Author: Denis Avetisyan
A new survey explores the growing vulnerabilities to personal data exposed by artificial intelligence systems used in social media platforms.
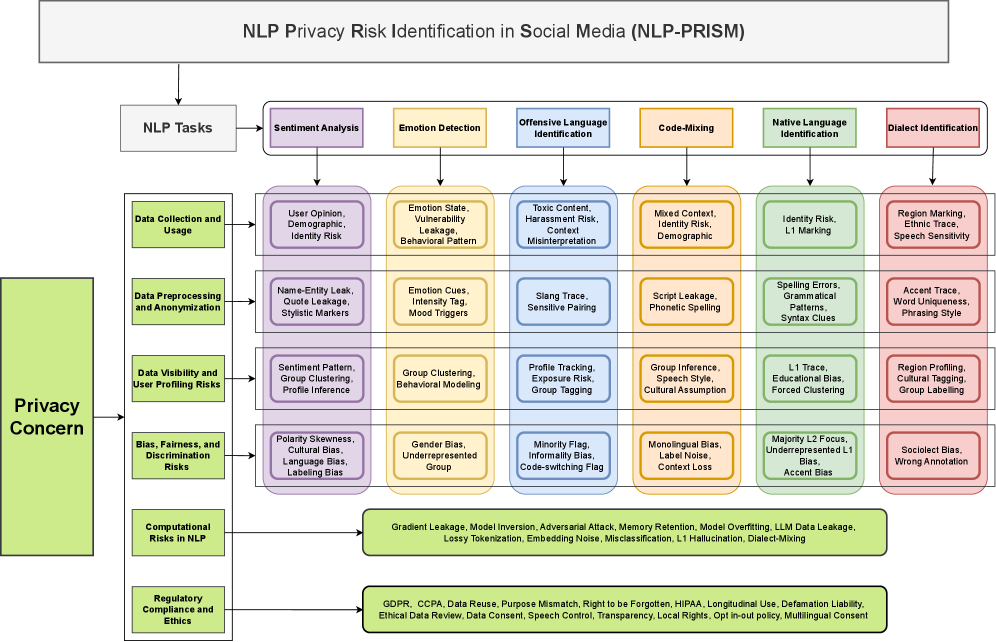
This review systematically identifies and categorizes privacy risks in social media natural language processing, proposing a framework for mitigation and emphasizing the need for privacy-preserving techniques in large language model development.
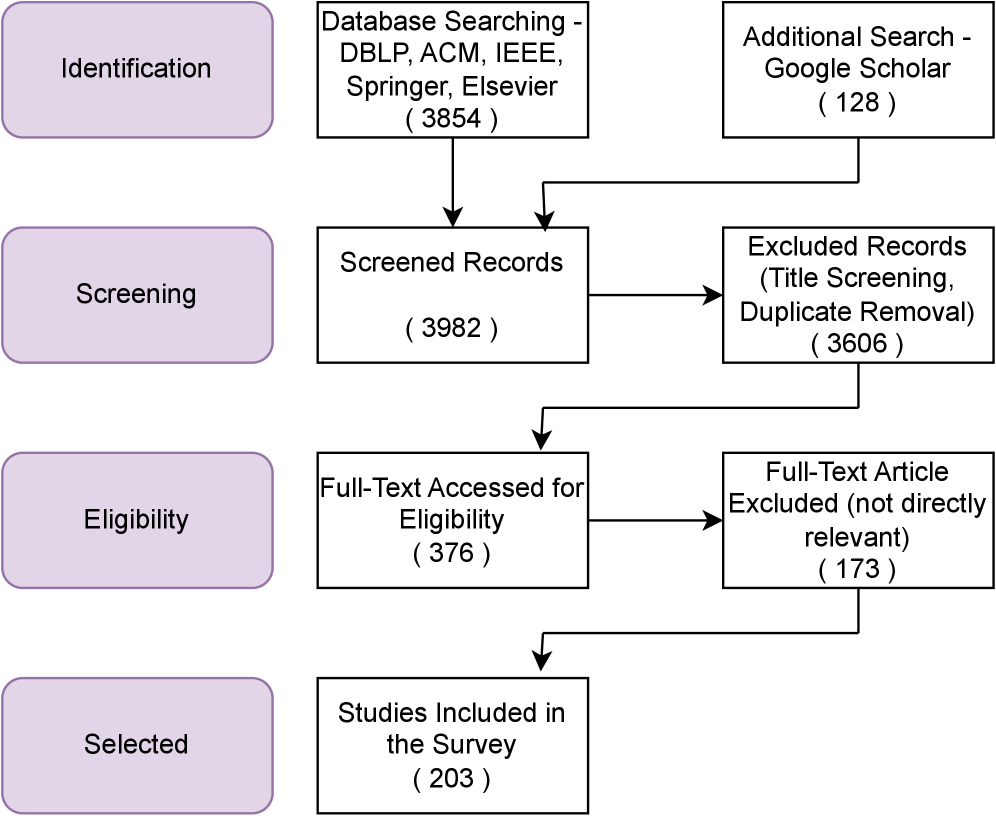
While Natural Language Processing unlocks valuable insights from social media data, it simultaneously introduces significant privacy vulnerabilities concerning personally identifiable information and behavioral profiling. This paper, ‘NLP Privacy Risk Identification in Social Media (NLP-PRISM): A Survey’, systematically addresses this paradox through a comprehensive review of 203 peer-reviewed works and the introduction of the NLP-PRISM framework for characterizing privacy risks across data collection, model training, and deployment. Our analysis reveals substantial gaps in privacy research within core NLP tasks-sentiment analysis, emotion detection, and beyond-and demonstrates a measurable trade-off between model utility and privacy preservation, with performance reductions ranging from 1% to 23% under privacy-preserving fine-tuning. How can we proactively design and implement privacy-aware NLP techniques to foster both innovation and ethical data handling in social media contexts?
The Data Stream and the Erosion of Privacy
The proliferation of social media has created an unprecedented torrent of user-generated content – text posts, images, videos, and more – which now serves as the primary engine driving advancements in Natural Language Processing. This constant stream of data provides the massive datasets needed to train and refine increasingly sophisticated algorithms capable of understanding, interpreting, and even generating human language. Machine learning models, particularly those leveraging deep learning techniques, thrive on scale, and social media platforms deliver this in abundance. The sheer volume allows for the identification of nuanced patterns and subtle linguistic cues that would be impossible to detect with smaller datasets, leading to breakthroughs in areas like sentiment analysis, topic modeling, and machine translation. Consequently, innovations in NLP are now inextricably linked to the continued growth and activity within these online social spaces.
The proliferation of user-generated content, while driving innovation in areas like natural language processing, concurrently establishes substantial privacy vulnerabilities. Personal information is frequently interwoven within seemingly innocuous posts, images, and videos, creating a rich landscape for data extraction. Studies demonstrate that sophisticated attacks can readily identify and aggregate this embedded data, revealing sensitive details about individuals – from their location and social networks to their habits and beliefs. This isn’t limited to explicit disclosures; even metadata and implicit cues within content can be exploited. The sheer volume of data generated daily amplifies these risks, making proactive defense a critical challenge as traditional privacy safeguards struggle to keep pace with evolving attack vectors and the scale of potential breaches.
Current privacy methodologies struggle to cope with the sheer volume and intricate nature of data generated by modern platforms. Existing techniques, often designed for smaller, more structured datasets, prove inadequate when confronted with the constant stream of user-generated content. A recent analysis reveals a critical gap in research, with a mere 10% of publications actively addressing privacy challenges within this expanding data landscape. This scarcity highlights an urgent need for systematic, scalable privacy solutions – frameworks that move beyond reactive measures to proactively safeguard personal information embedded within the ever-growing digital deluge. The lack of focused research suggests a substantial vulnerability, demanding innovative approaches to ensure data security and user privacy in the age of big data.
NLP-PRISM: A Framework for Mitigating Privacy Risks
The NLP-PRISM framework systematically characterizes privacy risks in User-Generated Content (UGC) processing by employing a four-stage methodology: identification of sensitive data elements within UGC, assessment of re-identification potential based on data characteristics and contextual factors, quantification of privacy risk using defined metrics, and prioritization of mitigation strategies. This process moves beyond simple keyword detection to analyze linguistic patterns and semantic relationships indicative of Personally Identifiable Information (PII). The framework supports both rule-based and machine learning approaches to risk characterization, enabling adaptability to diverse UGC formats and evolving privacy threats. Output from this process provides a structured risk profile detailing the likelihood and impact of potential privacy breaches, facilitating informed decision-making regarding data handling and anonymization techniques.
The NLP-PRISM framework integrates a Cross-Cultural Privacy Framework to address the variability in privacy expectations across different user demographics and geographical regions. This incorporation recognizes that perceptions of what constitutes Personally Identifiable Information (PII) and acceptable data handling practices are not universal; norms differ significantly based on cultural, legal, and societal factors. By acknowledging these diverse expectations, NLP-PRISM facilitates a more nuanced risk assessment, moving beyond a single, standardized definition of privacy to accommodate regional and cultural sensitivities when processing User-Generated Content. This approach aims to enhance user trust and ensure compliance with a broader range of privacy regulations globally.
NLP-PRISM facilitates the implementation of data anonymization techniques designed to address identified vulnerabilities in user data processing. Recent evaluations demonstrate the framework’s efficacy in mitigating Membership Inference Attacks (MIA), achieving an Area Under the Curve (AUC) of up to 0.81, indicating a strong ability to conceal individual data contributions. Furthermore, NLP-PRISM supports techniques that limit Attribute Inference Attacks (AIA), reaching an accuracy of up to 0.75 in preventing the accurate deduction of sensitive attributes. These metrics reflect the framework’s capacity to enhance data privacy by reducing the potential for re-identification and attribute disclosure through advanced anonymization strategies.
Advanced Anonymization: Beyond Simple Redaction
Data anonymization is a core component of privacy risk mitigation, extending beyond simple redaction due to the increasing sophistication of data re-identification methods. While removing directly identifying information such as names and addresses is a foundational step, it is often insufficient to prevent the reconstruction of individual identities through the correlation of seemingly innocuous data points. Modern privacy threats leverage techniques like statistical inference and linkage attacks, necessitating the implementation of more advanced anonymization strategies that preserve data utility while minimizing re-identification risk. These strategies include generalization, suppression, and perturbation methods, which alter data values to obscure individual records without completely eliminating their analytical value.
Named Entity Masking (NEM) and Text Perturbation are advanced data anonymization techniques that move beyond simple redaction by replacing or modifying sensitive information with plausible alternatives. NEM specifically targets and replaces identified entities – such as names, addresses, and dates – with generic placeholders or synthetic data, preserving the overall structure and relationships within the text. Text Perturbation encompasses a broader range of transformations, including synonym replacement, paraphrasing, and back-translation, designed to alter the surface form of the text while retaining its core meaning. Both techniques aim to minimize the risk of re-identification while maintaining data utility for analytical purposes, enabling continued processing and modeling without directly exposing personally identifiable information.
Implementation of Named Entity Masking and Text Perturbation within the NLP-PRISM framework demonstrably increases data privacy; however, this enhancement is associated with a quantifiable reduction in model performance. Testing has revealed that utilizing these techniques can result in a performance degradation of up to 23% as measured by the F1 score. Consequently, practitioners must carefully calibrate the degree of anonymization applied to achieve an acceptable equilibrium between robust privacy protections and maintained data utility for downstream analytical tasks.
OVERRIDE: Contextualizing Privacy Controls
The OVERRIDE model represents an advancement in user privacy by extending the capabilities of the NLP-PRISM framework with context-aware controls. Rather than applying uniform anonymization techniques, OVERRIDE dynamically adjusts privacy protections based on the specific application and the sensitivity of the data involved. This nuanced approach recognizes that not all data usage scenarios pose equal privacy risks; for example, data used for broad trend analysis might require less stringent protection than data used to personalize individual experiences. By considering the context of data processing – the task being performed, the intended audience, and the potential impact on individuals – OVERRIDE enables a more responsible and flexible approach to data handling, ultimately seeking to balance the need for privacy with the desire to unlock the valuable insights contained within user-generated content.
Traditional data anonymization often involves broad generalizations that strip valuable information, hindering the performance of Natural Language Processing tasks. The OVERRIDE model addresses this limitation by enabling a more granular approach, recognizing that the level of privacy required varies depending on the specific application. This means sensitive details are masked to a greater extent when processing data for potentially identifying tasks, while allowing more information to remain intact when the task focuses on general trends or insights. By dynamically adjusting the anonymization process, OVERRIDE strives to strike a critical balance: preserving data utility for effective NLP, while simultaneously upholding robust privacy protections, ultimately fostering innovation without compromising individual rights.
The OVERRIDE model directly addresses a critical need for responsible innovation in handling User-Generated Content by proactively embedding privacy considerations into data processing. This approach not only minimizes potential risks – as demonstrated by its ability to achieve Member Inference Attack (MIA) Area Under the Curve (AUC) values up to 0.81, indicating strong resilience against attribute disclosure – but also cultivates greater user trust. Furthermore, OVERRIDE’s Attributable Identification Accuracy (AIA) reaching 0.75 signifies a balance between privacy preservation and maintaining data utility, allowing for meaningful analysis without compromising individual anonymity. By effectively mitigating privacy breaches and preserving data value, OVERRIDE encourages the ethical and sustainable development of Natural Language Processing applications that rely on user contributions.
The survey meticulously details the escalating privacy risks inherent in Natural Language Processing applications on social media platforms. It acknowledges the complex interplay between data extraction, algorithmic bias, and potential adversarial attacks-a confluence demanding systematic characterization. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything.” This resonates deeply with the study’s core tenet: the vulnerability isn’t necessarily in the creation of the NLP models, but in the unintended consequences arising from their application to sensitive social data. The NLP-PRISM framework, therefore, represents a deliberate attempt to understand and mitigate those consequences, moving beyond mere innovation toward responsible deployment.
What’s Next?
The proliferation of frameworks, however elegantly constructed, often obscures a simple truth: the core problem isn’t a lack of categorization, but an excess of data collection. NLP-PRISM, as presented, is a useful taxonomy of harms, yet ultimately treats symptoms, not the disease. Future effort should not concentrate on finer-grained risk identification, but on architectures that demonstrably minimize data’s exposure in the first place. The pursuit of ‘more accurate’ models frequently justifies increasingly invasive practices; a necessary re-evaluation of that trade-off is paramount.
Large language models, predictably, represent a new layer of complexity. The current emphasis on ‘alignment’ feels suspiciously like applying bandages to a self-inflicted wound. True progress lies not in attempting to control emergent behavior, but in designing systems where such behavior is inherently limited – a return to principles of parsimony. The field seems intent on building ever-larger fortresses around sensitive information; perhaps it’s time to simply build fewer castles.
Bias and adversarial attacks, predictably, will continue to evolve. These are not static problems to be ‘solved’, but perpetual pressures on any system. The focus should shift from reactive defense to proactive design – building models that are not merely robust against attacks, but fundamentally uninteresting targets for them. The aspiration should not be invulnerability, but insignificance.
Original article: https://arxiv.org/pdf/2602.15866.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Brent Oil Forecast
- Gold Rate Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- EUR ZAR PREDICTION
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
2026-02-19 19:47