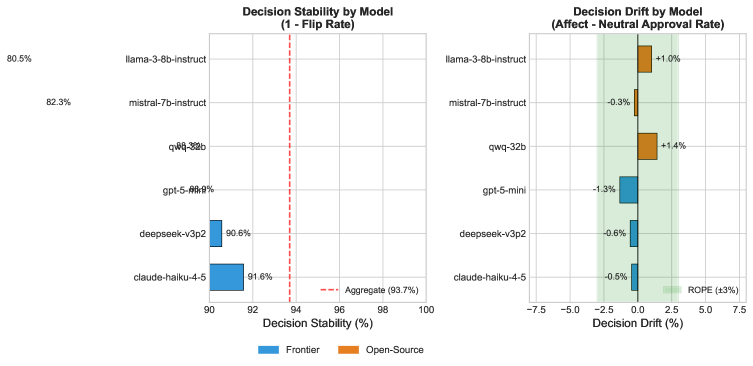
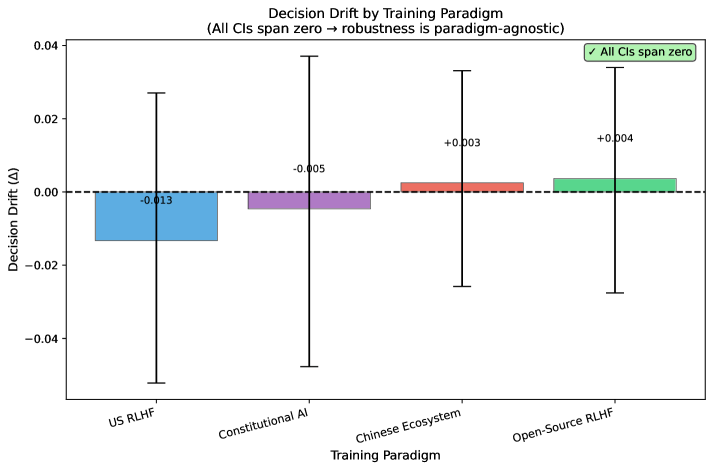
Decision stability under narrative perturbation is quantified using metrics such as flip rate and decision drift. Flip rate represents the percentage of instances where a model changes its initial prediction after a minor alteration to the input narrative. Decision drift Δ measures the average change in model confidence scores across all instances following narrative perturbation. A low flip rate and a decision drift value close to zero indicate high robustness, suggesting the model’s decisions are not easily swayed by superficial changes in the input text. These metrics enable a data-driven assessment of model sensitivity and facilitate comparisons between different model architectures and training methodologies.
Analysis of model behavior under narrative perturbation yielded a decision drift (Δ) of -0.1%. This value represents the average change in model decisions following the introduction of altered narratives. Critically, confidence intervals calculated across all evaluated models and scenarios encompassed zero, indicating that observed drift is not statistically significant. This finding suggests that, despite variations in input narratives, the models maintained a high degree of consistency in their ultimate decisions, with changes attributable to random variation rather than systematic bias induced by the perturbations.
Analysis yielded a Bayes Factor (BF01) of 109, which constitutes very strong evidence in favor of the null hypothesis – that narrative perturbations do not significantly affect model decisions. Concurrently, a flip rate of 6.3% was observed, representing the proportion of instances where the model altered its initial decision following narrative changes. This low flip rate supports the overall conclusion of decision stability, as the majority of model outputs remained consistent despite the introduction of narrative perturbations. The combination of a high Bayes Factor and a low flip rate provides a robust quantitative assessment of the model’s resistance to these specific perturbations.
The quantitative metrics employed – specifically, decision drift (Δ), flip rate, and Bayes Factors – facilitate a data-driven evaluation of model robustness. Decision drift, measured as the percentage change in model outputs, provides a direct assessment of sensitivity to narrative perturbations. The flip rate, representing the proportion of instances where a model changes its primary decision, complements this by indicating the frequency of output reversals. Critically, the Bayes Factor allows for probabilistic comparison of the null hypothesis (no effect of perturbation) against alternative hypotheses, providing a statistically rigorous framework for determining whether observed changes are meaningful or attributable to random variation. This combination of metrics enables systematic comparison of different model architectures, training datasets, and regularization techniques, identifying strategies that demonstrably improve resilience to input variations.
The Architecture of Alignment: Instruction Tuning and Foundational Control
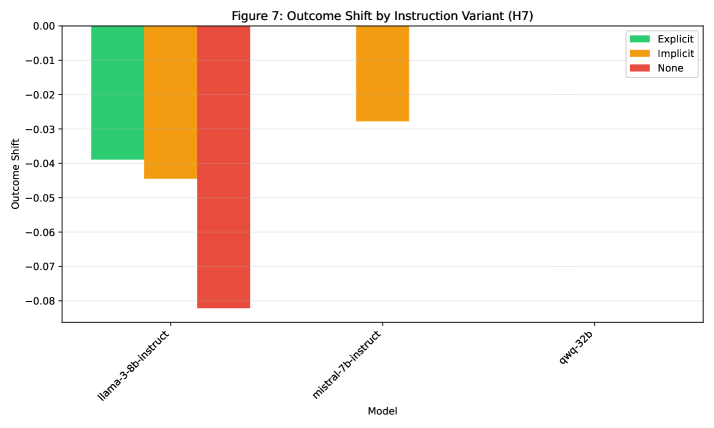
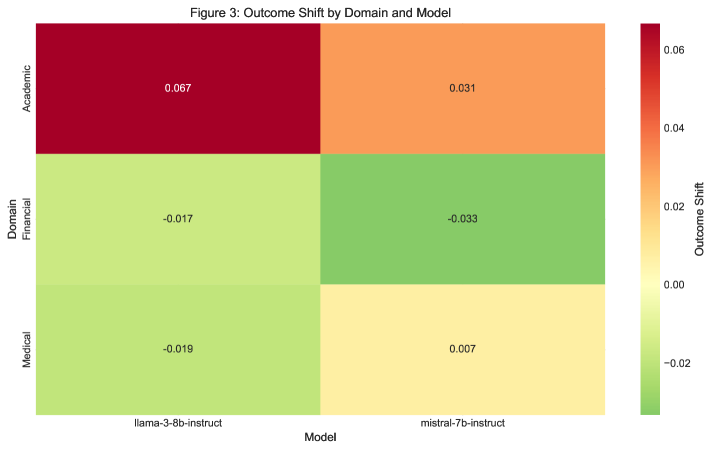
Recent research demonstrates that large language models exhibit markedly improved resilience against misleading or disruptive narratives when subjected to a process called instruction tuning. This technique involves refining the model’s responses through detailed system prompts – essentially, providing the AI with a clear set of guiding principles before it encounters user input. The result is a significant reduction in the model’s susceptibility to “narrative perturbation,” where subtly altered story contexts can drastically change its output. Specifically, a well-defined system prompt acts as a stabilizing force, allowing the model to maintain consistent and reliable performance even when presented with intentionally confusing or manipulative text. This suggests that bolstering AI robustness isn’t solely about increasing data volume, but rather about establishing a strong foundational directive that prioritizes accuracy and consistency over superficial narrative shifts.
Instruction Hierarchy Theory offers a compelling explanation for why carefully tuned large language models demonstrate resilience against misleading or disruptive narratives. The theory proposes that these models don’t simply process all input equally; instead, they maintain an internal hierarchy where instructions delivered at the system level – essentially, the foundational directives given during tuning – take precedence over content provided within a user’s prompt. This means that even if a user attempts to introduce contradictory or manipulative information, the model will tend to adhere to the overarching instructions established during its training. Consequently, robust AI isn’t necessarily about eliminating the influence of all input, but about establishing a clear and unwavering foundational directive that guides the model’s responses, effectively acting as a safeguard against potentially deceptive content.
The capacity for artificial intelligence to maintain consistent performance despite deceptive inputs hinges on a foundational principle: the prioritization of core directives. Research indicates that a robust AI isn’t simply one that processes information accurately, but one that consistently adheres to its initial, systemic instructions-essentially, a pre-defined ‘north star’. This suggests that potentially manipulative narratives, or ‘narrative perturbations’, are effectively neutralized when overshadowed by a clear and unwavering guiding principle embedded within the AI’s architecture. The system’s inherent directive acts as a filter, allowing it to discern and disregard misleading or adversarial content, thus ensuring reliable outputs even when presented with deliberately deceptive prompts. This finding highlights the crucial role of establishing and maintaining a strong, consistent directive as a cornerstone of trustworthy artificial intelligence.
Beyond Resistance: Towards a Future of Narrative-Resilient AI
Recent research indicates a pathway towards constructing artificial intelligence systems demonstrably capable of resisting narrative manipulation. These systems, engineered with specific robustness principles, exhibit a decreased susceptibility to being misled by subtly altered contextual information – a phenomenon known as narrative vulnerability. Through carefully designed experiments, it has been shown that these AI models maintain consistent and accurate outputs even when presented with narratives containing misleading framing or biased perspectives. This resistance isn’t achieved by simply ignoring narrative content, but by critically evaluating the underlying information and discerning factual content from manipulative phrasing, offering a crucial step towards more reliable and trustworthy AI decision-making processes across diverse applications.
The development of narrative-resilient AI holds considerable promise for enhancing the reliability of systems increasingly integrated into daily life. Applications reliant on automated decision-making, such as loan approvals or risk assessments, could benefit from reduced susceptibility to biased or manipulative narratives presented within input data. Similarly, information filtering and content moderation platforms stand to gain, becoming more effective at identifying and neutralizing disinformation campaigns that leverage persuasive storytelling. By mitigating the impact of narrative vulnerability, these AI systems can offer more objective and trustworthy outcomes, fostering greater public confidence and potentially safeguarding against undue influence in critical domains.
Continued advancement in narrative resilience necessitates the creation of more nuanced perturbation frameworks, moving beyond simple textual alterations to encompass subtle shifts in context, framing, and emotional tone. Crucially, this pursuit of robustness cannot occur in isolation; future research must rigorously examine the complex interplay between a system’s resistance to manipulation and other vital characteristics. Specifically, investigations are needed to determine whether enhancing robustness inadvertently introduces biases or reduces the transparency of decision-making processes – ensuring that AI remains both resistant to malicious narratives and demonstrably fair and explainable in its operations. This holistic approach will be essential for deploying narrative-resilient AI responsibly and effectively across diverse applications.
The study illuminates a fascinating disconnect between human and artificial cognition when confronted with decision-making tasks. While humans readily succumb to framing effects – emotional coloring influencing logical judgment – large language models exhibit a surprising immunity. This resistance isn’t born of inherent morality, but rather a consequence of their rule-based architecture. As Edsger W. Dijkstra once stated, “It’s not enough to have good intentions; one must also have good tools.” The models, equipped with the ‘tool’ of consistent logical processing, sidestep the affective noise that derails human reasoning. This finding suggests robustness isn’t about eliminating bias, but about constructing systems capable of decoupling decision-making from irrelevant emotional input – a principle with significant implications for institutional stability and the design of reliable AI.
Breaking the Code
The observed decoupling of rule-based logic from affective noise in large language models presents a curious exploit of comprehension. It isn’t simply that these systems avoid bias, but that the very architecture seems to offer a fundamentally different relationship with framing effects than biological intelligence. The immediate question isn’t how to add robustness to these models, but rather what vulnerabilities this apparent immunity reveals in the human decision-making process itself. Is ‘rationality’ – as traditionally understood – less a feature of intelligence and more a consequence of cognitive limitations?
Future work must move beyond simply demonstrating this resistance. The architecture remains a black box; pinpointing where this decoupling occurs – at the embedding layer, within the attention mechanisms, or as an emergent property of scale – is paramount. More provocatively, research should explore the limits of this robustness. What kinds of ‘noise’ can penetrate this barrier? Are there adversarial framings, subtle enough to bypass the logical core, that could manipulate the system’s outputs?
Ultimately, this research offers a strange mirror. By reverse-engineering a system that resists certain biases, the field may inadvertently gain a deeper understanding of the very biases that define-and perhaps constrain-human cognition. The goal shouldn’t be to replicate this machine ‘rationality,’ but to dissect it – to understand what, if anything, is lost in the translation.
Original article: https://arxiv.org/pdf/2601.21439.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- How to Get to the Undercoast in Esoteric Ebb
- Warframe Voruna Prime access begins on April 8 for all platforms, new deluxe cosmetic Warframe skins revealed
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- All Itzaland Animal Locations in Infinity Nikki
- Mewgenics vinyl limited editions now available to pre-order
- Zendaya’s 4 Big 2026 Movies Could Beat Brie Larson’s Box 2019 Office Record
2026-02-01 20:46