Author: Denis Avetisyan
Researchers have developed a computationally efficient system that predicts potential accidents by analyzing broad video features, moving beyond traditional object detection methods.

VAGNet leverages a foundation model to extract global video features for improved accident anticipation in Advanced Driver Assistance Systems.
Despite advancements in driver assistance, anticipating traffic accidents remains a critical challenge due to the computational demands of processing complex driving scenes in real-time. This paper introduces VAGNet: Vision-based accident anticipation with global features, a novel deep learning approach that predicts potential collisions using global video features-avoiding the need for computationally expensive object detection. By leveraging a vision foundation model (VideoMAE-V2) within a transformer and graph neural network architecture, VAGNet achieves higher average precision and longer time-to-accident prediction on benchmark datasets while improving computational efficiency. Could this shift toward global feature analysis unlock a new paradigm for proactive safety systems in autonomous and assisted driving?
Beyond Reaction: The Looming Need for Anticipatory Safety
Current vehicle safety systems predominantly function by reacting to hazards as they unfold. These technologies, such as anti-lock brakes and electronic stability control, are designed to mitigate the consequences of a developing emergency – correcting a skid or preventing a loss of control – but only after the dangerous situation has already begun. This reactive paradigm inherently limits the potential for complete accident prevention, as the vehicle and driver are always playing catch-up to an unforeseen event. While effective at reducing the severity of impacts, these systems lack the capacity to anticipate and neutralize risks before they escalate into collisions, highlighting a critical need for technologies that move beyond simply responding to danger and instead actively work to foresee and avoid it.
Current accident avoidance technologies predominantly function by mitigating the consequences of an impending collision, rather than preventing the dangerous scenario from developing in the first place. This reactive stance inherently restricts the scope of safety improvements; systems can only lessen damage or injury after a hazard has been detected and a response initiated. Consequently, the potential for averting accidents entirely remains largely untapped, as valuable time is lost reacting to events instead of anticipating them. This limitation impacts not only the severity of collisions but also the overall frequency, highlighting the need for a paradigm shift towards preemptive safety measures that address the root causes of accidents before they manifest as critical events.
The future of road safety hinges on a fundamental transition from reacting to danger to actively anticipating it. Current systems largely function after a potential hazard arises, initiating braking or evasive maneuvers – a response that inherently limits the degree of harm that can be avoided. Proactive safety, conversely, utilizes advanced sensor fusion, predictive algorithms, and real-time data analysis to assess risk before it fully materializes. This allows for subtle interventions – gentle steering corrections, speed adjustments, or pre-tensioning of seatbelts – that can prevent a dangerous situation from escalating into a collision. By moving beyond simply mitigating the consequences of accidents, a proactive approach promises a substantial reduction in both the frequency and severity of road incidents, ultimately paving the way for truly safer transportation systems.

Unveiling Predictive Models: The Core Methodologies
Object detection is a critical component of predictive modeling for accident anticipation, functioning as the initial stage in processing video data. This process involves identifying and localizing specific objects – such as vehicles, pedestrians, cyclists, and static infrastructure – within each frame of a video stream. Accurate object detection relies on algorithms capable of differentiating between object classes and handling variations in scale, pose, and occlusion. The resulting data – bounding box coordinates and class labels – provides the foundational information necessary for subsequent analysis of object interactions and trajectory prediction, enabling the system to assess potential collision risks and preemptively issue warnings or interventions. Performance is often measured using metrics like mean Average Precision (mAP) and Intersection over Union (IoU).
Spatiotemporal feature extraction is critical for analyzing video data because it captures both spatial and temporal information, enabling the model to understand movement and interactions within a scene. Methods like Inflated 3D ConvNets (I3D) extend 2D convolutional neural networks to 3D, directly processing video volumes and learning spatiotemporal features. SlowFast networks address the computational demands of video analysis by employing two pathways: a “slow” pathway processing low-frame-rate, high-resolution data to capture semantic information, and a “fast” pathway processing high-frame-rate, low-resolution data to capture fine-grained motion details; these are then fused to produce a comprehensive representation of the scene’s dynamics. Effectively capturing these features is essential for accurately predicting future events within a video sequence.
VideoMAE-V2 serves as an effective initialization point for predictive models by providing pre-trained weights capable of extracting robust global features from video data. This approach leverages the model’s prior learning to accelerate training and enhance prediction accuracy, particularly in scenarios with limited labeled data. Specifically, integrating VideoMAE-V2 contributes to a computational complexity of 102 GFLOPs (giga floating-point operations per second) per processed frame, representing a balance between model size, processing demand, and performance capabilities for real-time or near real-time applications.

Advanced Architectures: Reasoning Through Space and Time
STAGNet and AAT-DA models address spatiotemporal reasoning through the application of transformer architectures coupled with attention mechanisms. Specifically, STAGNet employs a spatiotemporal attention gate network to selectively focus on relevant features across both spatial and temporal dimensions within video sequences. AAT-DA further refines this approach by incorporating an attention-augmented transformer with domain adaptation techniques, enabling effective knowledge transfer between different video datasets. Both architectures leverage self-attention layers to capture long-range dependencies between frames, improving the modeling of complex interactions and ultimately enhancing performance in tasks requiring an understanding of evolving scenes.
Graph Transformer (GT) networks represent scenes as graphs, where nodes denote objects or entities and edges define the relationships between them. This allows the network to explicitly model interactions and dependencies within the scene, going beyond traditional methods that treat frames or pixels independently. The transformer architecture is then applied to these graph representations, enabling the network to learn complex relational reasoning. Specifically, message passing algorithms are utilized to propagate information between nodes, and attention mechanisms weigh the importance of different relationships for a given task. This approach facilitates reasoning about both spatial and temporal dependencies, as the graph structure can be dynamically updated to reflect changes over time, allowing GT networks to effectively capture the context of a scene and predict future events or behaviors.
CCAF-Net improves predictive accuracy by fusing 3D depth data with multi-modal feature sets. The network architecture specifically incorporates depth maps derived from RGB-D sensors or stereo vision, augmenting traditional RGB image features. This integration allows CCAF-Net to better perceive spatial relationships and object sizes within a scene, addressing limitations inherent in 2D-only approaches. Furthermore, the multi-modal input can include features extracted from other sensors, such as LiDAR or thermal cameras, creating a comprehensive environmental representation that facilitates more robust and accurate predictions regarding object trajectories and interactions.
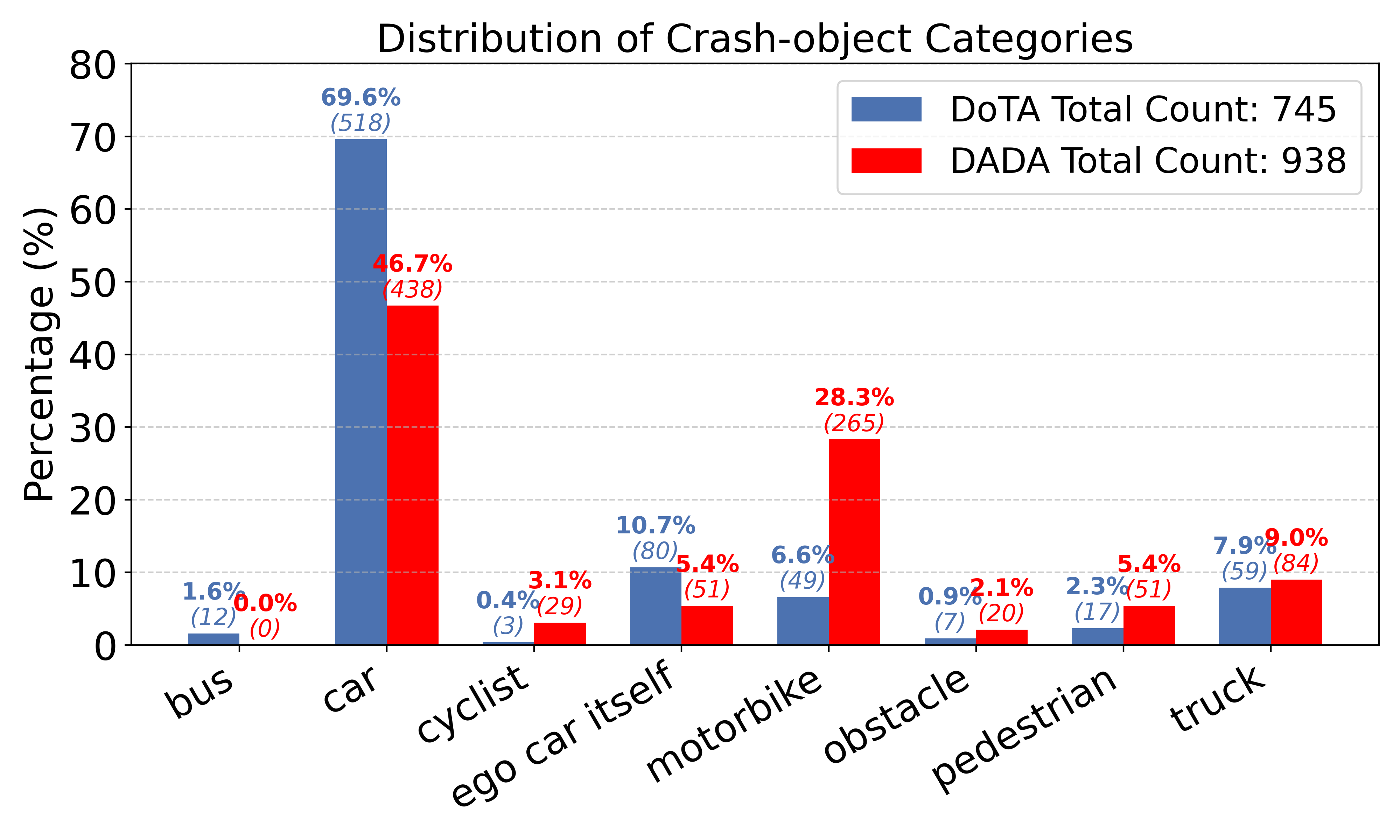
Validating Performance: The Crucible of Comprehensive Datasets
Large-scale datasets, including the Driving Accidents Dataset (DAD), the DOTA dataset, the DADA dataset, and the Nexar dataset, are essential resources for developing and validating accident anticipation systems. These datasets provide diverse and realistic driving scenarios captured from real-world conditions, encompassing a wide range of traffic participants, weather conditions, and road layouts. The inclusion of challenging and rare events, such as near-miss collisions and pedestrian interactions, allows for comprehensive testing of system robustness. Data is typically collected through a combination of sensors, including cameras, LiDAR, and radar, and is annotated with detailed labels indicating potential hazards and future trajectories, enabling supervised learning and performance benchmarking.
Average Precision (AP) and Mean Time-to-Accident (mTTA) serve as primary quantitative measures for evaluating accident anticipation systems. AP assesses the precision of positive predictions, considering both the accuracy and ranking of identified potential accidents; a higher AP indicates a greater ability to correctly identify accidents with fewer false positives. mTTA, measured in seconds, quantifies the amount of time a system predicts before an actual accident occurs; a larger mTTA value signifies earlier and potentially more useful warnings. Both metrics are calculated across diverse and challenging driving scenarios within validation datasets to provide a comprehensive assessment of system performance.
Evaluation of the VAGNet model on benchmark datasets-including DAD, DOTA, DADA, and Nexar-indicates superior performance relative to existing accident anticipation systems. Specifically, VAGNet consistently achieves a higher Average Precision (AP) score, demonstrating improved accuracy in identifying potential accident scenarios. Furthermore, the model exhibits a greater Mean Time-to-Accident (mTTA), signifying an earlier and more proactive prediction capability. These results, obtained through rigorous testing, support the conclusion that VAGNet generalizes effectively to novel driving conditions and offers reliable performance in real-world deployment.
Towards a Proactive Future: Beyond Reaction, Towards Foresight
Advanced Driver Assistance Systems (ADAS) represent a paradigm shift in vehicle safety, moving beyond reactive measures to embrace accident anticipation as a core principle. These systems employ a suite of sensors – including cameras, radar, and lidar – to continuously monitor the vehicle’s surroundings, identifying potential hazards before they escalate into critical situations. By predicting events like pedestrian movements, sudden braking of vehicles ahead, or lane departures, ADAS can preemptively activate safety features such as automatic emergency braking, lane keeping assist, and adaptive cruise control. This proactive approach not only minimizes the severity of collisions but also lays the essential groundwork for the development of fully autonomous vehicles, where the ability to anticipate and react to dynamic environments is paramount. The ongoing refinement of these anticipatory algorithms and sensor technologies promises a future where roadways are significantly safer for all.
Advanced driver-assistance systems are increasingly focused on preventing accidents before they occur, shifting the paradigm from reactive damage control to proactive hazard mitigation. These systems utilize a suite of sensors – including cameras, radar, and lidar – to continuously scan the vehicle’s surroundings, identifying potential dangers such as pedestrians, cyclists, or sudden changes in traffic flow. By anticipating risks, the vehicle can then take preemptive actions, ranging from visual and auditory warnings to automatic braking or steering adjustments. This proactive approach dramatically reduces the likelihood of collisions, offering a substantial improvement over systems that only react after a hazard is detected. Consequently, widespread implementation of these technologies promises not only to minimize vehicle damage but, more importantly, to significantly decrease the number of injuries and fatalities on roadways, moving closer to a future with substantially safer transportation.
The evolution of proactive vehicle safety relies heavily on sustained innovation across multiple disciplines. Current research focuses on refining sensor technologies – including LiDAR, radar, and camera systems – to achieve greater precision in hazard detection, even in adverse conditions. Simultaneously, advancements in artificial intelligence and machine learning algorithms are enabling these systems to not only identify potential threats but also to predict their likely trajectories with increasing accuracy. Crucially, improvements in computational power allow for real-time processing of vast datasets, facilitating quicker and more effective responses. This iterative process of refinement, coupled with rigorous testing and validation, is expected to yield increasingly reliable and robust safety features, ultimately accelerating the widespread adoption of autonomous and semi-autonomous vehicles and dramatically reducing the incidence of traffic accidents.
The pursuit of anticipating chaos, as demonstrated by VAGNet, feels less like engineering and more like divination. This system, bypassing the tedious ritual of object detection to grasp global video features, acknowledges the inherent messiness of reality. It doesn’t find accidents; it senses their approach, much like reading the whispers of impending disorder. Andrew Ng once said, “AI is the new electricity.” But electricity, untamed, is also chaos. VAGNet doesn’t attempt to control that chaos, only to predict its manifestations, offering a fleeting moment to persuade the inevitable. The model, a beautifully complex spell, works until the unpredictable winds of production shift.
The Horizon Beckons
VAGNet offers a glimpse of accident anticipation divorced from the tyranny of bounding boxes, a subtle but significant shift. Yet, the ghosts in the machine remain. This work, like all such endeavors, doesn’t solve anticipation; it re-encodes the problem. The system’s reliance on a pre-trained foundation model, while efficient, invites a familiar question: how much of the ‘understanding’ is truly learned, and how much is cleverly borrowed from datasets already riddled with human bias? The model sees what it has been shown to see, and accidents, by their very nature, often defy expectation.
The true challenge lies not in squeezing marginal gains from existing architectures, but in confronting the inherent unknowability of complex systems. Future work might explore methods to quantify – and even embrace – the model’s uncertainty. Perhaps a system that doesn’t predict whether an accident will happen, but rather maps the probability landscape of potential collisions, offering a spectrum of risk rather than a false promise of certainty.
Ultimately, the pursuit of accident anticipation is a dance with chaos. Each refinement is merely a temporary truce, a localized ordering of the inevitable noise. The goal isn’t to eliminate risk-that’s a phantom-but to navigate it with increasing grace, and to accept that the most informative data will always reside in the errors.
Original article: https://arxiv.org/pdf/2604.09305.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- X-Men ’97 Finally Gave Gambit the Hero Moment He Deserved
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- 46 Years Later, The Mandalorian & Grogu Answers A Major Empire Strikes Back Question
- HoI4 fans harsh reactions to the announcement of another DLC pack
- 10 Worst End-Game Couples In Sitcom History
- Gold Rate Forecast
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Emily Henry Says to ‘Trust the Vision’ For Beach Read Adaptation
- Dragon Quest II HD-2D Remake: Where to get the Magic Key
2026-04-13 18:27