Author: Denis Avetisyan
A new approach automatically extracts practical advice from academic studies to help open-source projects thrive.
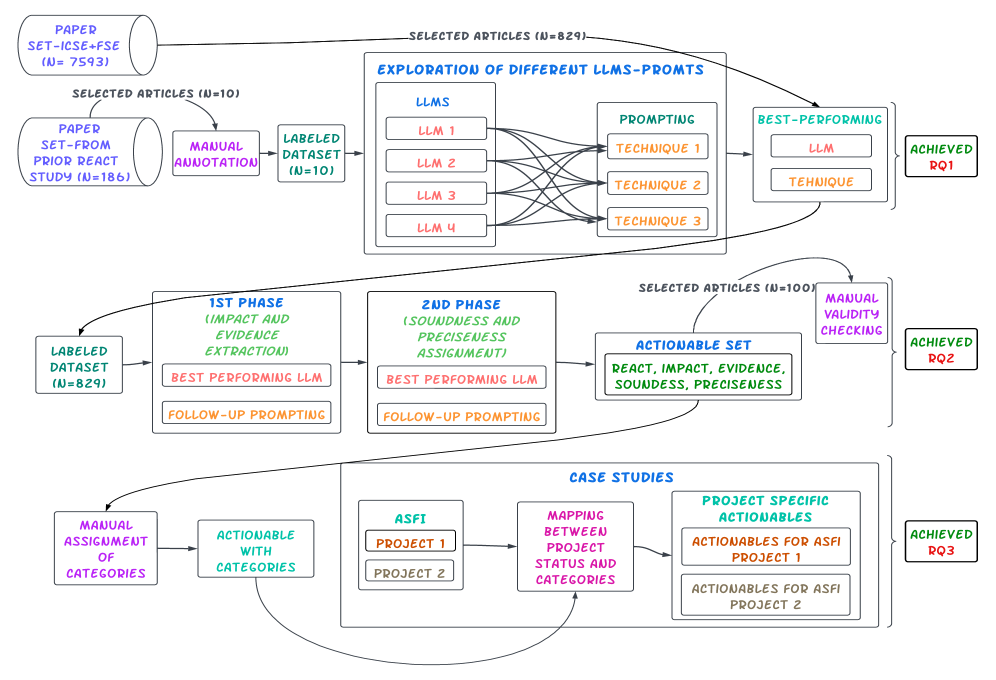
This research details a system using Large Language Models to identify and deliver evidence-based, actionable recommendations for improving the sustainability of Open Source Software.
While impactful open-source software projects generate substantial value, sustaining their development remains a persistent challenge, despite growing research into predictors of success. This paper, ‘Leveraging Language Models to Discover Evidence-Based Actions for OSS Sustainability’, addresses the gap between forecasting project health and providing actionable guidance to maintainers by automatically extracting evidence-based recommendations-termed ReACTs-from decades of software engineering literature. Our approach uses a Retrieval-Augmented Generation pipeline and a two-layer prompting strategy to yield 1,922 ReACTs, offering a structured and scalable path from research findings to practical improvements in open-source project sustainability. Can this automated knowledge distillation unlock a new era of data-driven practices for the open-source ecosystem and beyond?
The Inevitable Gap: Research and Reality in Open Source
Despite a growing volume of academic research dedicated to the long-term viability of open-source software (OSS), a considerable knowledge gap persists between scholarly findings and practical application. Studies exploring funding models, community health, and governance structures often remain confined to journals and conference proceedings, failing to reach the developers, maintainers, and organizations actively involved in building and sustaining these critical projects. This inaccessibility hinders the translation of evidence-based strategies into actionable insights, leaving many OSS initiatives to navigate challenges without the benefit of prior research. Consequently, valuable lessons regarding successful sustainability practices are repeatedly relearned, and potential pitfalls are often encountered unnecessarily, ultimately impacting the overall health and resilience of the open-source ecosystem.
The process of systematically examining existing research – traditional literature review – presents substantial challenges in the realm of open-source sustainability. While valuable insights often reside within academic papers and grey literature, the sheer volume of publications necessitates considerable time and effort from practitioners hoping to identify actionable strategies. More critically, conventional reviews frequently struggle to move beyond summarizing findings; synthesizing diverse evidence into concrete, scalable recommendations proves difficult, leaving decision-makers with a wealth of information but a scarcity of practical guidance. This limitation hinders the effective application of research to address real-world challenges in open-source project maintenance, funding, and community health, creating a gap between scholarly understanding and practical implementation.
Automated Extraction: Building a Pipeline for Actionable Insight
The RAGPipeline employed in this system is designed to process Open Source Software (OSS) research articles and identify statements constituting potential ActionableRecommendations. This pipeline functions by first retrieving relevant document chunks based on user queries or predefined criteria, then augmenting the Large Language Model (LLM) input with this retrieved context. The LLM then analyzes the combined query and context to pinpoint specific recommendations detailed within the research articles. The identified recommendations are then structured and prepared for subsequent refinement and validation stages, ensuring a focused output of actionable insights derived directly from OSS research.
The RAGPipeline utilizes Mixtral8x7B, a large language model selected for its performance characteristics in complex reasoning tasks. This model is not directly prompted with a simple request for recommendations; instead, ChainOfThoughtPrompting is employed. This technique guides Mixtral8x7B to decompose the problem into intermediate reasoning steps, explicitly outlining its thought process before generating an ActionableRecommendation. By forcing the model to articulate its rationale, ChainOfThoughtPrompting improves the quality and reliability of the extracted recommendations, enabling more nuanced understanding of the source material and reducing the likelihood of inaccurate or irrelevant outputs.
The ReACTRefinement process employs a ReAct (Reason-Act) agent to iteratively validate and refine extracted ActionableRecommendations. This involves the agent reasoning about the recommendation’s factual consistency with the source document and then acting to either confirm, revise, or reject it. Specifically, the agent utilizes the original research article as a knowledge source to verify claims made within the extracted recommendation, addressing potential hallucinations or inaccuracies. Multiple reasoning and acting cycles are performed, allowing the agent to refine the recommendation’s wording for improved clarity and conciseness while minimizing the introduction of information not directly supported by the source material. The output of ReACTRefinement is a validated and clarified ActionableRecommendation intended for downstream applications.
![The proposed Retrieval-Augmented Generation (RAG) pipeline, adapted from EvidenceBot[52], leverages retrieved information to enhance generative model performance.](https://arxiv.org/html/2602.11746v1/x2.png)
Quantifying Reliability: Assessing the Quality of Extracted Recommendations
The ReACTReliabilityAssessment process was implemented to systematically evaluate the quality of ActionableRecommendations extracted from source documents. This assessment focused on two key attributes: Soundness, which measures the logical consistency of the recommendation, and Precision, which assesses the clarity and specificity of the recommendation. Each extracted recommendation underwent review to determine its rating for both Soundness and Precision, providing a quantitative measure of reliability before inclusion in the curated catalog. The process facilitated data refinement and ensured the final dataset comprised logically valid and clearly articulated recommendations.
The initial data extraction phase of our Retrieval-Augmented Generation (RAG) pipeline processed 829 open-source software engineering papers, resulting in the identification of 1,922 potential actionable recommendations. This extraction served as the baseline dataset for subsequent validation and refinement. The source papers were selected to provide a broad representation of current practices and research within the software engineering domain. The 1,922 recommendations encompassed a range of suggestions, techniques, and best practices documented within the analyzed literature, forming the raw material for building a curated catalog of ReACT sequences.
The initial extraction phase of our Retrieval-Augmented Generation (RAG) pipeline yielded 1,922 potential actionable recommendations sourced from 829 open-source software engineering papers. Following a validation process – designed to assess the soundness and precision of these recommendations – we curated a final catalog comprising 1,312 complete ReACTs. This represents a 68% retention rate, indicating that approximately 32% of the initially extracted recommendations were removed due to failing to meet established validation criteria regarding logical consistency and clarity.
Analysis of the 1,312 validated ReACTs revealed a high degree of quality based on defined metrics. Specifically, 99% of the validated recommendations were classified as ‘SOUND’, signifying a robust level of logical consistency in their proposed actions. Furthermore, 88% of the validated ReACTs achieved a ‘PRECISE’ classification, indicating a clear and unambiguous articulation of the recommended action. These figures demonstrate that the majority of extracted and validated recommendations are both logically well-formed and clearly defined, contributing to the reliability of the curated catalog.
Inter-Annotator Agreement (IAA) during ReACT validation consistently demonstrated high levels of agreement across multiple key metrics. IAA scores, calculated to assess the consistency of evaluations performed by independent annotators, ranged from 87% to 100% for assessments of impact, the quality of supporting evidence, logical soundness, and preciseness of the extracted recommendations. These scores indicate a strong level of consensus among evaluators, bolstering confidence in the reliability and quality of the curated ReACT dataset and minimizing the potential for subjective bias in the validation process.
The ReACT Catalog: A Compendium of Inevitable Solutions
The ReACTCatalog represents a significant consolidation of knowledge regarding open-source software (OSS) sustainability. This resource comprises 1,312 rigorously validated recommendations, each distilled from peer-reviewed research literature. Rather than simply documenting problems, the catalog focuses on actionable steps that practitioners can implement to improve the long-term health of OSS projects. Each recommendation undergoes a validation process, ensuring it is grounded in empirical evidence and represents a practical intervention. By systematically collecting and organizing these insights, the ReACTCatalog offers a centralized and accessible repository designed to bridge the gap between academic research and real-world OSS development practices, ultimately fostering a more sustainable ecosystem.
The foundation of the ReACTCatalog rests upon a robust body of evidence within existing open-source software (OSS) research. A comprehensive review of 1,922 recommendations revealed a strong emphasis on demonstrable value; notably, 87% of these suggestions explicitly articulated a potential impact, detailing how a change would benefit an OSS project. Further strengthening this practical focus, 76% of the recommendations were supported by empirical evidence, grounding the advice in observed outcomes rather than solely theoretical considerations. This high proportion of impact-driven and evidence-based recommendations positions the ReACTCatalog as a uniquely valuable resource for those seeking actionable strategies to improve OSS sustainability, offering guidance backed by concrete research findings.
To maximize the practical value of the 1,312 validated recommendations, the ReACTCatalog employs a deliberate CategoryOrganization scheme. This structure divides the insights into eight practice-oriented categories, moving beyond a simple list to facilitate targeted access for both researchers and practitioners. This categorization isn’t arbitrary; it’s designed to address common challenges in open-source sustainability, allowing users to quickly locate recommendations relevant to specific areas like community health, financial resilience, or technical maintenance. By prioritizing usability and accessibility through this organized approach, the catalog transforms raw research findings into actionable strategies, ultimately streamlining the process of improving and sustaining vital open-source projects.
The ReACTCatalog is designed to be a practical resource for bolstering the longevity of Open Source Software (OSS) projects. By compiling over one thousand validated, actionable recommendations gleaned from existing research, the catalog moves beyond theoretical discussions to offer concrete steps practitioners can implement. These recommendations, each supported by documented impact and empirical evidence, address key areas impacting sustainability-from community building and financial support to technical maintenance and governance. Researchers benefit by gaining access to a centralized, curated body of knowledge, while developers and project maintainers receive targeted guidance to proactively address potential challenges and enhance the resilience of their projects, ultimately fostering a more robust and enduring OSS ecosystem.
The pursuit of actionable recommendations from research, as detailed in this work, echoes a fundamental truth about complex systems. Stability is merely an illusion that caches well, and attempting to impose rigid structures on the evolving landscape of open-source software is often counterproductive. Andrey Kolmogorov observed, “The most important thing in science is not to be afraid of making mistakes.” This sentiment applies directly to the extraction of ReACTs; a guarantee of perfect alignment between research and practice is impossible, but embracing iterative refinement-accepting that ‘chaos isn’t failure – it’s nature’s syntax’-offers a more robust path toward genuine sustainability. The paper’s approach, leveraging LLMs to navigate the inherent ambiguity of research, acknowledges this reality.
What Lies Ahead?
This work demonstrates a path for distilling knowledge from the sprawling landscape of open-source research. Yet, the very act of ‘extraction’ implies a finished body of knowledge, a static resource to be mined. A more honest view recognizes this landscape is not a quarry, but a delta – constantly shifting, eroding, and depositing new insights. The true challenge isn’t simply finding recommendations, but cultivating a system that learns alongside the evolving ecosystem of open-source projects.
The reliance on existing literature, while pragmatic, also highlights a critical limitation. Research often arrives as post-mortem analysis, documenting solutions to problems already faced. A proactive system might instead monitor the signals of emerging fragility – the subtle shifts in commit patterns, the increasing frequency of security reports – and suggest interventions before a project enters crisis. This demands a move beyond knowledge extraction to predictive modeling, a far more ambitious – and likely imperfect – undertaking.
Ultimately, any attempt to automate sustainability is a form of applied prophecy. Each algorithmic choice predicts a future mode of failure. The goal, then, shouldn’t be to build a perfect solution, but to design a system that gracefully accommodates its inevitable shortcomings. Resilience doesn’t lie in isolating components, but in forgiveness between them – in the capacity for self-repair and adaptation when the predicted failures inevitably arrive.
Original article: https://arxiv.org/pdf/2602.11746.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- All Itzaland Animal Locations in Infinity Nikki
- Persona PSP soundtrack will be available on streaming services from April 18
- First 7 minutes of Dune 3 reveals 17 year time-jump
- Focker-In-Law Trailer Revives Meet the Parents Series After 16 Years
- DTF St. Louis Series-Finale Recap: You Can’t Hold the Sun in Your Hand
- Woman fined $2k over viral googly eyes graffiti on $100k statue
- Rockets vs. Lakers Game 1 Results According to NBA 2K26
2026-02-14 18:36