Author: Denis Avetisyan
New research reveals the challenges vision-language models face when interpreting complex financial documents, particularly those containing charts and tables.
A novel benchmark dataset, Multimodal Finance Eval, exposes error propagation in models tasked with understanding French financial data.
Despite advances in vision-language models, their reliability in specialized, non-English domains-particularly those demanding rigorous accuracy-remains largely unexplored. This work, ‘When Tables Go Crazy: Evaluating Multimodal Models on French Financial Documents’, introduces Multimodal Finance Eval, a new benchmark dataset designed to rigorously assess performance on complex French financial documents. Our findings reveal strong performance on text and table extraction, yet significant weaknesses in chart interpretation and a troubling tendency for errors to propagate during multi-turn conversational reasoning, driving accuracy down to chance levels. Can we develop more robust multimodal models capable of navigating the intricacies of financial analysis with the precision required in this high-stakes setting?
The Challenge of Financial Complexity
Vision-Language Models (VLMs) have rapidly emerged as a promising avenue for automating document understanding, yet their capabilities are notably challenged when applied to the intricacies of real-world financial materials. While adept at processing simpler document types, these models often falter when confronted with the density of information, specialized terminology, and nuanced context characteristic of financial reports, statements, and analyses. The inherent complexity arises from the need to not only recognize text and visual elements, but also to interpret relationships between them – a task demanding a level of reasoning that current VLMs struggle to consistently achieve. Consequently, despite advancements in artificial intelligence, fully automated extraction of meaningful insights from financial documents remains a significant hurdle, requiring ongoing research and development to bridge the gap between model capabilities and the demands of this complex domain.
French financial documentation poses a significant challenge to contemporary Vision-Language Models due to its inherent complexity. These documents are often extensive, routinely exceeding several pages, and are densely populated with specialized terminology and nuanced legal language unfamiliar to general-purpose models. Furthermore, information is rarely presented in a uniform manner; instead, critical data is fragmented across varied formats including lengthy prose, intricate tabular data, and visually complex charts. Successfully extracting meaning requires models to not only recognize these diverse elements, but also to correlate information between them – a task demanding a level of multimodal understanding that current VLMs frequently lack. The sheer volume of data, coupled with the need for precise interpretation of technical details, elevates French financial documents to a particularly rigorous benchmark for assessing the true capabilities of document understanding AI.
Truly effective financial reasoning transcends the mere extraction of data from documents; it necessitates a deep and robust understanding of the information presented and the capacity to integrate insights gleaned from diverse sources. Unlike simple information retrieval, which focuses on locating specific facts, successful financial analysis requires models to comprehend the relationships between different data points – such as connecting textual disclosures with tabular figures and graphical trends. This synthesis isn’t merely additive; it involves interpreting context, recognizing nuances in language, and drawing inferences to form a coherent picture of a financial situation. Consequently, models must move beyond identifying individual pieces of information and instead demonstrate an ability to reason about the overall meaning and implications embedded within complex financial documentation.
Evaluating Financial Understanding: The Multimodal Finance Eval Benchmark
The Multimodal Finance Eval benchmark utilizes a dataset comprised of French-language financial documents to rigorously evaluate the capabilities of Vision-Language Models (VLMs). This dataset is specifically designed to test performance on tasks crucial to financial analysis, primarily Information Extraction – the accurate identification and retrieval of key data points – and Table Comprehension, which assesses the model’s ability to understand and interpret data presented in tabular format. The use of French documents introduces a linguistic challenge, requiring VLMs to demonstrate cross-lingual understanding in addition to their multimodal processing skills. The benchmark provides a standardized method for quantifying VLM performance within the complex domain of financial document analysis.
The Multimodal Finance Eval Benchmark moves beyond simple information retrieval by demanding that Vision-Language Models (VLMs) demonstrate financial reasoning capabilities. Evaluation isn’t limited to identifying data points within documents; models must apply that information to understand financial contexts and derive conclusions. This requires VLMs to process nuanced financial terminology, interpret relationships between data presented in text, tables, and charts, and ultimately, answer questions that necessitate understanding of financial principles – a level of comprehension exceeding basic pattern recognition or keyword matching. The benchmark’s tasks are structured to specifically test this ability to synthesize information and apply it within a financial domain.
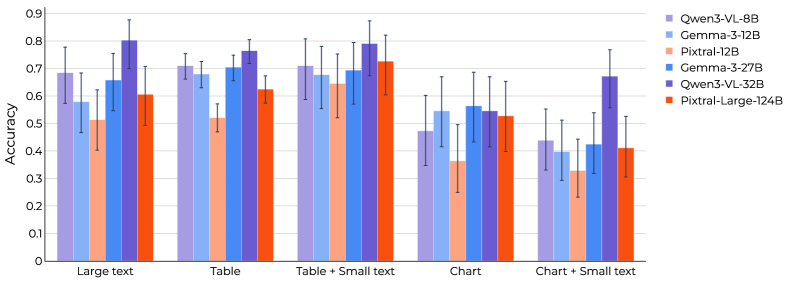
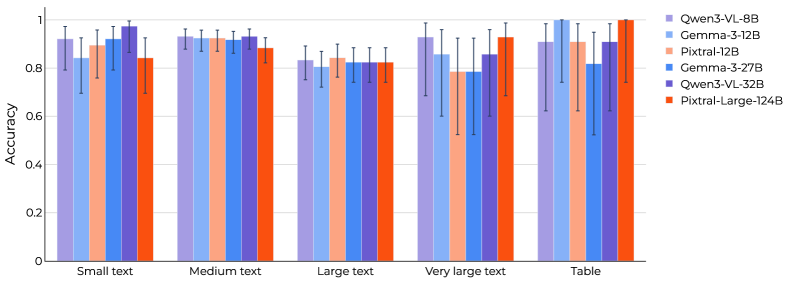
Evaluation of Vision-Language Models (VLMs) on the Multimodal Finance Eval benchmark indicates performance varies significantly by task. Table Comprehension achieved accuracy rates between 52% and 86%, demonstrating a reasonable capacity to extract data from tabular formats. Conversely, Chart Interpretation presented a considerable difficulty, with accuracy ranging from 34% to 62%. This substantial performance gap highlights the need for further development in VLM capabilities related to visual reasoning and the interpretation of graphical data within the financial domain.
The Fragility of Reasoning: Multi-Turn Dialogue Challenges
Evaluation of current Vision-Language Models (VLMs) reveals substantial performance deficiencies when applied to multi-turn dialogue scenarios requiring financial reasoning. Specifically, these models struggle to maintain response consistency across multiple conversational exchanges focused on financial topics. Observed inaccuracies aren’t isolated to single turns; rather, the models demonstrate a systematic inability to integrate information presented in earlier dialogue turns with subsequent queries, resulting in logically inconsistent or factually incorrect responses as the conversation progresses. This difficulty extends to both understanding numerical data and applying relevant financial principles within the conversational context.
Analysis of multi-turn dialogue performance reveals a pronounced error propagation effect in VLMs. Initial inaccuracies, even if minor, are not effectively corrected in subsequent conversational turns; instead, these errors accumulate and are compounded with each response. Specifically, inaccuracies present in early dialogue turns demonstrably decrease the accuracy of later responses, leading to a non-linear decline in overall conversational performance. This suggests a limitation in the model’s ability to maintain contextual coherence and prevent the amplification of mistakes as the conversation progresses.
Current Vision-Language Models (VLMs) demonstrate a critical vulnerability to error propagation in multi-turn dialogue scenarios. Evaluations reveal that initial inaccuracies, even minor ones, are not effectively corrected or mitigated in subsequent conversational turns, leading to a compounding effect on overall performance. This inability to maintain contextual consistency results in a significant decline in conversational accuracy, with observed rates collapsing to between 46% and 59% as dialogue progresses. The data indicates a fundamental limitation in these models’ capacity for robust contextual understanding and the prevention of compounding errors during extended interactions.
The Path Forward: Implications and Future Directions
Current visual language models (VLMs) struggle with tasks demanding sustained, multi-step reasoning, significantly hindering their usefulness in complex financial applications. Unlike scenarios requiring a single observation and response, areas like financial advising or fraud detection necessitate consistent interpretation and building upon previous inferences. A VLM might initially correctly identify a suspicious transaction, but fail to maintain that assessment across subsequent related data points, leading to flawed conclusions. This inability to track and reconcile information over multiple ‘turns’-essentially, a conversational or sequential analysis-introduces unacceptable risk in high-stakes financial contexts, as even minor inconsistencies can have substantial consequences. Consequently, while VLMs show promise, their practical deployment in these critical areas remains limited until robust mechanisms for maintaining reasoning consistency are developed.
Advancing the capabilities of vision-language models necessitates a concentrated effort on bolstering contextual understanding and mitigating the cascading effect of errors within complex reasoning processes. Current models often struggle with maintaining accuracy over multiple conversational turns or analytical steps, hindering their application in fields demanding consistent, reliable judgment. Researchers are exploring innovative strategies, including the implementation of self-correction mechanisms – allowing the model to identify and rectify its own mistakes – and uncertainty estimation, which would enable the model to flag potentially unreliable outputs. These approaches aim to build models that not only provide answers, but also convey a degree of confidence in those answers, ultimately leading to more trustworthy and robust performance in real-world applications requiring sustained, accurate reasoning.
Advancing the field of visual language models, particularly within the financial domain, hinges on the continued development of robust evaluation benchmarks. Current assessments, like Multimodal Finance Eval, provide a valuable foundation, yet progress demands increasingly complex scenarios and a broader representation of real-world financial data. While Qwen3-VL-32B presently leads performance with an overall accuracy of 75.6%, sustained improvement requires benchmarks capable of discerning nuanced reasoning and identifying vulnerabilities in model performance. Refinement efforts should prioritize the inclusion of ambiguous cases, long-form financial documents, and diverse data distributions to truly gauge a model’s capacity for reliable financial analysis and decision-making, ultimately fostering more trustworthy and capable visual language models.
The pursuit of robust multimodal understanding, as demonstrated by Multimodal Finance Eval, necessitates a rigorous distillation of information. Andrey Kolmogorov once stated, “The shortest proof is usually the most difficult to find.” This resonates deeply with the challenges presented in evaluating vision-language models on complex financial documents. The dataset’s focus on error propagation highlights how seemingly minor inaccuracies in chart interpretation can cascade, obscuring the core financial insights. The work embodies a commitment to identifying and eliminating unnecessary complexity-a quest for the ‘shortest proof’ of genuine understanding in a noisy data landscape. It’s a study in lossless compression, extracting meaningful signal from intricate visual and textual data.
The Road Ahead
The introduction of Multimodal Finance Eval clarifies a predictable truth: competence in isolated tasks does not guarantee robust understanding. The dataset’s revelation of error propagation within vision-language models is not a failing of the models themselves, but a consequence of attempting to graft symbolic reasoning onto fundamentally structural systems. Emotion, in this context, is merely a side effect of structural instability – a high error rate presented as a ‘problem’ rather than an inevitable outcome. Future work must confront the limitations of this architectural approach.
Specifically, efforts to improve chart interpretation should shift from feature engineering – attempting to ‘teach’ the model what to look for – towards more fundamental investigations into how visual data can be meaningfully integrated with linguistic representations. The current emphasis on conversational AI, while superficially appealing, risks compounding existing errors. Clarity, after all, is compassion for cognition; a model that confidently propagates falsehoods offers neither.
The path forward is not necessarily more data, nor more parameters. Perfection is reached not when there is nothing more to add, but when there is nothing left to take away. The field would benefit from a period of subtraction – a ruthless pruning of assumptions and a renewed focus on establishing a minimal, verifiable foundation for multimodal financial understanding.
Original article: https://arxiv.org/pdf/2602.10384.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- X-Men ’97 Finally Gave Gambit the Hero Moment He Deserved
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- 46 Years Later, The Mandalorian & Grogu Answers A Major Empire Strikes Back Question
- 10 Worst End-Game Couples In Sitcom History
- HoI4 fans harsh reactions to the announcement of another DLC pack
- Gold Rate Forecast
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Emily Henry Says to ‘Trust the Vision’ For Beach Read Adaptation
- Dragon Quest II HD-2D Remake: Where to get the Magic Key
2026-02-13 00:31