Author: Denis Avetisyan
This review details the architecture and key technologies for creating natural language query systems that unlock insights from complex financial data.
A technical blueprint for leveraging vector search, embeddings, and hybrid retrieval to power advanced financial knowledge search.
Accessing and interpreting the rapidly growing volume of financial data remains a significant challenge, despite advancements in knowledge retrieval. This paper, ‘FinMetaMind: A Tech Blueprint on NLQ Systems for Financial Knowledge Search’, details the design and implementation of a Natural Language Query (NLQ) system tailored for financial knowledge repositories. By combining vector search, embeddings, and hybrid retrieval techniques, we demonstrate a blueprint for improved access to, and deeper insights from, complex financial information. Will this approach unlock new efficiencies in financial analysis and ultimately reshape how financial professionals interact with data?
Deconstructing Language: The Illusion of Keyword Search
Conventional keyword search, while historically effective, frequently falters when confronted with the subtleties of human language. These systems operate on literal matches, meaning a query for “best way to fix a leaky faucet” might return results discussing faucets generally, or even plumbing tools, without pinpointing the specific repair process. This limitation arises because keyword search lacks semantic understanding – the ability to discern the intent and meaning behind the words. Consequently, nuanced queries, those employing synonyms, context, or implied relationships, often yield a high volume of irrelevant results, forcing users to sift through extraneous information. The core issue isn’t a failure to find the keywords, but an inability to grasp what the user is actually asking, highlighting a fundamental disconnect between the query’s intent and the system’s mechanical matching process.
The digital landscape is increasingly dominated by unstructured data – text from social media, emails, customer reviews, and countless other sources – presenting a significant challenge to information retrieval. Traditional search methods, reliant on keyword matching, falter when confronted with the complexities of human language, often missing the intent behind a query. Consequently, modern approaches prioritize semantic understanding – the ability to discern the meaning of text, considering context, relationships between words, and even implied concepts. This shift demands techniques that move beyond simple term comparison, employing methods like natural language processing and machine learning to interpret the underlying message and deliver results aligned with the user’s true need, rather than just literal keyword occurrences. Effectively capturing this meaning is no longer a convenience, but a necessity for extracting value from the ever-growing flood of textual data.
The demand for seamless information access has propelled the development of systems capable of interpreting the intent behind human language, rather than simply matching keywords. This bridging of the gap between natural language and data retrieval is no longer a technological aspiration, but a fundamental requirement for a diverse array of modern applications. From virtual assistants and customer service chatbots to complex legal discovery and medical diagnosis tools, the ability to accurately extract meaning from unstructured text unlocks unprecedented levels of efficiency and insight. Consequently, advancements in areas like natural language processing, machine learning, and semantic web technologies are converging to create systems that can understand context, disambiguate meaning, and deliver relevant information with increasing precision – ultimately transforming how humans interact with data and knowledge.
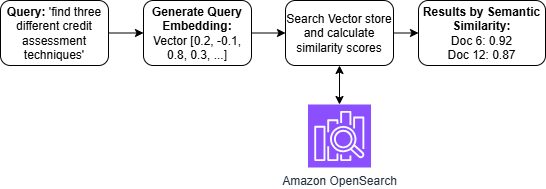
Mapping Meaning: The Power of Vector Embeddings
Embeddings represent textual data as numerical vectors in a high-dimensional space, where the position and direction of each vector encode the semantic meaning of the corresponding text. Unlike traditional one-hot encoding or bag-of-words models that treat words as discrete, independent units, embeddings capture relationships between words and concepts by placing semantically similar text closer together in this vector space. This allows algorithms to understand analogies, identify synonyms, and perform complex reasoning tasks based on the meaning of the text, rather than just keyword matching. The dimensionality of these vectors is typically in the range of hundreds or thousands, allowing for a nuanced representation of complex semantic information.
Current state-of-the-art natural language processing relies heavily on embedding models to convert text into numerical vector representations. Models such as BERT and those offered by OpenAI are commonly utilized for this purpose. Recent experimentation has involved comparative analysis of several models, including NV-Embed-v2, gte-Qwen2-7B-instruct, and amazon.titan-embed-text-v2, to assess their performance in generating effective embeddings for semantic understanding and downstream tasks. These models differ in architecture, training data, and resulting vector dimensionality, impacting the quality and applicability of the generated embeddings.
Evaluation of multiple embedding models, including NV-Embed-v2, gte-Qwen2-7B-instruct, and amazon.titan-embed-text-v2, resulted in the selection of the latter for subsequent experimentation. This decision indicates that amazon.titan-embed-text-v2 demonstrated superior performance characteristics – likely encompassing a combination of embedding quality, speed of generation, and cost-effectiveness – when assessed against the defined evaluation criteria. While specific metrics are not detailed, the model’s selection implies a measurable advantage over the alternatives in capturing semantic relationships within the tested data.
Amazon Bedrock streamlines the integration of embedding models by offering a centralized platform with access to a variety of options, including those from AI21 Labs, Anthropic, Cohere, Meta, and Amazon itself. This service eliminates the need for individual model hosting and management, providing a unified API for accessing and deploying models like those used for generating textual embeddings. Bedrock handles infrastructure concerns, allowing developers to focus solely on application logic and experimentation with different embedding techniques without the operational overhead typically associated with machine learning model deployment and scaling. The platform also supports features like versioning and access control, further simplifying the development lifecycle.
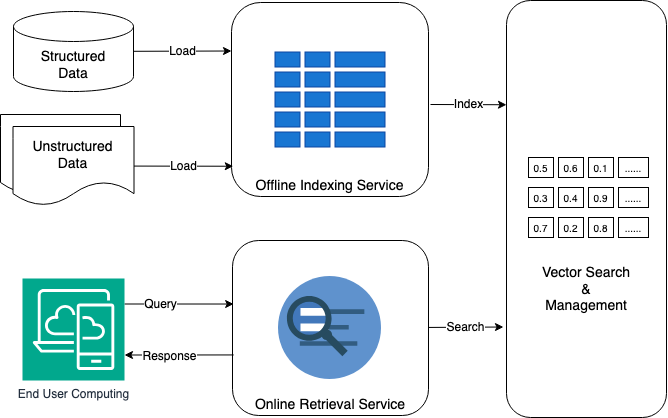
Scaling the Search: Indexing for Insight
The Offline Indexing Service utilizes approximate nearest neighbor (ANN) algorithms, specifically Hierarchical Navigable Small Worlds (HNSW), to construct vector indexes optimized for high-dimensional vector search. HNSW creates a multi-layer graph where each layer represents a progressively coarser approximation of the data, enabling fast traversal and efficient similarity searches. This approach reduces search latency by sacrificing a small degree of accuracy, offering a configurable trade-off between speed and precision. Index construction involves building this graph structure from input vectors, establishing connections between similar vectors to facilitate rapid neighbor identification during query processing. The resulting index allows for scalable and efficient retrieval of vectors based on similarity metrics, such as cosine similarity or Euclidean distance.
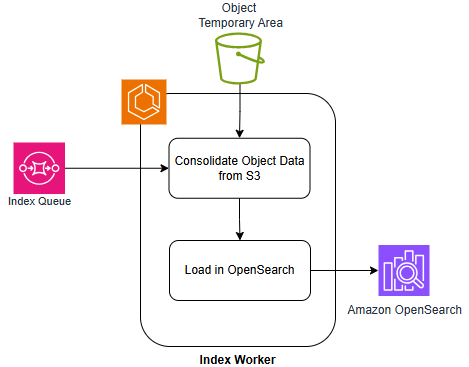
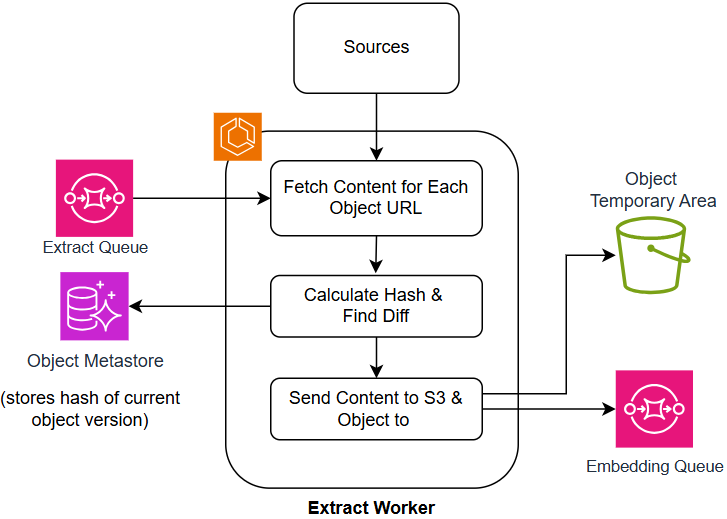
Prior to indexing, data undergoes mandatory pre-processing and enrichment via the Extract Pipeline and AI Enrichment Pipeline. The Extract Pipeline focuses on data cleaning, transformation, and feature extraction, preparing raw data for subsequent analysis. Following extraction, the AI Enrichment Pipeline applies machine learning models to generate additional features and metadata, enhancing the semantic representation of the data. This enrichment process can include tasks such as named entity recognition, sentiment analysis, and topic modeling, all of which contribute to improved vector embeddings and, consequently, more accurate and relevant search results. Both pipelines operate sequentially, ensuring data is properly formatted and enhanced before being utilized for vector index creation.
The Elastic Container Service (ECS) functions as the central orchestration layer for the indexing pipelines, automating deployment, scaling, and management of containerized indexing tasks. ECS utilizes task definitions to specify resource requirements, networking configurations, and container images for each pipeline component. Horizontal scaling is achieved by dynamically adjusting the number of task instances based on workload demands, monitored through ECS service metrics. Reliability is maintained through ECS features like health checks, automatic task restarts, and integration with load balancing to distribute traffic across available instances. This containerized approach facilitates consistent deployments across different environments and enables rapid iteration on indexing pipeline configurations.
Beyond Retrieval: The Synthesis of Knowledge
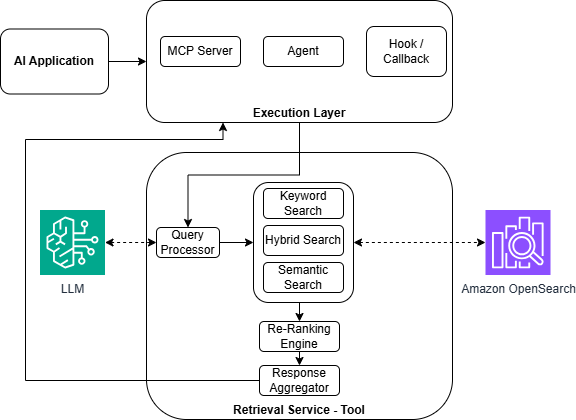
The core of modern information access relies on transforming human language into a format computers can effectively process. The Online Retrieval Service accomplishes this by converting natural language queries into vector search requests, a process enabled by the creation of embeddings. These embeddings are numerical representations of words, phrases, and even entire documents, capturing their semantic meaning and relationships. Instead of simply matching keywords, the system maps both the query and the stored data into this vector space, allowing it to identify information that is conceptually similar, even if the exact words don’t match. This semantic understanding is crucial for overcoming the limitations of traditional keyword searches and delivering more relevant and nuanced results, effectively bridging the gap between how humans ask questions and how computers interpret them.
The intelligent retrieval service leverages a hybrid search approach to optimize information discovery, skillfully merging the strengths of vector and keyword-based methodologies. Traditional keyword searches excel at identifying exact matches, but often miss nuanced relationships or semantic meaning; vector search, conversely, understands concepts and context, enabling the discovery of conceptually similar information even without direct keyword overlap. This service intelligently combines both, weighting the contribution of each method to fine-tune results. A higher weighting towards keyword search prioritizes precision – ensuring retrieved items directly address the query – while emphasizing vector search enhances recall, broadening the search to encompass a wider range of relevant, though perhaps not identically worded, data. The precise balance of these weights is crucial; it directly influences the system’s ability to deliver both comprehensive and highly focused answers, adapting to the specific needs of each query and the characteristics of the underlying data.
The system transcends simple information retrieval through its integration with Retrieval-Augmented Generation. Rather than merely presenting sourced documents, the technology actively synthesizes retrieved data into fluent, contextually relevant responses. This process involves leveraging large language models that, informed by the retrieved knowledge, construct new text – effectively ‘reasoning’ over the sourced information to provide answers, summaries, or even creative content. By combining the strengths of information retrieval – accessing a vast knowledge base – with the generative capabilities of advanced AI, the system moves beyond finding answers to creating them, offering a more dynamic and insightful user experience. This capability is particularly valuable when dealing with complex queries requiring nuanced understanding and synthesis of multiple sources.
The Complete Picture: Enhancing Data and Queries
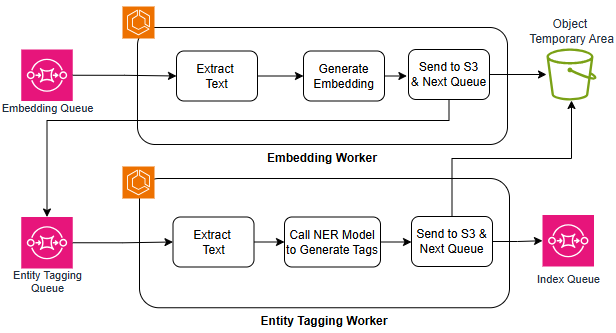
The process of transforming raw data into a format suitable for advanced analysis hinges on the AI Enrichment Pipeline, a crucial component responsible for preparing information for vectorization. This pipeline incorporates specialized workers, notably the Embedding Worker and the Entity Tagging Worker, which collaborate to distill meaning from text. The Embedding Worker translates words and phrases into numerical vectors – essentially, coordinates in a high-dimensional space – capturing semantic relationships. Simultaneously, the Entity Tagging Worker identifies and categorizes key entities within the text, such as people, organizations, and locations. This dual process ensures that the vectorized data not only represents the content but also understands what the content is about, dramatically improving the accuracy and relevance of subsequent analyses and enabling more sophisticated information retrieval.
The Natural Language Query System has been significantly enhanced through the implementation of Text-to-SQL conversion, bridging the gap between human language and structured data access. This innovative capability empowers users to retrieve specific information from databases simply by posing questions in everyday language, eliminating the need for complex SQL coding. The system intelligently parses natural language queries, translates them into accurate SQL commands, executes those commands against the database, and then presents the results in a user-friendly format. This advancement democratizes data access, allowing individuals without technical expertise to independently explore and analyze valuable insights contained within relational databases, ultimately fostering data-driven decision-making across various domains.
The pursuit of deeper data understanding necessitates a commitment to iterative refinement across the entire analytical pipeline. Each stage, from the initial extraction of raw information to the final processing of complex queries, presents opportunities for improvement. Through continuous optimization – be it enhancing data cleaning algorithms, streamlining feature engineering, or accelerating query execution – the system’s capacity to reveal meaningful patterns and actionable intelligence is significantly amplified. This dedication to incremental gains ensures that the insights derived from data become progressively more nuanced, accurate, and ultimately, valuable, allowing organizations to adapt and innovate with greater agility and precision.
The pursuit of efficient financial knowledge retrieval, as outlined in this blueprint, isn’t simply about finding answers, but about systematically challenging the boundaries of information access. It’s a process of controlled deconstruction, much like reverse-engineering a complex system. As Robert Tarjan once stated, “The key to good programming is recognizing when to break the rules.” This resonates deeply with the FinMetaMind approach; the hybrid retrieval methods-combining vector search with embeddings-aren’t merely additive, but represent a deliberate ‘breaking’ of traditional search paradigms to expose hidden relationships within financial data. The system isn’t built on accepting limitations, but on actively probing them, identifying vulnerabilities in existing methods, and forging a new path toward semantic understanding.
What’s Next?
The architecture detailed within effectively externalizes a financial analyst’s knowledge retrieval process, translating intent into vector space navigation. However, the system’s efficacy remains tethered to the quality of its embeddings and the inherent biases within the training data. The truly interesting challenge isn’t simply finding information, but discerning what wasn’t found – the gaps in knowledge, the unasked questions, the deliberately obscured data. A robust system should flag its own ignorance with the same enthusiasm it displays for successful retrieval.
Future iterations will undoubtedly focus on refining hybrid retrieval strategies, optimizing for both precision and recall. Yet, the real leap will come from moving beyond semantic similarity to genuine understanding. The system currently interprets queries; it doesn’t reason about them. Bridging that gap requires incorporating causal models and common-sense knowledge-essentially, teaching the machine to smell a rat in the financial statements.
Ultimately, the best hack is understanding why it worked – and why it didn’t. Every patch is a philosophical confession of imperfection. The pursuit of a perfect NLQ system for finance is, therefore, a beautiful, endless loop – a testament to the fact that knowledge isn’t a destination, but a perpetually evolving map.
Original article: https://arxiv.org/pdf/2601.17333.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- All Itzaland Animal Locations in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- How to Get to the Undercoast in Esoteric Ebb
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Crimson Desert: Disconnected Truth Puzzle Guide
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- Gold Rate Forecast
- 6 Ways Invincible Season 4’s Hell Episode Rewrites The Comics
2026-01-27 16:14