Author: Denis Avetisyan
A new framework leverages composable contracts to guarantee performance and accountability across distributed AI services.
This review details a high-fidelity network management approach utilizing Tail-Risk Envelopes for robust Federated AI-as-a-Service deployment across multiple administrative domains.
Achieving predictable performance for AI-as-a-Service (AIaaS) is increasingly challenging as deployments span multiple administrative domains. This paper, ‘High-Fidelity Network Management for Federated AI-as-a-Service: Cross-Domain Orchestration’, introduces a novel assurance-oriented management plane leveraging composable contracts-Tail-Risk Envelopes (TREs)-to enforce end-to-end performance guarantees in federated AIaaS environments. By combining deterministic guardrails with stochastic network calculus, we derive bounds on tail latency and enable risk-budget decomposition for multi-domain accountability. Can this approach unlock truly reliable and scalable AIaaS offerings, paving the way for more complex and latency-sensitive applications?
The Inevitable Shift: AIaaS and the Tail Risk We Knew Was Coming
Communication Service Providers (CSPs) are undergoing a significant transformation, evolving beyond simply providing network connectivity to becoming key enablers of intelligent applications through Artificial Intelligence as a Service (AIaaS). This shift represents a fundamental change in their core business model, positioning them as providers of not just bandwidth, but also the computational resources and network performance necessary to support demanding AI workloads. Rather than guaranteeing average network performance, CSPs are increasingly focused on delivering the consistently low latency and high bandwidth required for real-time AI processing, effectively becoming an integral part of the AI application stack. This move towards AIaaS allows CSPs to unlock new revenue streams, foster innovation in areas like edge computing, and solidify their position as crucial infrastructure providers in an increasingly AI-driven world.
Artificial Intelligence as a Service (AIaaS) demands a re-evaluation of conventional network performance metrics. While average latency has historically sufficed for many applications, the nuanced demands of AI – particularly machine learning inference – reveal its inadequacy. AI models often exhibit drastically reduced accuracy when subjected to even brief periods of high latency, meaning that the 99th or 99.9th percentile latency – representing rare, but impactful, performance events – becomes the critical performance indicator. This sensitivity stems from the sequential nature of many AI workloads; a delay in receiving a single data point can propagate through the entire model, leading to significant errors. Consequently, service providers must prioritize guaranteeing performance at these extreme percentiles to ensure reliable AI service delivery and maintain user trust, rather than focusing solely on overall average performance.
The increasing reliance on Artificial Intelligence as a Service (AIaaS) introduces a critical challenge known as ‘Tail Risk’ – the possibility of infrequent, yet substantial, performance declines that disproportionately impact AI model effectiveness and the end-user experience. Unlike traditional network performance metrics focused on average conditions, AI applications are acutely sensitive to extreme performance percentiles; even brief periods of high latency or packet loss can severely degrade model accuracy. To address this, a novel framework has been developed to quantify and manage this tail risk, enabling the establishment of performance budgets and clear accountability across the diverse administrative domains involved in delivering AIaaS. This approach moves beyond simply meeting average performance targets and instead focuses on proactively minimizing the probability of rare, high-impact failures, ensuring a consistently reliable and accurate AI experience.
Beyond Averages: Contracts for the Inevitable Tail
Traditional performance metrics such as average latency are insufficient for evaluating the suitability of network infrastructure for AIaaS applications, which are highly sensitive to tail latency. A Tail Contract shifts the focus from mean performance to guaranteeing performance at extreme percentiles – specifically, the p99 and p99.9 percentiles – representing the worst-case performance experienced by a small fraction of requests. This approach recognizes that even infrequent performance degradations can significantly impact AI model accuracy and user experience. By defining service level objectives (SLOs) based on these extreme percentiles, network operators can prioritize infrastructure investments and configurations to ensure consistently low latency for critical AI workloads, rather than optimizing for overall average performance.
The Tail-Risk Envelope (TRE) formalizes performance contracts for AIaaS by defining quantifiable latency bounds at extreme percentiles, specifically the p99 and p99.9 levels. This is achieved through a mechanism that allows for the composition of performance assurances across multiple network domains, enabling end-to-end guarantees in federated AIaaS deployments. Unlike traditional Service Level Agreements (SLAs) focused on average performance, TREs concentrate on bounding tail latency, critical for applications sensitive to infrequent but significant delays. The composable nature of TREs facilitates the verification of cumulative performance as requests traverse different network segments, providing a robust framework for managing latency in distributed AI systems.
The Tail-Risk Envelope (TRE) leverages the Moment Generating Function (MGF) – a mathematical tool used to characterize the probability distribution of a random variable – to formally define and verify performance bounds. Specifically, the MGF, denoted as M_X(t) = E[e^{tX}] , allows for the calculation of moments of the random variable X, such as mean and variance. By analyzing the MGF, engineers can determine the probability that latency will exceed a specified threshold at a given percentile (e.g., p99). This rigorous analytical approach enables quantifiable guarantees on tail latency, facilitating the composition of performance assurances across diverse network segments and the validation of service level objectives for AIaaS applications.
Auditing the Inevitable: Extreme Value Theory to the Rescue
Extreme Value Theory (EVT) is a branch of statistics dealing with the extreme behavior of random variables. Unlike methods that rely on assumptions of specific probability distributions, EVT focuses directly on modeling the tail of a distribution, enabling the estimation of quantities like Value-at-Risk (VaR) and Expected Shortfall. This is achieved through techniques such as the Generalized Extreme Value (GEV) distribution for block maxima and the Generalized Pareto Distribution (GPD) for exceedances over a threshold. EVT differs from traditional methods by focusing on the asymptotic distribution of extremes, allowing for extrapolation beyond observed data to estimate probabilities of rare events-specifically, the probability of exceeding a given high percentile. Accurate estimation of these extreme percentiles is crucial for applications requiring assessment of low-probability, high-impact risks, and relies on the convergence properties of the limiting distributions described by EVT.
The Peak-Over-Threshold (POT) method, a component of Extreme Value Theory (EVT), facilitates the estimation of the tail behavior of a distribution using observed telemetry data. This involves defining a high threshold, and modeling the exceedances – values above that threshold – using a Generalized Pareto Distribution (GPD). Parameters of the GPD, such as the shape and scale, are then estimated from the exceedances. These estimates allow for the calculation of extreme quantiles – values at very low probabilities – which are crucial for validating Tail-Risk Estimates (TREs). Accurate estimation of tail behavior via POT informs the confidence level associated with TREs, indicating the probability that actual performance will remain within acceptable bounds during rare, high-load events.
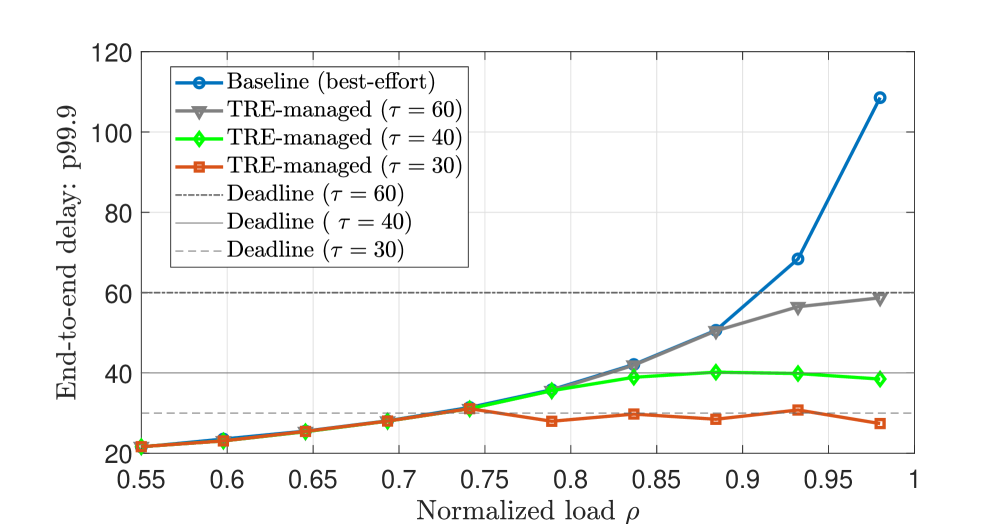
Stochastic Network Calculus (SNC) provides a mathematical framework for bounding end-to-end delay in network systems when used in conjunction with Traffic Rate Envelopes (TREs). Experimental results indicate that utilizing TREs maintains observed delay close to a defined deadline τ even under fluctuating network load. In contrast, a best-effort queuing approach without TREs exhibited a substantial and rapid increase in delay as load increased. This demonstrates that SNC, combined with TREs, enables predictable performance crucial for latency-sensitive AI applications by providing guaranteed delay bounds.
Federated AIaaS: The Promise and Peril of Distributed Intelligence
The evolution of AI as a Service (AIaaS) is increasingly directed toward federated models, envisioning a network where AI capabilities are distributed across numerous independent operator domains. This departure from centralized services promises a significantly expanded and more robust AI ecosystem, capable of handling larger datasets and more complex tasks than any single entity could manage alone. By enabling collaboration and resource sharing, federation unlocks the potential for specialized AI models to be combined and deployed in novel ways, fostering innovation and accelerating the development of intelligent applications. This distributed approach also enhances resilience, as the failure of one domain does not necessarily compromise the overall functionality of the system, ensuring continuous service availability and scalability to meet growing demands.
The expansion of AI as a Service (AIaaS) towards a federated model-where services span multiple independent domains-introduces significant challenges in resource coordination and accountability. Unlike centralized systems, federation necessitates robust mechanisms to ensure each entity reliably contributes to the collective AI ecosystem while maintaining data privacy and operational integrity. Traditional approaches to trust and security prove inadequate; instead, novel strategies are required to verify the contributions of each participant, manage potential conflicts, and prevent malicious behavior without compromising sensitive information. This demands a shift towards decentralized trust models, potentially leveraging cryptographic techniques and verifiable computation to establish accountability and guarantee the consistent delivery of AI services across a distributed network of providers. Successfully navigating these hurdles is crucial for realizing the full potential of federated AIaaS and fostering a truly collaborative and trustworthy AI landscape.
The advancement of federated AIaaS relies on effective coordination between diverse operators, yet this must occur without compromising data privacy. Research demonstrates that the Alternating Direction Method of Multipliers (ADMM) offers a compelling solution, enabling the provisioning of AI services across federated domains while safeguarding user data. Specifically, studies reveal that a TRE-managed operation, leveraging ADMM, consistently maintained a stable p99.9 delay – a critical performance metric – even under fluctuating workloads. In contrast, systems employing a shared FIFO multiplexing approach exhibited a significant increase in p99.9 delay as attacker burstiness intensified, highlighting the superior resilience and privacy-preserving capabilities of ADMM in a federated environment. This suggests ADMM is crucial for building a robust and secure AI ecosystem where collaboration doesn’t come at the expense of individual privacy.
Operationalizing AIaaS: MLOps, APIs, and the Inevitable Bottlenecks
Successfully deploying Artificial Intelligence as a Service (AIaaS) demands more than just model creation; it requires robust Machine Learning Operations (MLOps) practices. MLOps provides a disciplined framework for managing the entire lifecycle of AIaaS, encompassing continuous integration, delivery, and monitoring of models within the network infrastructure. This isn’t simply about automation; it’s about ensuring consistent performance, reliability, and scalability of AI-driven services. Through meticulous monitoring, MLOps identifies and addresses model drift, data quality issues, and performance bottlenecks, proactively preventing service degradation. By embedding quality assurance throughout the AIaaS lifecycle, MLOps establishes trust and allows for continuous improvement, ultimately maximizing the value derived from these complex, network-integrated systems.
Application Programming Interfaces, or APIs, function as crucial bridges, enabling developers to seamlessly integrate artificial intelligence capabilities and network services into diverse applications and systems. This exposure isn’t merely about accessibility; it actively cultivates innovation by empowering a broader community to build upon existing AI foundations. Rather than requiring specialized machine learning expertise for every new application, APIs allow developers to leverage pre-trained models and network functionalities as modular components. This democratization of AI fosters rapid prototyping, accelerates the development cycle, and unlocks opportunities for novel solutions across a multitude of domains, from enhanced mobile applications to intelligent automation within enterprise networks. The ease with which these services can be incorporated directly impacts the rate of AI adoption and the emergence of previously unforeseen applications.
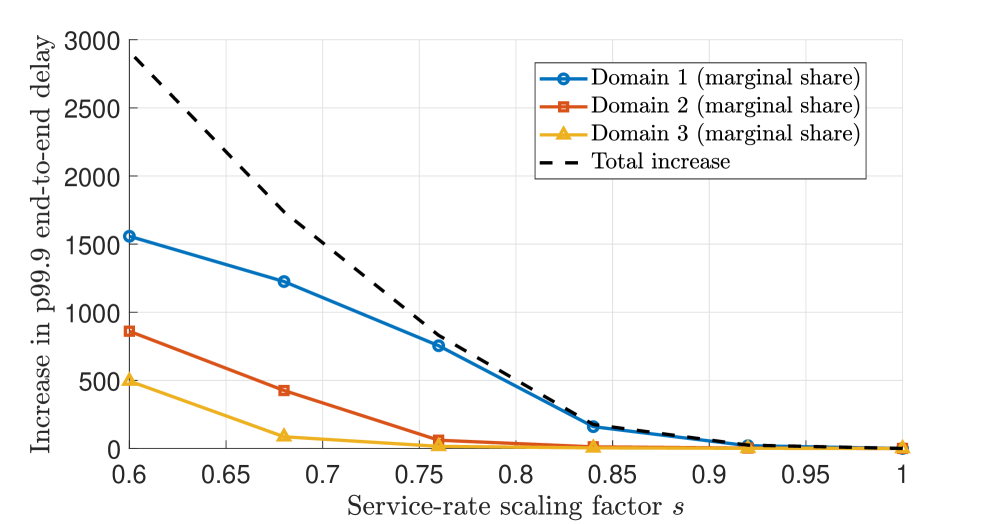
Network performance and efficient resource allocation for federated AIaaS deployments are rigorously validated through simulations employing First-In, First-Out (FIFO) queuing combined with Stochastic Network Calculus (SNC). This methodology allows for a detailed analysis of service guarantees under varying load conditions, revealing that certain operational domains contribute disproportionately to increases in tail-risk – the probability of extreme performance degradation. Consequently, targeted accountability measures can be implemented, focusing on optimizing resource allocation and refining operational procedures within these critical domains to bolster the overall reliability and resilience of the AIaaS infrastructure. This proactive approach minimizes the potential for service disruptions and ensures consistent performance even under peak demand or unexpected network events.
The pursuit of seamless, end-to-end performance in federated AIaaS, as detailed in the framework, feels predictably optimistic. It’s a beautifully structured attempt to tame inherent chaos, to impose order on distributed systems that actively resist it. This echoes a sentiment captured by Blaise Pascal: “All of humanity’s problems stem from man’s inability to sit quietly in a room alone.” The framework’s composable contracts – the Tail-Risk Envelopes – represent just such an attempt to sit quietly with the inevitable unpredictability of production. They are elegant diagrams destined to be stress-tested, and inevitably, broken, by the realities of cross-domain orchestration. At least they die beautifully, defining the boundaries of acceptable failure before the inevitable cascade.
So, What Breaks First?
This exploration of composable contracts and Tail-Risk Envelopes for federated AIaaS feels…predictable. A beautifully engineered attempt to impose order on a fundamentally chaotic system. The premise – guaranteeing performance across administrative domains – is, of course, laudable. One suspects production environments will respond by finding increasingly creative ways to violate those guarantees. It’s not a matter of if, but when a rogue data pipeline or an unexpected network congestion event renders these carefully constructed TREs…less effective. The elegance of the framework merely delays the inevitable realization that everything new is old again, just renamed and still broken.
The real challenge isn’t defining these contracts, it’s enforcing them. Or, more accurately, understanding why they failed. Expect a surge in post-incident analysis focused on identifying edge cases and unforeseen interactions. Perhaps future work will center not on increasingly sophisticated contract definitions, but on automated remediation strategies. A system that doesn’t prevent failure, but gracefully accepts it.
Ultimately, this framework, like all others, will be stress-tested by the relentless pressure of real-world usage. The true metric of success won’t be the number of guarantees made, but the speed with which the system recovers when those guarantees inevitably crumble. Production is, after all, the best QA, and one anticipates a wealth of data generated from the ensuing failures.
Original article: https://arxiv.org/pdf/2602.15281.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- All Itzaland Animal Locations in Infinity Nikki
- Paramount CinemaCon 2026 Live Blog – Movie Announcements Panel for Sonic 4, Street Fighter & More (In Progress)
- Cthulhu: The Cosmic Abyss Chapter 3 Ritual Puzzle Guide
- Persona PSP soundtrack will be available on streaming services from April 18
- Raptors vs. Cavaliers Game 2 Results According to NBA 2K26
- Spider-Man: Brand New Day LEGO Sets Officially Revealed
- Focker-In-Law Trailer Revives Meet the Parents Series After 16 Years
- Rockets vs. Lakers Game 1 Results According to NBA 2K26
- Dungeons & Dragons Gets First Official Actual Play Series
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
2026-02-18 21:40