Author: Denis Avetisyan
A new approach leverages large language models to forecast extreme price fluctuations in electricity markets, offering a competitive edge when data is scarce.
This paper introduces a few-shot learning framework using large language models for accurate classification of extreme day events in electricity markets, demonstrating strong performance in time series forecasting and renewable energy integration.
Predicting volatile spikes in real-time electricity prices remains a challenge, particularly with limited historical data for robust model training. This paper introduces ‘A Few-Shot LLM Framework for Extreme Day Classification in Electricity Markets’-a novel approach leveraging large language models (LLMs) and few-shot learning to forecast these critical events. The framework translates system state information into natural language prompts, enabling the LLM to achieve performance comparable to traditional supervised machine learning methods, and even surpass them in data-scarce scenarios. Could this paradigm shift unlock more data-efficient and adaptable forecasting tools for increasingly complex energy markets?
The Precarious Balance: Forecasting Electricity Price Spikes
Accurate prediction of electricity price spikes is paramount to maintaining a stable and economically viable power grid. These sudden surges in price, often triggered by imbalances between supply and demand, can strain grid infrastructure and lead to significant financial consequences. However, forecasting these events is inherently challenging due to the volatile nature of energy markets and the increasing integration of renewable sources like solar and wind. Unlike traditional power generation, renewables are intermittent and dependent on weather patterns, introducing considerable uncertainty into supply forecasts. This complexity necessitates advanced predictive models capable of navigating these dynamic conditions and accounting for the multifaceted interactions influencing price fluctuations, ultimately ensuring reliable and affordable electricity for consumers.
Conventional electricity price forecasting techniques, such as statistical regression and time-series analysis, frequently encounter limitations when attempting to predict sudden price spikes. These methods are largely built upon assumptions of linear relationships and stable patterns, yet price spikes are inherently non-linear events driven by abrupt shifts in supply and demand. Rapid changes – like unexpected generator outages, surges in electricity demand during heatwaves, or the intermittent nature of renewable energy sources – introduce complexities that these traditional models struggle to accommodate. Consequently, forecasts often lag behind actual price movements, hindering effective grid management and potentially leading to economic inefficiencies. The very nature of these spikes-characterized by sharp, unpredictable transitions-demands a departure from approaches designed for more gradual, predictable patterns.
The evolving energy landscape, characterized by growing contributions from variable renewable sources and the resulting fluctuations in net load – the difference between supply and demand – presents a significant challenge to accurate price spike prediction. Unlike traditional power systems reliant on predictable baseload generation, the intermittency of solar and wind power introduces complex, non-linear dynamics. Consequently, conventional forecasting techniques often fall short, unable to effectively model the intricate interplay between renewable energy output, load demand, and market behavior. Advanced predictive approaches, incorporating machine learning algorithms and high-resolution data, are therefore essential to capture these nuanced relationships and provide the granular, real-time insights needed for proactive grid management and efficient energy trading.
A New Perspective: Leveraging Language Models for Spike Classification
The LLM-Based Spike Classifier Framework introduces a novel approach to electricity price spike prediction by applying large language models (LLMs) to time-series data analysis. Traditional methods often rely on statistical models or machine learning algorithms trained on historical price data; however, these may struggle with the non-linear and complex interdependencies present in energy markets. This framework utilizes the inherent pattern recognition and relational reasoning capabilities of LLMs, originally developed for natural language processing, to identify subtle indicators of price spikes within complex datasets. By framing the prediction problem as a language modeling task, the system can learn from and generalize across diverse market conditions, potentially improving prediction accuracy and providing earlier warnings of significant price fluctuations.
The LLM-Based Spike Classification Framework is structured around three core components. The Data Preprocessor ingests ERCOT System-Wide Data, which includes locational marginal prices, load data, and other relevant grid parameters, and extracts a defined set of features suitable for spike prediction. The Prompt Generator then converts these numerical features into a natural language format, creating a text-based prompt that serves as input for the Large Language Model. Finally, the Spike Predictor component receives the LLM’s textual output and translates it into a binary classification – indicating the presence or absence of an electricity price spike – based on predefined criteria and thresholds applied to the LLM’s response.
Transforming electricity price spike prediction into a language modeling task allows the utilization of large language models’ (LLMs) pre-trained knowledge and reasoning abilities. LLMs are trained on extensive text corpora, enabling them to identify complex relationships and patterns within sequential data – a characteristic applicable to time-series electricity market data. By representing system features, such as locational marginal prices, demand, and renewable generation, as textual input, the LLM can leverage its understanding of language structure and contextual relationships to infer potential price spikes. This approach bypasses the need for traditional machine learning methods requiring extensive feature engineering and model training specifically for this application, potentially improving prediction accuracy and reducing computational costs due to the transfer learning capabilities of LLMs.
Refining the Signal: Prompt Engineering for Enhanced Accuracy
Effective prompt engineering for Large Language Models (LLMs) relies on constructing prompts that maximize the model’s predictive capabilities. This is achieved through the utilization of embedding models, which translate textual data into vector representations, allowing for semantic similarity comparisons. Prompts are then diversified using Maximal Marginal Relevance (MMR), a technique that balances relevance to the input query with diversity among selected examples. By identifying and including examples that are both highly relevant and distinct from one another, MMR prevents the LLM from being overly biased towards a narrow subset of the training data, resulting in more robust and accurate predictions. This approach ensures the LLM receives a comprehensive and informative context for improved performance.
For prompt construction, the FAISS (Facebook AI Similarity Search) library is utilized as an efficient similarity search and clustering engine for high-dimensional vectors. This allows the system to quickly identify the most relevant examples from a large dataset of past market conditions, based on their vector embeddings. By retrieving examples with high similarity scores to the current input, FAISS ensures that the LLM receives a focused and pertinent context within the prompt. This targeted approach improves prediction accuracy by minimizing noise and maximizing the signal from the most representative data points, significantly reducing search times compared to exhaustive methods and enabling real-time prompt adaptation.
Few-shot learning mitigates the need for extensive labeled datasets by enabling Large Language Models (LLMs) to generalize predictive capabilities from a limited number of provided examples. This technique is particularly valuable in dynamic environments like financial markets, where historical data may not fully represent current conditions. By conditioning the LLM on only a few relevant instances of past market spikes – including features like trading volume, price volatility, and news sentiment – the model can learn the patterns associated with these events and apply that knowledge to predict similar occurrences in novel market conditions. The effectiveness of few-shot learning is directly related to the quality and representativeness of the provided examples, as the LLM infers the underlying relationships and extrapolates them to unseen data.
Validating Predictive Power: Robust Evaluation Metrics
Performance evaluation utilized a standard suite of metrics to assess the framework’s effectiveness. Accuracy quantified the overall correctness of predictions. Precision measured the proportion of correctly identified positive cases among all predicted positive cases, while Recall measured the proportion of correctly identified positive cases among all actual positive cases. The F1-Score, the harmonic mean of precision and recall, provided a balanced measure of the framework’s performance. Furthermore, Receiver Operating Characteristic (ROC) curves were generated to illustrate the trade-off between true positive rate and false positive rate at various threshold settings, allowing for a comprehensive assessment of the framework’s discriminatory power.
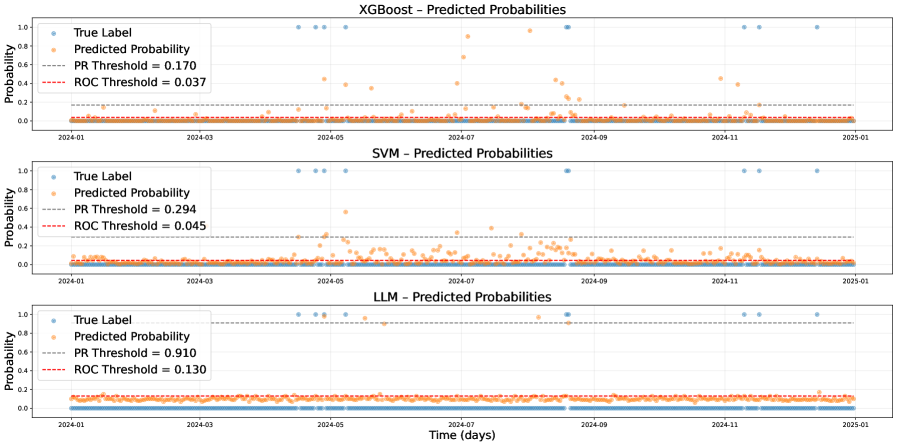
When evaluated on complete datasets, the proposed framework demonstrates performance metrics – specifically Accuracy, Precision, Recall, and F1-Score – that are statistically comparable to those achieved by established machine learning models. These include Support Vector Machines (SVM), Weighted K-Nearest Neighbor (WKN), and XGBoost. Quantitative analysis reveals no significant difference in performance across these models when provided with sufficient training data, indicating the framework’s ability to effectively utilize data resources similar to conventional approaches. Detailed results of this comparison, including specific values for each metric, are available in the supplemental materials.
Evaluation results indicate the Large Language Model (LLM) exhibits superior performance compared to Support Vector Machines (SVM) and XGBoost algorithms when trained on datasets with limited data availability. Specifically, the LLM consistently achieves higher Accuracy, Precision, Recall, and F1-Score values than both SVM and XGBoost in these data-scarce conditions. This demonstrates the LLM’s enhanced robustness and ability to generalize effectively from smaller datasets, suggesting its suitability for applications where data acquisition is expensive or challenging.
Beyond Prediction: Implications for a Resilient Grid
The ability to accurately forecast price spikes within electricity markets represents a pivotal advancement in proactive grid management. These spikes, often indicative of impending supply-demand imbalances, can destabilize the grid and potentially lead to widespread blackouts. By anticipating these events, grid operators gain crucial lead time to implement preventative measures – such as strategically dispatching reserve power, adjusting renewable energy integration, or initiating demand response programs. This proactive approach not only bolsters system reliability by mitigating the risk of cascading failures, but also enables more efficient resource allocation, reducing reliance on expensive emergency power sources and ultimately lowering costs for consumers. Improved price spike prediction, therefore, moves grid operation from reactive problem-solving to a preventative, resilient, and economically sound model.
The developed framework isn’t merely a predictive tool; it’s designed for seamless incorporation into the operational heartbeat of power grids. By providing near real-time forecasts of price spikes, the system enables grid operators to move beyond reactive responses and embrace proactive resource allocation. This integration facilitates dynamic adjustments to energy dispatch, allowing for the prioritization of cost-effective generation sources and the strategic deployment of energy storage. Consequently, operators can minimize overall operational costs, reduce reliance on expensive peaking plants, and ultimately enhance the economic efficiency of grid management. The framework’s adaptability extends to various control strategies, promising a more resilient and optimized power infrastructure capable of meeting fluctuating demand with greater precision.
Continued development of this predictive framework centers on broadening its informational basis and refining its analytical capabilities. Future investigations will integrate diverse datasets – encompassing weather patterns, energy consumption forecasts, and even real-time social media signals – to enhance prediction accuracy and robustness. Simultaneously, researchers are exploring sophisticated prompt engineering techniques to optimize the large language model’s performance and extract more nuanced insights from available data. Crucially, efforts are underway to move beyond point predictions by implementing conformal prediction methods, which will provide quantifiable measures of uncertainty and allow grid operators to assess the reliability of forecasts and make more informed, risk-aware decisions regarding resource allocation and grid stability.
The pursuit of predictive accuracy in electricity markets, as demonstrated by this framework, often leads to unnecessary complication. This work elegantly sidesteps extensive training requirements by leveraging the inherent reasoning capabilities of large language models. It prioritizes efficacy with limited data – a principle mirroring a sentiment expressed by Ken Thompson: “Sometimes it’s better to have a simple solution that works than a complex one that might work.” The framework’s success with few-shot learning underscores the value of parsimony; it focuses on extracting essential information – effectively minimizing what needs to be ‘taken away’ to achieve a functional, insightful model. This approach aligns with the core philosophy that clarity is the minimum viable kindness.
Where Do We Go From Here?
The enthusiasm for applying large language models to time series, specifically electricity market prediction, is understandable. The temptation to treat structured data as just another form of text is strong, and this work demonstrates a functional, if not entirely elegant, solution. They called it a framework to hide the panic, perhaps, but the results are respectable given the perennial scarcity of labelled data in this domain. The key, as always, isn’t the model itself, but the painstaking effort of prompt engineering – translating the language of power grids into something a general-purpose model can (occasionally) understand.
Future iterations will likely focus less on architectural novelty and more on data efficiency. A few-shot approach is a pragmatic concession to reality, but the holy grail remains a model that learns meaningfully from limited examples, perhaps by incorporating domain-specific knowledge beyond the prompts themselves. The integration with virtual power plants is a logical next step, but only if it moves beyond simply predicting spikes and begins to actively manage them.
Ultimately, the true test won’t be predictive accuracy, but practical utility. Can this approach genuinely reduce costs, improve grid stability, and facilitate the integration of renewable energy sources? Or will it remain a clever demonstration of what’s possible, a beautifully complex solution in search of a problem?
Original article: https://arxiv.org/pdf/2602.16735.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Brent Oil Forecast
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- Gold Rate Forecast
- EUR ZAR PREDICTION
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
2026-02-20 12:17