Author: Denis Avetisyan
A new approach to predictive maintenance leverages self-evolving multi-agent systems to enhance reliability and minimize downtime in industrial IoT environments.
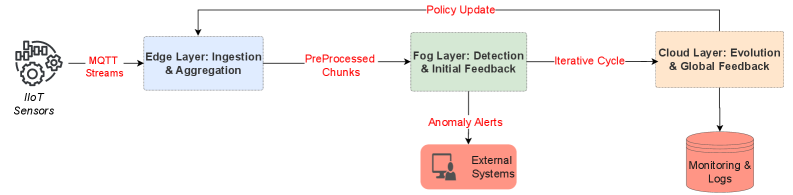
This review details a hierarchical multi-agent system combining edge-fog-cloud computing with reinforcement learning for adaptive anomaly detection and trustworthy predictive maintenance.
Achieving robust and adaptive anomaly detection remains a critical challenge in Industrial IoT predictive maintenance, given the limitations of both static models and computationally intensive monolithic systems. This paper introduces ‘Self-Evolving Multi-Agent Network for Industrial IoT Predictive Maintenance’, presenting SEMAS-a hierarchical multi-agent system distributing specialized agents across edge, fog, and cloud tiers to enable real-time performance without sacrificing interpretability. Empirical results demonstrate that SEMAS achieves superior anomaly detection with exceptional stability through reinforcement learning-driven policy evolution and federated knowledge aggregation. Could this resource-aware, self-evolving architecture represent a paradigm shift toward genuinely deployable, intelligent maintenance solutions for Industry 4.0?
The Inevitable Noise: Why Traditional Monitoring Fails
Traditional predictive maintenance strategies, often reliant on scheduled checks and reactive responses, are increasingly overwhelmed by the sheer volume and intricacy of data generated by modern industrial IoT deployments. These systems, encompassing thousands of sensors and interconnected devices, produce data streams far exceeding the capacity of conventional analytical techniques. The static models and rule-based systems previously employed struggle to discern meaningful patterns amidst this noise, leading to a high rate of false positives or, more critically, missed failure indicators. Consequently, organizations face escalating costs associated with unnecessary interventions or unexpected downtime, highlighting the urgent need for scalable, adaptive approaches capable of effectively managing the complexities of these interconnected industrial environments.
The consequences of equipment failure extend far beyond simple repair costs; downtime disrupts entire production lines, impacts supply chains, and erodes customer trust. While reactive maintenance – addressing issues as they arise – remains prevalent, its inefficiencies are increasingly untenable in today’s interconnected industrial landscape. Shifting to a proactive stance through predictive maintenance offers substantial benefits, yet accurately forecasting failures presents significant hurdles. Traditional models struggle with the sheer volume of data generated by modern systems and often fail to account for evolving operational conditions, leading to both false positives – unnecessary interventions – and, critically, missed detections with potentially catastrophic consequences. Achieving reliable predictive capabilities necessitates overcoming these challenges and developing systems capable of adapting to the dynamic complexities inherent in real-world industrial environments.
Traditional anomaly detection techniques, frequently reliant on static thresholds or historical data patterns, often falter when confronted with the inherent variability of real-world industrial systems. These methods struggle to distinguish between genuine precursors to failure and transient operational shifts caused by changing workloads, environmental factors, or even scheduled maintenance. Consequently, they generate a high volume of false positives, overwhelming maintenance teams and eroding confidence in the system. More sophisticated algorithms, like those based on machine learning, require continuous retraining to remain effective, a computationally expensive process that may not keep pace with rapidly evolving operational conditions. This lack of adaptability means that subtle, yet critical, deviations indicating impending failure can be easily masked by normal fluctuations, ultimately undermining the potential of predictive maintenance to prevent costly downtime and optimize performance.
The escalating complexity of modern industrial systems necessitates a fundamental rethinking of predictive maintenance strategies. Traditional methods, reliant on static models and infrequent analysis, are proving inadequate for environments characterized by constant change and vast data streams. A shift is occurring towards continuous monitoring and real-time analytics, leveraging advancements in machine learning and edge computing to anticipate failures before they impact operations. This paradigm prioritizes adaptive algorithms capable of discerning subtle anomalies within noisy data, and delivering actionable insights with minimal latency. The focus is no longer simply on detecting deviations, but on understanding the context of those deviations and predicting their future trajectory, ultimately enabling proactive intervention and maximizing system uptime.
Distributed Intelligence: A Multi-Agent Approach to Anomaly Detection
The system utilizes a hierarchical Multi-Agent System (MAS) architecture comprised of three tiers: EdgeDevices, FogNodes, and CloudInfrastructure. This tiered approach distributes the computational workload by performing initial data processing at the network edge with EdgeDevices. FogNodes then aggregate and analyze data from multiple EdgeDevices, executing collaborative inference and ensemble detection algorithms. Finally, the CloudInfrastructure provides centralized resources for global optimization of system parameters and the evolution of anomaly detection policies. This distribution enhances scalability by allowing the system to process increasing data volumes and accommodate a growing number of monitored devices without performance degradation, as processing isn’t limited to a single centralized unit.
EdgeDevices within the system are responsible for preprocessing incoming data streams, including feature extraction and noise reduction, to minimize latency and bandwidth requirements. This localized processing reduces the volume of data transmitted to central resources. FogNodes then receive this preprocessed data and perform collaborative inference by combining the outputs of multiple anomaly detection models running on different EdgeDevices. Ensemble detection techniques, such as weighted averaging or majority voting, are employed at the FogNode level to improve the accuracy and robustness of anomaly identification before results are relayed to the CloudInfrastructure.
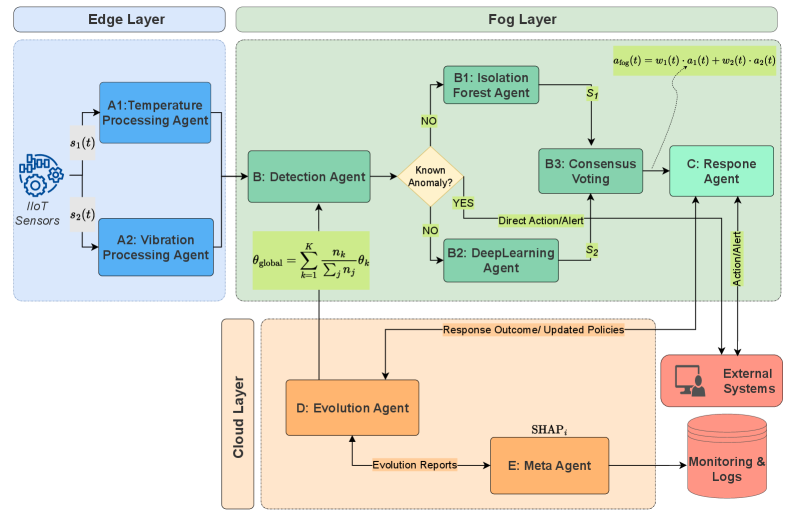
The anomaly detection process within the Multi-Agent System utilizes unsupervised machine learning algorithms, specifically IsolationForest and OneClassSVM. IsolationForest identifies anomalies by explicitly isolating them rather than profiling normal data points, achieving efficiency through tree-based partitioning. OneClassSVM, conversely, learns a boundary around normal data and flags instances falling outside this boundary as anomalies. The system benefits from the complementary strengths of these algorithms; IsolationForest excels at identifying global anomalies, while OneClassSVM is more effective at detecting novel or contextual outliers. Both algorithms require minimal training data representing normal system behavior, making them suitable for dynamic environments where labeled anomaly data is scarce.
CloudInfrastructure within the system furnishes the computational capacity required for both global optimization of anomaly detection models and the evolution of agent policies. This includes the execution of hyperparameter tuning, model retraining using aggregated data from FogNodes, and the implementation of reinforcement learning algorithms to refine agent behavior. Specifically, the Cloud layer handles the computationally intensive tasks of evaluating model performance across the entire dataset, identifying optimal configurations for algorithms like IsolationForest and OneClassSVM, and distributing updated policies to FogNodes for improved anomaly detection accuracy and reduced false positive rates. The scalability of the CloudInfrastructure enables adaptation to increasing data volumes and the incorporation of new data sources without significant performance degradation.
Continuous Refinement: Adaptive Learning and Policy Evolution
The anomaly detection component utilizes a SelfEvolvingPolicy, implemented with the Proximal Policy Optimization (PPO) algorithm, to enable continuous model refinement. PPO facilitates iterative improvements by balancing exploration and exploitation, allowing the system to adapt to evolving data patterns without catastrophic forgetting. This approach differs from static thresholding or fixed-parameter models, enabling the system to dynamically adjust its sensitivity and specificity for anomaly detection. The policy learns to optimize model parameters based on feedback from the environment, specifically focusing on minimizing false positives and false negatives in anomaly identification, leading to a more robust and accurate detection capability over time.
The RULPrediction module employs Long Short-Term Memory (LSTM) networks to forecast the remaining useful life (RUL) of critical components. LSTMs, a recurrent neural network architecture, are particularly suited to time-series data analysis due to their ability to maintain internal state and learn long-term dependencies. Within this module, LSTMs process sequential data representing component health, such as sensor readings and performance metrics, to predict the number of operational cycles remaining before failure. This predictive capability enables proactive maintenance scheduling and minimizes the risk of unexpected downtime, improving system reliability and operational efficiency.
FederatedAggregation enables model training across multiple decentralized datasets without direct data exchange. This is achieved by transmitting only model updates – specifically, gradient information – from each participating agent to a central server. The server aggregates these updates to create an improved global model, which is then distributed back to the agents. This process preserves data privacy as the raw data remains localized and never leaves the individual agents’ control. The technique utilizes secure aggregation protocols to further protect against potential privacy breaches during the update transmission and aggregation phases, ensuring compliance with data governance regulations.
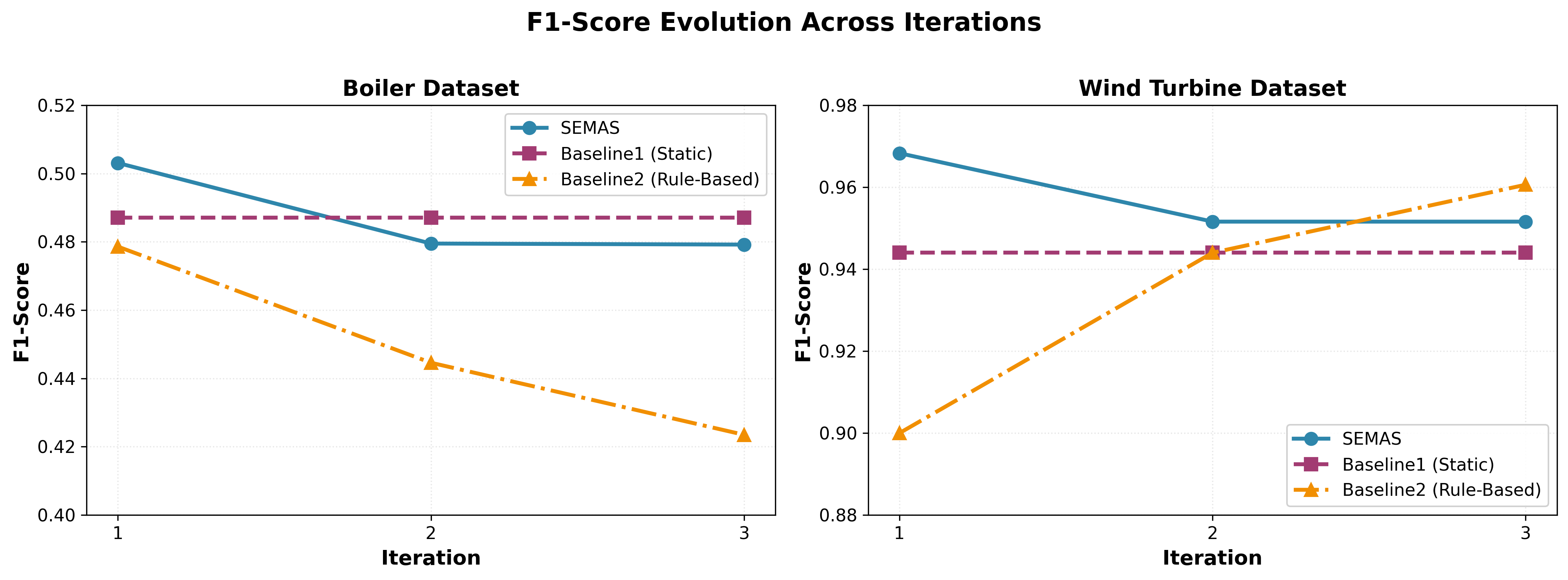
ConsensusVoting is implemented as a method for aggregating predictions from multiple agents within the system, enhancing both the robustness and accuracy of anomaly detection. This approach utilizes a voting mechanism to determine the final prediction, mitigating the impact of individual agent errors. Evaluation on the Boiler dataset demonstrated an 8.6% improvement in F1-score when compared to a rule-based adaptation strategy, indicating a statistically significant performance gain achieved through the combined intelligence of multiple predictive models.
Beyond Prediction: Explainability and Resource-Aware Deployment
The anomaly detection system leverages ExplainableAI, specifically employing SHAP (SHapley Additive exPlanations) values to illuminate the reasoning behind its predictions. Rather than functioning as a ‘black box’, the system deconstructs each anomaly assessment, quantifying the contribution of individual input features – such as temperature, pressure, or vibration frequency – to the final outcome. This granular level of insight allows operators to not only identify that an anomaly exists, but also to understand why it was flagged, fostering trust in the system’s judgment and enabling more informed, targeted interventions. By pinpointing the critical factors driving each detection, SHAP values empower proactive maintenance and reduce the time required to diagnose and resolve issues, ultimately enhancing operational efficiency and safety.
ResourceAwareDeployment represents a dynamic approach to managing computational demands within the anomaly detection system. Instead of static allocation, the system intelligently distributes agents and models based on real-time resource availability – prioritizing critical tasks and adapting to fluctuating workloads. This involves a careful balancing act; less demanding anomalies might be assessed by smaller, faster models running on limited hardware, while complex scenarios trigger the deployment of more robust models on more powerful infrastructure. Consequently, the system avoids bottlenecks, minimizes latency, and maximizes throughput, leading to a significant improvement in overall efficiency and responsiveness. The strategy ensures that valuable computational resources are consistently applied where they have the greatest impact, thereby optimizing performance without necessitating costly hardware upgrades.
The convergence of explainable artificial intelligence and resource-aware deployment cultivates a critical foundation for confident system integration and proactive operational control. By revealing the reasoning behind anomaly detections – identifying the specific factors influencing predictions – stakeholders gain a deeper understanding of system behavior, moving beyond ‘black box’ outcomes. This transparency is paired with optimized resource allocation, ensuring efficient performance even under constrained conditions. Consequently, decisions are no longer solely reliant on algorithmic outputs, but informed by a clear understanding of why those outputs are generated, leading to more effective interventions, reduced risk, and ultimately, greater trust in the system’s reliability and long-term value.
The system exhibits a marked capacity for adaptation and scalability, translating directly into substantial reductions in operational costs associated with downtime and maintenance. Evaluations demonstrate a dramatic improvement in processing speed, achieving up to 1500 times faster inference latency – a critical advantage for real-time anomaly detection. This enhanced performance is coupled with strong diagnostic accuracy, as evidenced by Receiver Operating Characteristic Area Under the Curve (ROC-AUC) values of 0.6118 when applied to boiler systems and 0.7583 for wind turbine monitoring. These results suggest a significant leap toward proactive maintenance strategies, minimizing disruptions and extending the lifespan of critical infrastructure through efficient and timely interventions.
The pursuit of self-evolving systems, as presented in this exploration of SEMAS, inevitably courts future complications. The architecture, while promising adaptive anomaly detection through hierarchical multi-agent collaboration at the edge, fog, and cloud levels, simply delays the accumulation of technical debt. Donald Davies observed, “It is not the computer that makes the error, but the human who programs it.” This rings particularly true; even the most elegant reinforcement learning algorithms are ultimately brittle when confronted with the unpredictable realities of production environments. The system may learn to predict failures, but the cost of maintaining that predictive capability-the constant recalibration and adaptation-will inevitably mount. It’s a beautifully complex mechanism, designed to simplify maintenance, yet destined to become another layer of abstraction to manage.
What’s Next?
The presented hierarchical multi-agent system, while logically structured, invites the inevitable question of operationalization. The elegance of distributed reinforcement learning will, predictably, encounter the blunt force of real-world sensor drift, communication latency, and the sheer cost of maintaining agents across an industrial network. The promise of adaptive anomaly detection is appealing, yet scaling these systems beyond a controlled laboratory environment introduces a familiar pattern: diminishing returns on increasingly complex architectures. The edge-fog-cloud integration, touted as a strength, simply shifts the burden of failure; a broken agent at the edge is still a broken agent, regardless of where the intelligence resides.
Future work will undoubtedly focus on ‘robustness’ and ‘generalizability’ – industry euphemisms for ‘we haven’t accounted for every possible failure mode.’ Explainable AI, a particularly thorny issue, will require more than post-hoc justification; truly trustworthy systems necessitate inherent transparency, a quality rarely prioritized during initial development. The current emphasis on reinforcement learning, while effective in simulation, will likely yield to hybrid approaches combining model-based reasoning with data-driven adaptation – a tacit admission that pure learning is insufficient.
Ultimately, the true test lies not in achieving theoretical optimality, but in minimizing the total cost of ownership. If code looks perfect, no one has deployed it yet. The next phase will reveal whether this system reduces downtime or simply introduces a more sophisticated – and expensive – way to complicate everything.
Original article: https://arxiv.org/pdf/2602.16738.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Brent Oil Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- EUR ZAR PREDICTION
2026-02-21 05:53