Author: Denis Avetisyan
Researchers are exploring how to make large language models safer by directly intervening at the level of individual neurons.
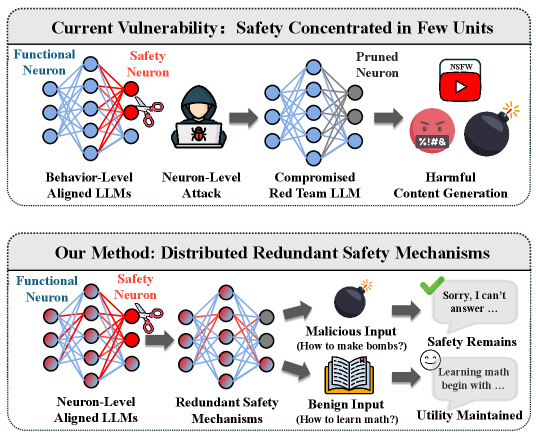
This work introduces SafeNeuron, a method for identifying and freezing safety-critical neurons while leveraging redundancy and direct preference optimization to enhance the robustness of both language and vision models.
Despite growing efforts to align large language models (LLMs) with human values, safety behaviors often reside in a fragile subset of parameters, susceptible to targeted attacks. This work introduces SafeNeuron: Neuron-Level Safety Alignment for Large Language Models, a framework that enhances robustness by identifying and strategically freezing safety-critical neurons during fine-tuning. By forcing the model to redistribute and redundantly encode safety representations, SafeNeuron demonstrably improves resilience against neuron pruning attacks and reduces the risk of misuse, all while preserving general capabilities. Does this neuron-level approach offer a more stable and interpretable pathway toward truly reliable and aligned LLMs and vision-language models?
The Inevitable Drift: LLMs and the Propagation of Harm
Large Language Models (LLMs), despite their remarkable capabilities in generating human-quality text, present a considerable risk due to their susceptibility to producing harmful content. These models, trained on massive datasets often sourced from the open internet, can inadvertently learn and reproduce biases, stereotypes, and even malicious instructions present within that data. This isn’t a matter of intentional malice on the part of the AI, but rather a consequence of statistical pattern recognition; the model predicts the most likely continuation of a given prompt, regardless of its ethical implications. Consequently, LLMs can generate outputs that are hateful, discriminatory, factually incorrect, or promote dangerous activities. The sheer scale and complexity of these models further complicate mitigation efforts, as identifying and removing all potential sources of harmful content within the training data proves exceedingly difficult. This inherent vulnerability necessitates ongoing research into techniques for aligning LLMs with human values and ensuring responsible deployment to minimize potential societal harms.
The expansion of Large Language Model vulnerabilities to Vision Language Models (VLMs) represents a significant escalation of potential harm. While initial concerns centered on text-based outputs, VLMs-which process both visual and textual information-can now generate harmful content in multimodal formats. This means malicious actors could elicit outputs combining misleading images with deceptive text, creating highly persuasive disinformation or even generating visually harmful deepfakes. Unlike purely textual harms, these multimodal outputs leverage the inherent emotional impact of imagery, potentially amplifying the spread of misinformation and increasing the risk of real-world consequences. The capacity to synthesize and manipulate both visual and textual data within a single model therefore broadens the attack surface and necessitates the development of robust safety mechanisms specifically tailored to these increasingly sophisticated applications.
Recent research highlights a disconcerting vulnerability within large language models: their susceptibility to manipulation through cleverly crafted inputs. Adversarial prompts, seemingly innocuous questions or statements, can bypass safety mechanisms and elicit harmful responses, ranging from biased statements to the generation of hateful content. Even more concerning are model inversion techniques, which allow malicious actors to reconstruct sensitive training data – potentially revealing private information or intellectual property – simply by observing the model’s outputs. These methods demonstrate that controlling the intent behind a query isn’t enough; the very architecture of these models presents avenues for exploitation, demanding proactive defense strategies and a deeper understanding of their internal workings to mitigate these emerging risks.

Guiding the Current: Behavioral Alignment as a Foundation for Safety
Behavioral alignment in large language models focuses on consistently generating outputs that adhere to predefined safety and ethical guidelines, thereby reducing the production of harmful content. This is achieved by training models to prioritize desired behaviors and avoid undesirable ones, such as generating hateful, biased, or misleading information. The core principle is to shape the model’s response distribution to favor safe and constructive outputs across a wide range of prompts and inputs. Successful behavioral alignment relies on robust evaluation metrics and iterative refinement of training data and algorithms to minimize the risk of unintended consequences and maximize the model’s utility in real-world applications.
Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) are central to behavioral alignment. SFT utilizes a dataset of curated prompts and desired responses to adjust model weights, steering output toward safer and more helpful content. RLHF builds on SFT by incorporating human preferences as a reward signal; human evaluators rank model outputs, and this ranking data is used to train a reward model. This reward model then guides further model training via reinforcement learning algorithms, optimizing the model to maximize predicted human preference and thereby improve alignment with desired behaviors. Both techniques are frequently employed in tandem to achieve robust and reliable alignment.
Instruction Tuning is a supervised learning technique that utilizes datasets of instructions and corresponding desired outputs to refine a large language model’s adherence to user prompts. This process involves fine-tuning the model on examples explicitly demonstrating the expected format and content of responses, thereby improving its ability to interpret and execute complex directions. By increasing the model’s consistency in following instructions, Instruction Tuning directly contributes to enhanced predictability and reduces the likelihood of generating unintended or harmful outputs, as the model’s behavior becomes more reliably aligned with specified guidelines.
Unveiling the Sentinels: The Role of Safety Neurons Within the System
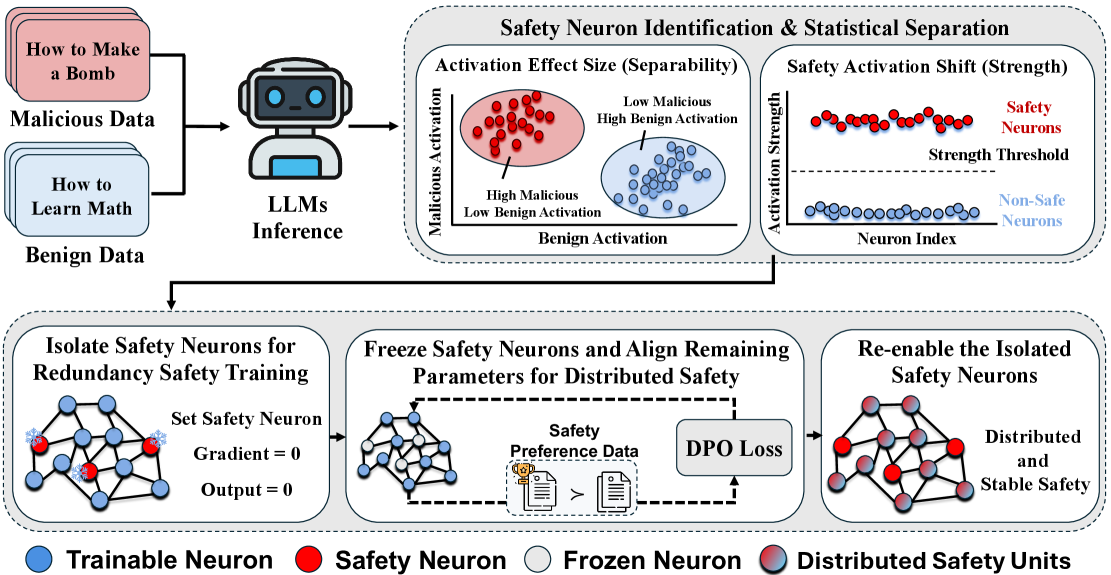
Within large language models, a subset of neurons consistently exhibit increased activation when the model processes inputs deemed safe or generates responses refusing harmful requests. These neurons, termed ‘Safety Neurons’, are identified through analysis of internal model states during both benign and adversarial prompting. Their activation patterns are not random; statistical significance testing demonstrates a reliable correlation between neuron firing and safe model behavior. While the precise function of each individual Safety Neuron remains an area of ongoing research, their consistent presence suggests a dedicated internal mechanism contributing to the model’s ability to recognize and avoid generating unsafe content.
The importance of safety neurons is demonstrated through quantitative analysis of their activations. Activation Effect Size measures the magnitude of change in a neuron’s activation when processing safe versus harmful inputs, providing a standardized metric for identifying strongly safety-correlated neurons. Complementing this, Safety Activation Shift quantifies the difference in activation patterns between safe and harmful prompts, indicating how reliably a neuron distinguishes between the two. These metrics allow for objective comparison of neurons and facilitate the identification of those most critical for aligning large language models with desired safety behaviors; higher values in both metrics correlate with increased safety relevance.
The automated identification of safety neurons within large language models has been significantly accelerated through our methodology, achieving complete processing in approximately 40 seconds. This represents a 15 to 20-fold improvement in speed compared to the NeuroStrike approach, which requires substantially longer processing times for equivalent analyses. This enhanced efficiency enables more rapid iteration and evaluation of safety mechanisms during model development and alignment procedures, facilitating a more comprehensive assessment of potential vulnerabilities and refinements to model safety protocols.
Neuron-Level Alignment represents a technique for enhancing model safety by directly modulating the activity of identified ‘Safety Neurons’. Rather than adjusting model weights globally, this approach focuses on specifically influencing the activation patterns of these neurons, aiming to increase their responsiveness to safe inputs and strengthen their role in rejecting harmful requests. This targeted intervention is intended to improve model robustness against adversarial attacks and unintended harmful outputs by reinforcing the internal mechanisms already associated with safe behavior, potentially leading to more predictable and reliable performance in safety-critical applications.
The Architecture of Resilience: Redundancy and Future Trajectories
The architecture of robust artificial intelligence increasingly relies on redundant safety mechanisms, a principle mirroring biological systems where critical functions aren’t dependent on single components. This approach distributes the responsibility for safe behavior across numerous neurons, creating a system less vulnerable to adversarial attacks designed to exploit individual vulnerabilities. Rather than pinpointing and correcting single ‘failure points’, redundancy ensures that even if some neurons are misled by malicious inputs, a sufficient number remain aligned with safe outputs. This distribution of control significantly lowers the Attack Success Rate (ASR) because attackers must simultaneously compromise a larger population of neurons to disrupt the system’s intended function, making successful exploitation substantially more difficult and contributing to a more resilient and trustworthy AI.
Direct Preference Optimization, or DPO, emerges as a potent technique for meticulously aligning individual neurons within large language models to reflect nuanced human preferences. Unlike traditional reinforcement learning methods that require complex reward modeling, DPO directly optimizes the model’s policy by comparing preferred and dispreferred responses. This streamlined approach allows for a more stable and efficient training process, enabling researchers to shape neuron-level behavior with greater precision. By leveraging human feedback, DPO fosters the development of models that not only generate coherent text but also consistently prioritize safety and adhere to desired ethical guidelines, ultimately enhancing the reliability and trustworthiness of artificial intelligence systems.
Evaluations across both Qwen2.5-3B and LLaMA3-8B models reveal a substantial decrease in the Attack Success Rate (ASR) as training data scale increases, demonstrating a clear correlation between data quantity and model robustness. This finding suggests that exposing these language models to a more diverse and extensive dataset effectively fortifies their defenses against adversarial attacks. Specifically, the methodology employed shows a marked improvement in resisting prompts designed to elicit unsafe or undesirable responses, indicating that increased data scale not only enhances overall performance but also plays a critical role in aligning model behavior with intended safety parameters. The observed reduction in ASR highlights the potential of scaling data as a practical strategy for building more reliable and secure language-based AI systems.
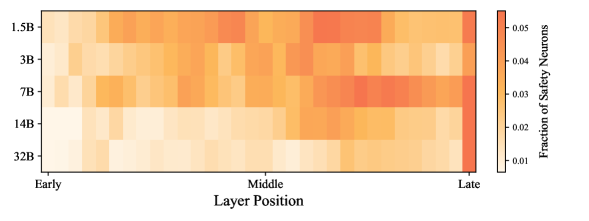
Analysis revealed a notable increase in layer-wise separability within the neural networks, suggesting that as information propagates through deeper layers, features related to safe and unsafe behaviors become increasingly distinguishable. This indicates the model isn’t simply memorizing safe responses, but rather developing an internal representation where safety-critical aspects are processed and isolated in higher-level abstractions. Consequently, these more differentiated features enhance the model’s ability to consistently produce safe outputs, even when confronted with subtle or complex adversarial inputs designed to exploit vulnerabilities in earlier layers. This hierarchical organization offers a promising pathway for improving the interpretability and reliability of large language models by pinpointing where and how safety constraints are enforced.
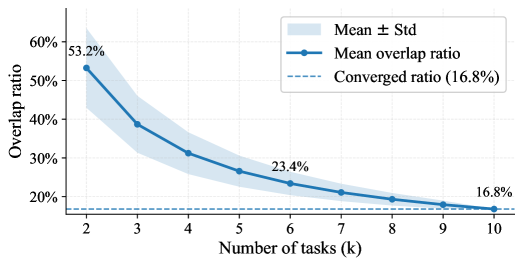
Model compression through neuron pruning offers a pathway to more efficient large language models, but demands careful implementation to preserve safety mechanisms. Reducing model size by eliminating neurons can inadvertently remove critical redundancies – the overlapping contributions of multiple neurons to safe behavior – thereby increasing vulnerability to adversarial attacks. Research indicates that maintaining a degree of redundancy is paramount; a robust system distributes safety-critical functions across numerous neurons, ensuring that the failure of any single neuron does not compromise overall performance. Consequently, while pruning can be effective, it requires a nuanced approach that prioritizes the preservation of these vital, overlapping safety features to avoid diminishing the model’s ability to consistently generate safe and reliable outputs.
The pursuit of robust safety alignment, as demonstrated in SafeNeuron, echoes a fundamental truth about complex systems. Each architecture lives a life, evolving and adapting, yet inevitably approaching a state of decay. This work, by strategically intervening at the neuron level and fostering redundancy, attempts not to halt this natural progression, but to guide it. Freezing critical neurons and fine-tuning the remainder isn’t about achieving perfect safety-an illusion in any dynamic system-but about building a more graceful decline. As Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” SafeNeuron embodies this principle, proactively shaping the LLM’s responses within defined, safety-conscious boundaries, acknowledging the inherent limitations and potential for unforeseen behavior within the system.
What Remains Unseen?
The pursuit of safety in large language models, as demonstrated by neuron-level interventions, addresses a symptom, not the decay. Freezing critical neurons and fostering redundancy buys time, yet stability remains an illusion cached by time. This approach, while valuable, implicitly concedes that perfect alignment is asymptotic; a model’s safety is a function of the adversarial pressures it has not yet encountered. The latency inherent in every request is, in essence, the tax paid for this temporary reprieve.
Future work will undoubtedly focus on scaling these interventions-identifying critical neurons in ever-larger models and refining the granularity of freezing. However, a more fundamental question lingers: can a system built on pattern completion truly be safe, or merely increasingly predictable? The focus may need to shift from identifying ‘critical’ neurons to understanding the emergent properties that give rise to unsafe behavior, accepting that complex systems will always exhibit unforeseen failures.
Moreover, the extension to vision-language models introduces new vectors of vulnerability. A model perceiving the world through a lens of learned associations is susceptible to adversarial examples in both modalities. The real challenge lies not in mitigating these attacks, but in acknowledging that every perception is, at its core, an interpretation-and all interpretations are inherently fallible.
Original article: https://arxiv.org/pdf/2602.12158.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- All Itzaland Animal Locations in Infinity Nikki
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Gold Rate Forecast
- How to Get to the Undercoast in Esoteric Ebb
- Cthulhu: The Cosmic Abyss Chapter 3 Ritual Puzzle Guide
- Woman fined $2k over viral googly eyes graffiti on $100k statue
- Smarter, Faster Networks: Optimizing Early-Exit Architectures for Edge AI
- Zerowake GATES : BL RPG Tier List (November 2025)
- CBR’s Official Spring 2026 Anime Series Power Ranking (Week 1)
2026-02-14 06:54