Author: Denis Avetisyan
Researchers have developed a new framework that allows users to query time series databases using plain English, overcoming the limitations of traditional methods.
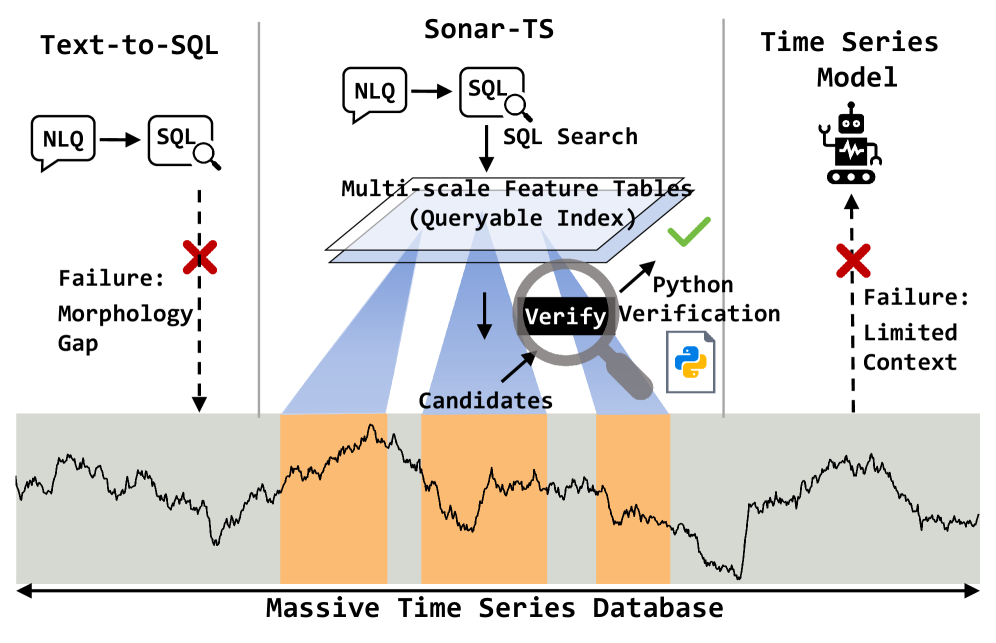
This paper introduces NLQ4TSDB, a benchmark for natural language querying of time series databases, and Sonar-TS, a neuro-symbolic framework combining database search with Python verification.
Existing methods struggle to bridge the gap between natural language and the complex queries required to extract meaningful insights from massive time series databases. This paper introduces ‘Sonar-TS: Search-Then-Verify Natural Language Querying for Time Series Databases’, a neuro-symbolic framework that tackles this challenge via a novel Search-Then-Verify pipeline, analogous to active sonar. By combining efficient database search with Python-based verification, Sonar-TS overcomes limitations of both traditional text-to-SQL methods and purely time-series based approaches, as demonstrated by a new large-scale benchmark, NLQTSBench. Can this framework unlock more intuitive and powerful data exploration for non-expert users working with ever-growing temporal datasets?
Beyond the Surface: Decoding Time Series with Language
Conventional techniques for interpreting natural language interactions with time series data, such as Text-to-SQL and Time Series Question Answering (TSQA), frequently encounter difficulties when faced with the intricacies of human language. These methods typically rely on pattern matching and keyword identification, proving inadequate when queries involve complex temporal reasoning-like identifying trends before a specific event-or morphological concepts inherent in time series, such as seasonality or anomalies. The inherent ambiguity of natural language, combined with the need to accurately map linguistic constructs to specific time-based operations, often leads to misinterpretations and inaccurate results. Consequently, a simple question about a data pattern can easily overwhelm these systems, highlighting the need for more sophisticated approaches that can truly understand the meaning behind a user’s request.
Traditional methods for interpreting natural language queries against time series data frequently stumble when confronted with the subtleties of temporal reasoning and the inherent characteristics of time-dependent data. Existing systems often treat time as a simple dimension, overlooking crucial relationships like trends, seasonality, and anomalies-concepts readily understood by humans but difficult for algorithms to discern. Furthermore, morphological features within the data – the shape and evolution of patterns over time – are often lost in translation to structured queries. For instance, differentiating between a ‘spike’ and a ‘gradual increase’ requires more than keyword matching; it demands an understanding of the rate of change and its context within the series. This inability to accurately capture these nuanced temporal dynamics and morphological qualities limits the effectiveness of current approaches and highlights the need for more sophisticated techniques capable of truly understanding the language of time series.
Effective querying of Time Series Databases (TSDB) using natural language extends far beyond simple translation of words into database commands. A truly robust system requires a deep semantic understanding of the query, discerning not just what is being asked, but also the underlying intent and temporal context. This necessitates interpreting complex relationships within the time series data – recognizing patterns, anomalies, and dependencies – and relating those interpretations to the nuances of human language. For example, a query like “Show me the peak usage after the marketing campaign” requires understanding ‘peak usage’ as a statistical concept, identifying the relevant timeframe of the ‘marketing campaign’, and correctly associating the two within the database. Simply mapping keywords to column names proves insufficient; instead, the system must build a conceptual model of the query to accurately retrieve meaningful insights from the time series data.
Current approaches to natural language querying of time series databases frequently falter due to an inability to fully interpret the complexities of human language when applied to temporal data. Traditional methods, designed for structured data, struggle with the inherent ambiguity and nuanced relationships within time series, leading to inaccurate or incomplete results. This limitation underscores the need for a fundamentally new paradigm – Natural Language Querying for Time Series Databases (NLQ4TSDB) – one that moves beyond simple translation and embraces deep semantic understanding of both natural language and the underlying temporal characteristics of the data. Such a paradigm must prioritize capturing temporal reasoning, morphological analysis specific to time series, and the context within which queries are posed to unlock the true potential of conversational time series analysis.
NLQTSBench: A Hierarchy of Challenges
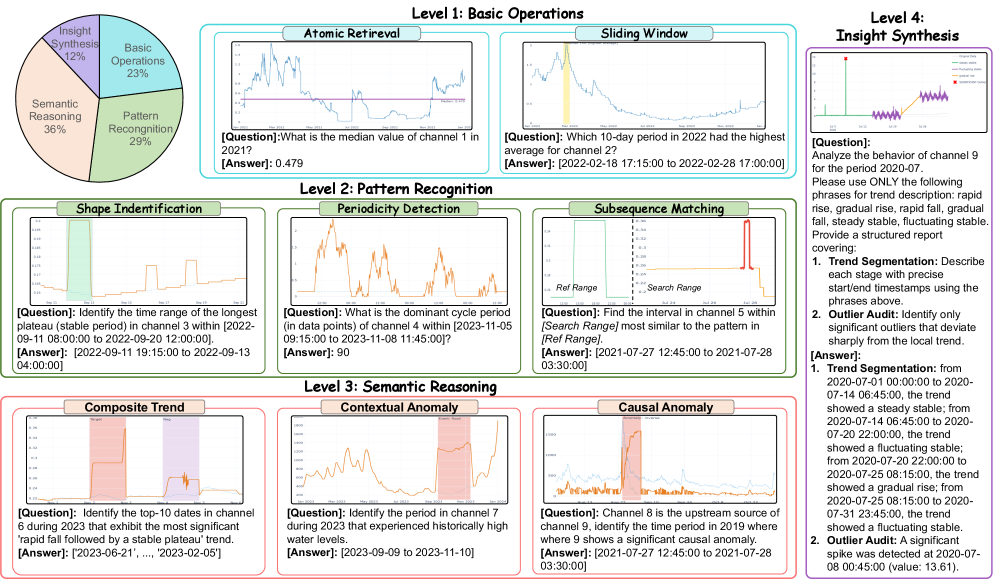
NLQTSBench is designed as a multifaceted benchmark to rigorously evaluate Natural Language Querying for Time Series Databases (NLQ4TSDB) systems. It moves beyond simple query correctness by incorporating tasks that range in complexity from basic time series operations to sophisticated insight synthesis. This hierarchical structure enables a detailed assessment of a system’s capabilities across various skill levels, providing a granular understanding of strengths and weaknesses. The benchmark includes a diverse set of queries and time series datasets intended to represent real-world analytical workloads, allowing for a more practical evaluation than traditional, isolated tests. By assessing performance across this spectrum of complexity, NLQTSBench facilitates a comprehensive comparison of different NLQ4TSDB approaches and drives advancements in the field.
NLQTSBench utilizes a four-level hierarchical structure to facilitate detailed evaluation of Natural Language to Time Series Database (NLQ4TSDB) systems. Level 1 assesses basic functionalities like single metric retrieval. Subsequent levels increase in complexity, with Level 2 focusing on pattern recognition within time series, Level 3 evaluating semantic reasoning and composition of logical operations, and Level 4 requiring systems to synthesize insights from multiple queries and data sources. This tiered approach enables researchers to pinpoint specific strengths and weaknesses of different systems, moving beyond aggregate performance scores to provide a granular understanding of their capabilities across varying levels of task complexity.
Level 2 tasks within NLQTSBench specifically evaluate a system’s ability to identify patterns, or morphological concepts, present in time series data. These tasks assess the system’s capacity to ground natural language queries to specific temporal features. Performance on these tasks is measured by Interval Overlap (IoU), a metric quantifying the degree of correspondence between predicted and ground truth time intervals. Notably, the Sonar-TS system achieved substantial IoU improvements on Level 2 tasks compared to baseline methods, indicating enhanced capabilities in recognizing and extracting morphological patterns from time series data.
Level 3 tasks within NLQTSBench are designed to evaluate a system’s capacity for semantic reasoning over time series data. These tasks necessitate the composition of logical operations – such as AND, OR, NOT, greater than, less than, and equality – to answer complex natural language queries. Successful completion requires the system to not only identify relevant time series but also to understand the relational aspects between them; for example, determining if the value of one series is consistently higher than another over a specified period, or identifying periods where multiple conditions are simultaneously met. Performance on Level 3 tasks indicates a system’s ability to move beyond simple data retrieval and towards true understanding of the relationships within time series data.
Sonar-TS: A Neuro-Symbolic Engine for Verification
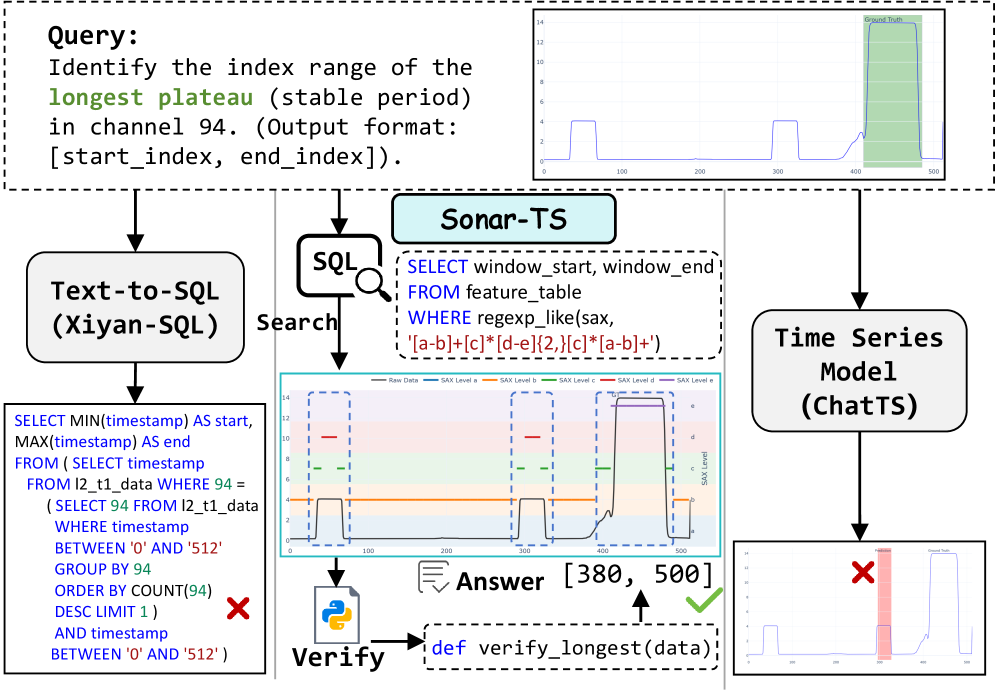
Sonar-TS utilizes a neuro-symbolic framework for Natural Language Querying of Time Series Databases (NLQ4TSDB) through a two-stage ‘Search-Then-Verify’ pipeline. Initially, Structured Query Language (SQL) is employed to retrieve a candidate set of data from the time series database based on the natural language query. This initial search is then followed by a verification stage implemented in Python, which operates directly on the raw time series data. This dual process aims to improve both the accuracy and robustness of query answering by combining the efficiency of SQL-based search with the expressive power of Python for complex data validation and refinement. The framework distinguishes itself from single-stage approaches by explicitly separating the retrieval and verification steps, enabling more targeted and reliable results.
The Sonar-TS framework utilizes a two-stage process for time-series data query. Initially, Structured Query Language (SQL) is employed to retrieve a candidate set of data points from the time-series database. This SQL-based search provides a computationally efficient method for narrowing down the potential results. Subsequently, this candidate set is subjected to verification using Python code that operates directly on the raw time-series data. This Python-based verification step allows for the application of more complex logic and nuanced analysis than is typically feasible within SQL, thereby improving the overall accuracy and robustness of the query response by filtering out false positives identified in the initial SQL search.
Feature Tables are central to the efficiency of the Sonar-TS framework’s Search-Then-Verify pipeline by precomputing statistical summaries and morphological signatures of time-series data. These tables store aggregated data, such as mean, standard deviation, and trend information, alongside signatures representing recurring patterns or shapes within the time-series. This precomputation avoids redundant calculations during query processing, significantly reducing latency. Morphological signatures, generated using techniques like Symbolic Aggregate approXimation (SAX), allow for rapid identification of candidate data segments that potentially satisfy a given natural language query, effectively narrowing the search space before the more computationally expensive Python-based verification stage.
Symbolic Aggregate approXimation (SAX) is utilized within Feature Tables to facilitate efficient time series pattern matching and signature generation. SAX converts time series data into a symbolic representation, reducing data dimensionality while preserving essential characteristics. This symbolic representation allows for faster comparison of time series segments, enabling the identification of similar patterns with reduced computational cost. Specifically, in the context of Level 1 tasks – those requiring the identification of basic time series characteristics – SAX-based signature generation improves accuracy by providing a robust and noise-tolerant method for representing and comparing temporal data, leading to more reliable pattern recognition.
Beyond Queries: Orchestration and the Pursuit of Insight
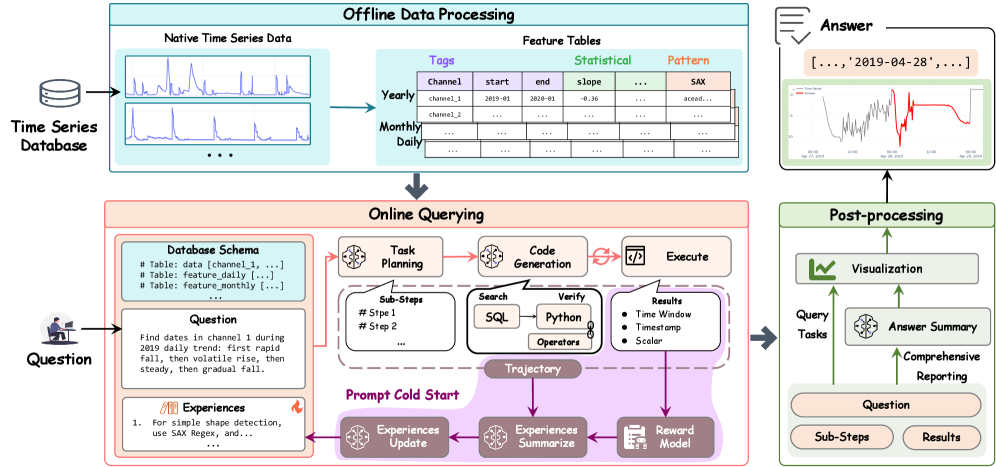
Sonar-TS employs a large language model (LLM) as a central Planner, fundamentally altering how time series data is queried and analyzed. Rather than requiring users to formulate precise, technical commands, the system accepts complex requests in natural language. The LLM then dissects these requests, breaking them down into a series of executable steps – an internal plan – tailored to the specific data and desired outcome. This decomposition streamlines the query process, effectively translating human intention into machine-readable instructions. By automating the translation from natural language to executable plans, Sonar-TS significantly lowers the barrier to entry for time series analysis, allowing users to focus on interpreting insights rather than struggling with technical implementation details. The Planner not only determines the sequence of operations but also selects appropriate domain-specific verification operators to ensure accuracy and relevance in the resulting analysis.
The precision of Sonar-TS hinges on a suite of Domain-Specific Verification Operators, which function as the fundamental building blocks for analyzing time series data. These operators aren’t general-purpose mathematical functions; instead, they are meticulously crafted to perform specific, relevant computations on temporal data – such as identifying trends, calculating rates of change, or detecting anomalies within defined parameters. This focused design ensures both accuracy and efficiency, allowing the system to move beyond simple data retrieval and engage in meaningful verification of complex queries. For example, an operator might specifically calculate the \frac{dY}{dt} of a given time series, or determine if a value exceeds a statistically significant threshold. By isolating these computations into discrete, verifiable units, Sonar-TS minimizes the potential for error and delivers reliable results, even when dealing with nuanced temporal analyses.
The system incorporates an Experience Summarizer, a crucial component designed to move beyond simple query resolution and foster genuine learning from each interaction. This module meticulously analyzes execution traces – the detailed record of how a query was processed – to identify recurring patterns, common errors, and effective strategies. By distilling these observations into reusable technical insights, the system avoids repeating past mistakes and progressively refines its approach to future challenges. This continuous improvement isn’t merely about speed or efficiency; it’s about building a growing repository of knowledge, enabling the system to tackle increasingly complex time series analysis tasks with greater accuracy and providing a demonstrable pathway towards automated expertise in the domain. The extracted insights are not simply stored, but are actively leveraged to optimize subsequent plan generation and verification processes, creating a positive feedback loop that enhances overall performance.
The culmination of Sonar-TS’s analytical capabilities lies in its capacity for Insight Synthesis, manifested through Level 4 tasks that demand the generation of comprehensive reports from complex time series data. These tasks aren’t simply about retrieving information; the system actively constructs a holistic understanding, translating raw data into actionable intelligence suitable for informed decision-making. Evaluation of this synthesis capability, measured through a composite F1-score for structured report generation, demonstrates a robust ability to not only accurately represent the data but also to organize it into a coherent and meaningful narrative – a key differentiator for advanced time series analytics platforms seeking to move beyond simple observation and towards proactive insight delivery.
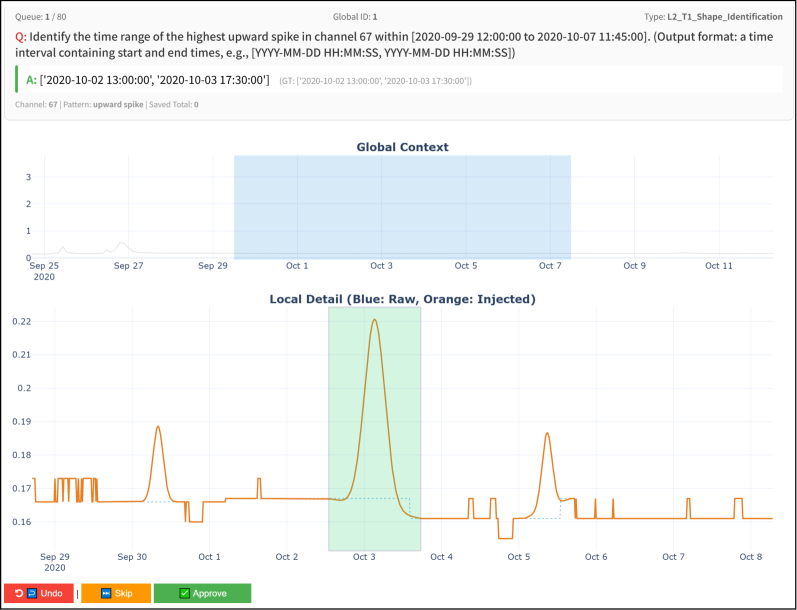
The development of Sonar-TS exemplifies a fundamental principle: robust systems are built on a foundation of verifiable components. The paper details how combining database search with Python verification addresses the shortcomings of prior natural language querying methods for time series data. This echoes Claude Shannon’s assertion that “Communication is most effective when it is free of ambiguity.” Just as Shannon prioritized clarity in signal transmission, Sonar-TS prioritizes a clear, verifiable path from natural language question to database result. The framework doesn’t merely answer a query; it demonstrates how it arrived at that answer, offering transparency and building trust in the system’s output, aligning with the core idea of NLQ4TSDB and the need for reliable time series question answering.
Beyond the Query
The introduction of NLQ4TSDB, and frameworks like Sonar-TS, doesn’t resolve the fundamental tension inherent in translating natural language into precise database operations; it merely shifts the battleground. Current approaches, even those employing verification stages, still operate under the assumption that a ‘correct’ answer exists and is retrievable with sufficient parsing. But what of the genuinely ambiguous query, the one reflecting an ill-defined question rather than a flawed translation? The field risks becoming overly focused on syntactic correctness at the expense of semantic nuance.
Future work should deliberately court ambiguity. Instead of striving for deterministic outputs, systems could benefit from probabilistic responses – a distribution of likely answers with associated confidence intervals. Furthermore, the reliance on Python as a verification layer, while pragmatic, introduces a new dependency and potential bottleneck. Exploring alternative, more declarative verification languages-or even a self-verifying system capable of assessing its own logical consistency-could prove fruitful.
Ultimately, the true challenge isn’t building a system that answers questions, but one that intelligently disassembles them. A framework that can identify the assumptions embedded within a query, and then systematically test those assumptions against the data, would represent a genuine leap forward. It would, in effect, be a system that doesn’t just find data, but learns from the process of asking.
Original article: https://arxiv.org/pdf/2602.17001.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- How to Get to the Undercoast in Esoteric Ebb
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- All Itzaland Animal Locations in Infinity Nikki
- Warframe Voruna Prime access begins on April 8 for all platforms, new deluxe cosmetic Warframe skins revealed
- HBO’s Harry Potter Is Already Breaking My Heart
- Zendaya’s 4 Big 2026 Movies Could Beat Brie Larson’s Box 2019 Office Record
2026-02-22 00:03