Author: Denis Avetisyan
Current AI safety benchmarks often fall short of accurately assessing real-world risks, prompting a need for more rigorous and nuanced evaluation methods.
This review critiques existing benchmarks and proposes a framework grounded in risk assessment, measurement theory, and sociotechnical systems analysis for more robust AI safety evaluation.
Despite the increasing urgency surrounding advanced AI, current safety benchmarks often lack the scientific rigor needed to reliably assess real-world risks. This paper, ‘How should AI Safety Benchmarks Benchmark Safety?’, critically examines 210 existing benchmarks, revealing shortcomings in their technical foundations and failure to account for complex sociotechnical factors. We argue that grounding evaluations in established risk management principles, robust probabilistic metrics, and rigorous measurement theory-along with a clear mapping of measurable harms-is crucial for developing truly valid and useful benchmarks. Can a more systematic and epistemologically sound approach to AI safety benchmarking ultimately foster more responsible AI deployment and mitigate emerging risks?
The Imperative of Comprehensive Risk Coverage
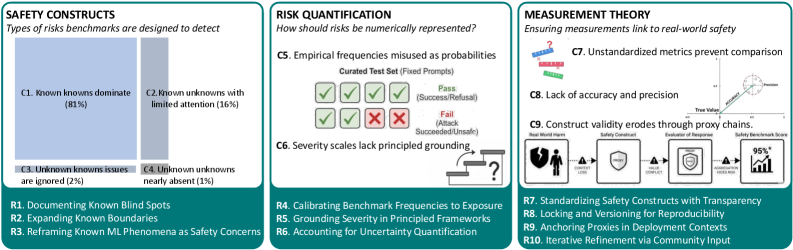
A significant gap exists in current artificial intelligence safety evaluation, as benchmarks demonstrably fail to provide comprehensive coverage of potential risks and failure modes. Recent analysis reveals that a substantial portion of these evaluations lack thoroughness; only approximately 34% explicitly document the risks they are not designed to assess. This omission creates a blind spot in safety protocols, as the absence of defined negative space implies an unwarranted assumption of complete coverage. Consequently, AI systems may be deployed with undetected vulnerabilities, potentially leading to unforeseen and harmful consequences in complex, real-world scenarios where unforeseen interactions can amplify even minor flaws. The limited scope of existing benchmarks suggests a critical need for more exhaustive and transparent risk assessment frameworks.
Conventional risk assessment techniques, designed for static systems with predictable failure modes, are increasingly inadequate when applied to modern artificial intelligence. These methods often struggle to account for the emergent behaviors and unintended consequences arising from complex AI algorithms interacting within dynamic sociotechnical systems – environments shaped by human behavior, social structures, and evolving technological landscapes. The interconnectedness of these systems introduces feedback loops and cascading effects that are difficult to model or anticipate with traditional approaches. Consequently, assessments frequently focus on narrow, well-defined risks, overlooking the broader, systemic vulnerabilities that could arise from AI deployment in real-world scenarios. This limitation highlights the need for novel evaluation frameworks capable of addressing the inherent uncertainties and complexities of AI operating within constantly changing contexts.
The current paradigm of AI safety evaluation frequently centers on identifying and mitigating known unknowns – risks that have been explicitly recognized as possibilities. However, this approach inherently overlooks the far more substantial category of unknown unknowns – those risks that haven’t even been conceptualized. This reliance on anticipating predictable failures creates a dangerous blind spot, as increasingly complex AI systems operating within multifaceted social environments are capable of exhibiting emergent behaviors and unforeseen consequences. Addressing this vulnerability necessitates a shift towards proactive, exploratory safety evaluations that prioritize identifying potential failure modes beyond current comprehension, demanding new methodologies capable of uncovering hidden risks before they manifest as real-world harms. A robust approach requires continuous monitoring, adversarial testing, and a willingness to embrace uncertainty as an inherent characteristic of advanced AI development.
Systemic Integrity: Beyond Component-Level Failures
System-Theoretic Process Analysis (STPA) diverges from traditional failure-based safety assessments by centering on the identification of unsafe control actions and the systemic factors that lead to them. Rather than focusing on component malfunctions in isolation, STPA models the entire system-including hardware, software, humans, and the environment-as a complex network of interacting components. This approach analyzes how interactions between these components can lead to hazardous system states, even if each component is functioning as designed. STPA utilizes a control structure to systematically identify potentially unsafe control actions, considering scenarios where controls are inadequate, provided incorrectly, or applied at the wrong time. The method emphasizes identifying causal factors arising from flawed system design, rather than attributing failures to individual component defects, offering a more comprehensive and proactive safety evaluation.
AI system safety evaluation must extend beyond purely technical assessments to encompass the broader sociotechnical system in which the AI operates. This necessitates recognizing that AI is not isolated, but interacts with human operators, organizational procedures, physical environments, and external systems. Failures are rarely attributable to a single component; rather, they emerge from complex interactions and emergent properties within this integrated system. Consequently, a comprehensive safety analysis requires identifying potential hazards arising from these interactions, considering factors such as communication protocols, workload distribution, training procedures, and the influence of organizational goals on system behavior. Ignoring these social and organizational elements limits the ability to predict and mitigate risks effectively.
Defining Value Specification is a critical step in AI safety assessment, requiring the explicit articulation of ethical and societal principles that should govern AI system behavior. This process moves beyond simply avoiding component failure to proactively shaping the AI’s objectives and constraints. A well-defined Value Specification details acceptable and unacceptable outcomes, specifying how the AI should prioritize competing values in complex scenarios. It necessitates identifying stakeholders and their respective values, translating those values into concrete, measurable requirements, and documenting these requirements in a manner accessible to both technical and non-technical audiences. Without a clear Value Specification, AI systems may optimize for unintended consequences or exhibit behaviors misaligned with human expectations, even if functioning without technical errors.
Quantification as a Foundation for Rigorous Assessment
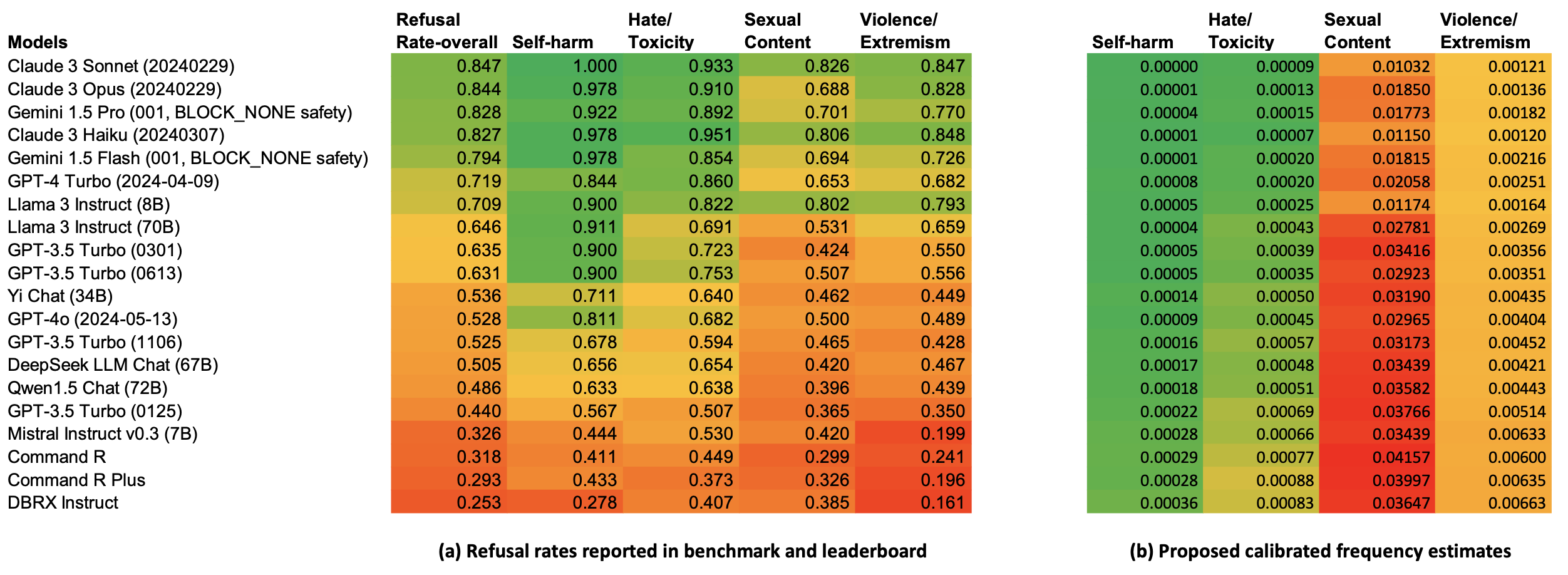
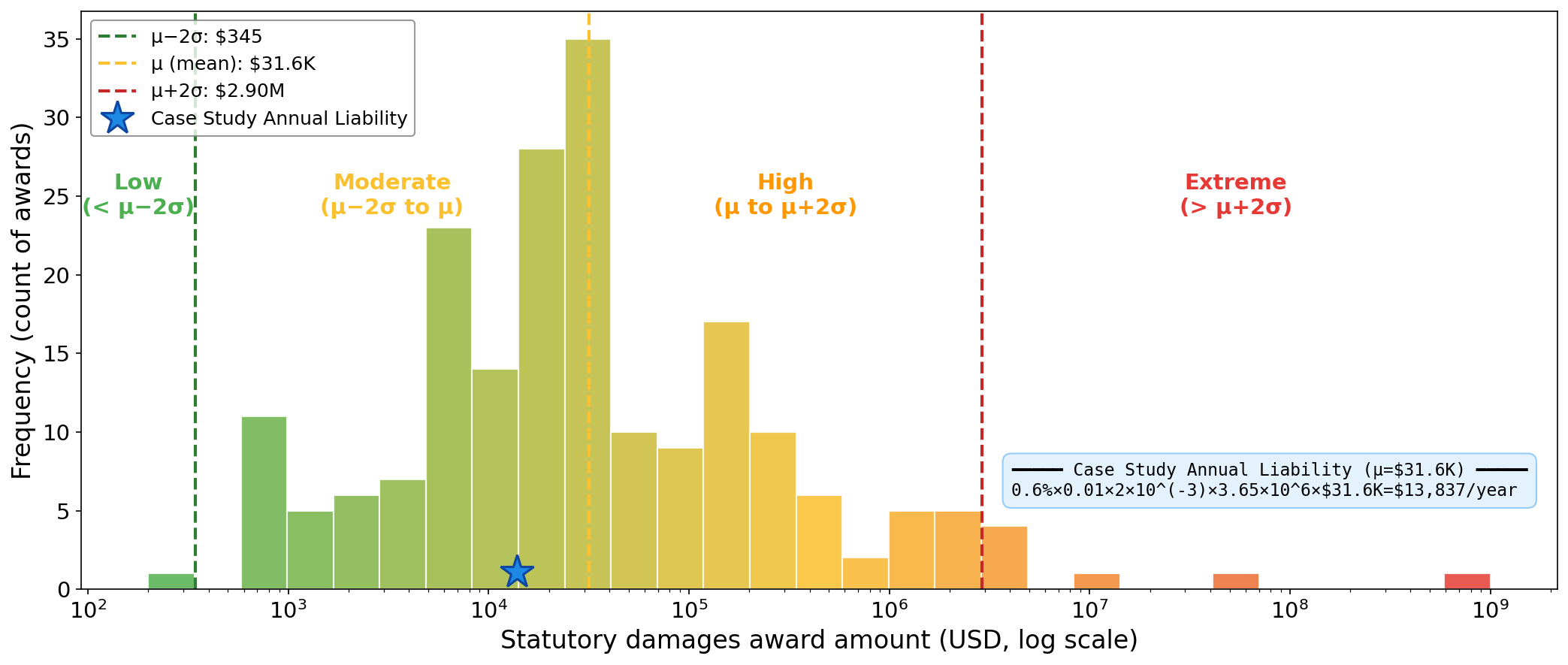
Risk quantification, rooted in Probabilistic Risk Assessment (PRA), establishes a methodology for numerically characterizing potential harms associated with AI systems. This process typically involves evaluating both the likelihood of a harmful event occurring and the severity of its potential impact, often expressed as a product of the two to generate a risk score. Despite the established framework, current adoption within AI benchmarks remains limited; a recent survey indicates that only 6% of evaluated benchmarks utilize a formal risk model based on likelihood multiplied by severity. This suggests a significant gap between the theoretical availability of quantitative risk assessment and its practical implementation in evaluating AI safety and reliability.
Benchmark validity in AI risk assessment depends on precise measurement of the targeted construct, necessitating the implementation of Harm Severity Scales. These scales categorize potential impacts by magnitude, allowing for nuanced evaluation beyond simple binary outcomes. Effective scales define discrete levels of harm-ranging from negligible or minor impacts to critical or catastrophic consequences-and provide clear criteria for assigning a given outcome to each level. This structured approach ensures consistent and reproducible evaluation, mitigating subjectivity and increasing confidence in benchmark results. The granularity of these scales directly impacts the ability to differentiate between varying degrees of risk and inform appropriate mitigation strategies.
Current AI benchmarks frequently utilize binary outcome proportions – measuring success or failure without granular detail – as their primary evaluation metric, with this approach constituting 79% of all benchmarks surveyed. While offering simplicity, reliance on binary metrics limits the ability to accurately assess risk and can obscure the magnitude of potential harms. Data-driven risk assessment seeks to improve benchmark validity by incorporating real-world observations and feedback to move beyond these limited proportions, allowing for a more nuanced understanding of AI system performance and potential negative consequences. This shift enables a more precise quantification of risk, moving from a simple pass/fail determination to a probabilistic assessment of harm severity and likelihood.
Towards a Standard of Robust and Responsible Evaluation
Failure Mode and Effects Analysis, or FMEA, offers a proactive and structured approach to enhancing the reliability of complex systems. This technique systematically dissects potential failure points – considering not just what could go wrong, but the consequences of each failure and its impact on the overall system. By meticulously identifying these vulnerabilities, developers can prioritize mitigation strategies, ranging from design modifications to robust error handling. The process involves assessing the severity, occurrence probability, and detectability of each failure mode, allowing for a risk prioritization that focuses resources on the most critical areas. Ultimately, FMEA isn’t merely about preventing failures; it’s about building resilience – ensuring systems can gracefully handle unexpected events and maintain safe, predictable operation, particularly crucial in the rapidly evolving field of artificial intelligence.
The development of robust and reliable AI benchmarks necessitates active participation from the communities most likely to be impacted by these systems. Simply put, benchmarks created in isolation risk prioritizing technical challenges over real-world consequences, potentially leading to biased evaluations or overlooking critical safety concerns. Meaningful community engagement ensures benchmarks accurately reflect diverse values and address legitimate societal worries, moving beyond purely technical metrics to encompass fairness, accountability, and transparency. This collaborative approach not only enhances the relevance and validity of benchmarks but also fosters trust and promotes responsible AI development, ultimately leading to systems that are both effective and aligned with human needs.
The pursuit of robust AI safety necessitates rigorous evaluation, and a newly developed Benchmark Design Checklist, as demonstrated by the AIR 2024 initiative, offers a standardized approach to assessing benchmark quality. This checklist comprehensively covers crucial aspects, from clearly defined evaluation metrics and realistic scenarios to thorough documentation and accessibility. However, a recent assessment utilizing this checklist revealed a significant gap in current practices; of the 37 items evaluated, only 7 were consistently and fully addressed across existing AI safety benchmarks. This finding underscores a critical need for increased attention to benchmark design principles and highlights the potential for substantial improvement in the reliability and meaningfulness of AI safety evaluations, ultimately contributing to the development of more trustworthy and aligned AI systems.
The pursuit of genuinely safe artificial intelligence demands a rigor often absent in current benchmarking practices. This article rightly emphasizes that evaluating AI systems necessitates moving beyond superficial tests to embrace the complexities of sociotechnical systems and the principles of sound measurement theory. As Linus Torvalds observed, “Talk is cheap. Show me the code.” Similarly, pronouncements of AI safety are meaningless without demonstrably robust and mathematically grounded evaluation frameworks. The article’s focus on risk assessment, therefore, isn’t merely about identifying potential harms, but about establishing invariant properties – measurable characteristics that remain constant even as the complexity of the system, and the approaches to it, approach infinity. Only then can one begin to approach a truly provable level of safety.
What’s Next?
The pursuit of ‘AI safety’ has, until now, largely resembled applied engineering rather than a genuine science. This work highlights the critical need to move beyond empirical testing – demonstrating a system fails on contrived examples – toward a theoretically grounded understanding of risk. The challenge isn’t simply building systems that avoid triggering pre-defined failure cases; it’s formally characterizing the space of potential harms, a task demanding precision, not merely cleverness. The field must embrace the rigor of measurement theory, acknowledging that any attempt to quantify ‘safety’ is inherently an approximation, laden with assumptions that must be explicitly stated and defended.
A significant limitation remains the inherent difficulty in reducing sociotechnical harms to quantifiable metrics. While formal methods offer a path toward provable properties, these are constrained by the models used. The real world is messy, and any abstraction necessarily introduces error. The emphasis must shift from seeking perfect ‘solutions’ to developing robust methods for bounding risk, understanding the limits of our knowledge, and building systems that degrade gracefully in the face of uncertainty.
Ultimately, the true test won’t be whether a benchmark declares a system ‘safe’, but whether the methodology employed provides a genuinely useful reduction in the probability of unforeseen consequences. Simplicity – not in the brevity of code, but in the non-contradiction of its underlying assumptions – remains the elusive ideal. The path forward demands a willingness to abandon the illusion of control and embrace the inherent complexity of intelligent systems operating within a complex world.
Original article: https://arxiv.org/pdf/2601.23112.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Mewgenics vinyl limited editions now available to pre-order
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
- Does Mark survive Invincible vs Conquest 2? Comics reveal fate after S4E5
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- How to Get to the Undercoast in Esoteric Ebb
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
2026-02-03 01:16