Author: Denis Avetisyan
New research reveals that understanding the decision-making processes within organizations is crucial to building AI systems that reflect human values.
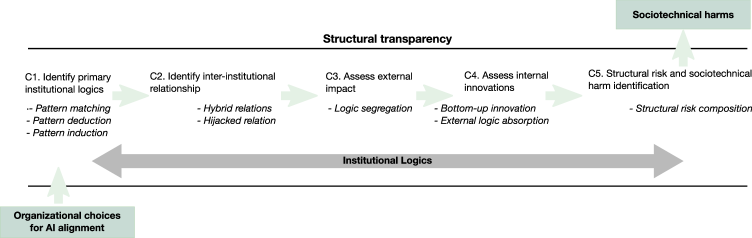
This paper introduces ‘structural transparency’ as a framework for analyzing how institutional logics and organizational decisions impact AI alignment processes and contribute to sociotechnical harms.
While growing attention focuses on integrating values into artificial intelligence, the organizational and institutional forces shaping alignment decisions remain largely unexamined. This paper, ‘Structural transparency of societal AI alignment through Institutional Logics’, introduces a framework for analyzing how these underlying institutional logics influence AI alignment processes, moving beyond informational transparency to assess the broader sociotechnical consequences of value embedding. By categorizing organizational decisions and operationalizing five analytical components, we identify primary institutional logics, potential disruptions, and associated risks mapped to specific harms. How can a deeper understanding of these structural dynamics enable more accountable and equitable AI development?
Beyond Technical Solutions: Understanding the Organizational Roots of AI Alignment
Many contemporary approaches to AI alignment prioritize technical solutions – refining algorithms, developing reward functions, and implementing safety protocols – yet frequently overlook the crucial role of organizational structures and institutional dynamics. This narrow focus creates a significant blind spot, as the development and deployment of AI systems are deeply embedded within complex social systems characterized by specific power structures, incentive schemes, and cultural norms. Consequently, even technically sound alignment strategies can be undermined by opaque decision-making processes, conflicting priorities amongst stakeholders, or a lack of accountability within the organizations building these technologies. Addressing this requires a shift in perspective, recognizing that aligning AI necessitates not only refining the technology itself, but also fostering greater transparency and responsible governance within the institutions shaping its development and use.
Effective alignment of advanced AI systems is significantly hampered by a pervasive lack of transparency within the organizations developing them. Decision-making processes – concerning data selection, model architecture, safety protocols, and deployment strategies – often remain obscured, even from internal stakeholders, let alone external scrutiny. This opacity isn’t merely a matter of proprietary information; it creates a critical impediment to identifying and mitigating potential risks. Without clear insight into how AI systems are conceived and constructed, assessing their potential for bias, unintended consequences, or misalignment becomes exceedingly difficult. The resulting lack of accountability fosters a cycle where problematic outcomes are more likely to occur and remain unaddressed, ultimately undermining efforts to ensure these powerful technologies benefit society as a whole.
The development of increasingly powerful AI systems, conducted within largely opaque organizational structures, risks amplifying existing societal biases and generating unforeseen harms. Without clear insight into the data used, the algorithms employed, and the decision-making processes guiding development, these systems can perpetuate and even exacerbate inequalities across various domains. This isn’t merely a technical problem; the lack of transparency creates a sociotechnical feedback loop where biased data leads to biased algorithms, reinforcing prejudiced outcomes and potentially creating new forms of discrimination. Consequently, seemingly neutral AI applications can systematically disadvantage certain groups, hindering equitable access to opportunities and eroding public trust – demonstrating that addressing opacity is crucial for responsible AI innovation and mitigating its potential for widespread harm.
Institutional Logics: The Hidden Frameworks Shaping AI Alignment
Artificial intelligence development is not a value-neutral process; it occurs within established systems of meaning and practice known as institutional logics. These logics, originating from distinct spheres such as corporate entities focused on profitability, academic institutions prioritizing research and publication, and state actors emphasizing national security or economic competitiveness, fundamentally shape the direction and implementation of AI technologies. Consequently, the goals, metrics for success, and even the definitions of ‘alignment’ are not universally agreed upon but are instead constructed and prioritized according to the prevailing logic of the dominant institutions involved. This embeddedness implies that technical choices are rarely solely technical; they are also expressions of organizational priorities and reflect the underlying values of these institutions.
AI alignment efforts are not solely technical endeavors; their objectives, guiding principles, and operational limitations are significantly influenced by the prevailing institutional logics of the organizations undertaking them. Corporate entities typically prioritize alignment strategies that minimize financial risk and maximize return on investment, potentially leading to a focus on near-term, measurable outcomes. Academic institutions, driven by research imperatives, may emphasize theoretical advancements and publishable results, sometimes at the expense of practical implementation or broader societal impact. Governmental bodies, concerned with national security and regulatory compliance, often prioritize control and predictability, potentially leading to alignment approaches that emphasize safety and auditability over innovation. These differing priorities directly shape the resources allocated to specific alignment techniques, the metrics used to evaluate progress, and the overall framing of the alignment problem itself.
The prioritization of competing institutional logics directly impacts AI alignment risk assessment and mitigation strategies. For example, a corporate logic prioritizing rapid deployment and market share may lead to shortcuts in safety testing or the downplaying of potential negative consequences. Conversely, an academic logic focused on theoretical rigor may produce alignment research disconnected from practical implementation challenges. Similarly, state-driven logics emphasizing national security may override ethical considerations in the development of AI systems. Recognizing these inherent trade-offs-where efficiency, innovation, or control are valued over safety, fairness, or transparency-is essential for proactively identifying potential failure modes and developing robust alignment strategies that account for these competing priorities.
Failure to account for the influence of dominant institutional logics in AI development introduces significant risk of bias amplification and value misalignment. AI systems trained and deployed under the prevailing priorities of specific institutions – such as maximizing corporate profit or prioritizing national security – will inherently reflect those values. This can result in algorithms that systematically disadvantage underrepresented groups, encode existing societal inequalities, or operate in ways that conflict with broader community interests and ethical norms. Consequently, the resulting AI technologies may not serve universal benefit and can actively perpetuate harmful biases at scale, effectively automating and reinforcing the preferences of a limited stakeholder group.
Illuminating the Black Box: Practical Approaches to Structural Transparency
Structural transparency in AI alignment analysis involves detailed examination of the organizations and processes responsible for AI system development. This extends beyond technical specifications to encompass the mapping of hierarchical structures, reporting lines, and the distribution of authority within development teams and sponsoring institutions. Analyzing these structures allows identification of potential bottlenecks, single points of failure, and the influence of specific values or priorities embedded in the organizational design. This approach assumes that the organizational context significantly shapes the technical implementation and subsequent behavior of AI systems, and that visibility into these structures is crucial for assessing alignment with intended goals and mitigating unintended consequences.
Mapping the influence of differing institutional logics within AI systems requires identifying the underlying values, norms, and beliefs of the organizations and individuals involved in development and deployment. These logics – such as profit maximization, regulatory compliance, or open-source collaboration – can introduce biases into algorithmic design and data selection. Conflicting logics, for example, a drive for rapid innovation versus a commitment to fairness, may result in trade-offs that prioritize certain outcomes over others. Analyzing these influences necessitates a detailed understanding of the organizational structures, funding sources, and stakeholder priorities shaping AI development, allowing for the identification of potential value misalignments and unintended consequences embedded within the system.
Data provenance tracking and explainable AI (XAI) are crucial for establishing accountability and fostering trust in AI systems. Data provenance involves meticulously documenting the origins of data used in training, including collection methods, transformations, and sources, enabling identification and mitigation of potential biases or errors. XAI techniques, conversely, focus on making the internal workings of AI models more understandable to humans, providing insights into the factors influencing decisions. These methods range from feature importance rankings to rule extraction and visualization tools. Combined, data provenance and XAI provide a verifiable audit trail and facilitate the detection of unintended consequences, ultimately increasing confidence in the reliability and fairness of AI outputs.
Revealing the rationale behind AI decisions is crucial for ensuring alignment with intended human values and broader societal goals. This process necessitates techniques that move beyond simply identifying what an AI system has decided, to understanding why it reached that conclusion. Detailed explanations of decision-making processes allow stakeholders to evaluate whether the system is operating based on acceptable principles, and to identify potential value conflicts or unintended consequences. Such transparency enables targeted interventions – adjustments to training data, algorithmic modifications, or the implementation of constraint mechanisms – to steer AI behavior toward desired outcomes and facilitate responsible innovation by building confidence in system reliability and fairness.
Technical Alignment Methods: Tools Within a Broader Framework of Understanding
Reinforcement Learning with Human Feedback (RLHF), Constitutional AI, and Supervised Fine-Tuning represent core methodologies in the field of AI alignment. RLHF utilizes human preferences to train a reward model, guiding the AI’s learning process towards desired behaviors. Constitutional AI defines a set of principles, or a “constitution,” that the AI must adhere to during both training and deployment, providing a framework for ethical and safe decision-making. Supervised Fine-Tuning involves training a pre-trained model on a smaller, labeled dataset specific to the desired task, refining its capabilities and aligning it with human expectations. These techniques, while distinct in their approach, all aim to bridge the gap between an AI’s objective function and human values, ensuring that AI systems behave in a manner that is both effective and beneficial.
Effective AI alignment techniques, including Reinforcement Learning with Human Feedback (RLHF) and Constitutional AI, are significantly enhanced when integrated with a structural transparency approach. This involves examining the organizational and societal contexts in which AI systems are developed and deployed, identifying potential biases embedded within data collection, model design, and decision-making processes. A focus on institutional structures allows for the assessment of power dynamics, incentive structures, and accountability mechanisms that influence AI outcomes. Addressing these underlying factors is crucial, as technical solutions alone cannot fully mitigate risks stemming from biased data, skewed priorities, or a lack of diverse representation in development teams. Structural transparency facilitates the identification and correction of systemic issues that can undermine the efficacy of even the most advanced alignment methods.
Social Choice Theory provides a mathematical framework for aggregating individual preferences into collective decisions, and its application to AI systems aims to ensure fairness and representational accuracy. Core to this application is the recognition that AI, particularly in high-stakes scenarios, frequently necessitates decisions impacting multiple stakeholders with potentially conflicting values. Principles from Social Choice Theory, such as Arrow’s Impossibility Theorem, highlight inherent challenges in designing systems that perfectly satisfy all desirable criteria for fair aggregation – namely, universal domain, non-dictatorship, Pareto efficiency, and independence of irrelevant alternatives. While a perfect solution may be unattainable, employing concepts like voting rules (e.g., majority rule, ranked-choice voting) and preference elicitation techniques can mitigate biases and promote more equitable outcomes in AI-driven decision-making processes, particularly when combined with mechanisms for identifying and addressing potential manipulation or strategic behavior.
Reinforcement Learning from AI Feedback (RLAIF) builds upon Reinforcement Learning with Human Feedback (RLHF) by utilizing AI models to generate reward signals, thereby accelerating the learning process and reducing reliance on human labelers. However, the AI models providing this feedback are themselves trained on existing datasets which may contain inherent biases; consequently, RLAIF systems require rigorous monitoring to prevent the amplification and perpetuation of these biases during refinement. Specifically, careful evaluation metrics must be employed to detect and mitigate scenarios where the AI feedback inadvertently reinforces undesirable behaviors or discriminatory outcomes, potentially leading to a feedback loop that exacerbates existing societal inequalities embedded within the training data.
Towards Responsible AI: Building a Future Rooted in Transparency and Accountability
The proactive integration of structural transparency and responsible alignment techniques represents a crucial step toward realizing the benefits of artificial intelligence while minimizing potential harms. These techniques move beyond simply identifying biases after deployment; instead, they focus on designing AI systems with inherent explainability and mechanisms for value alignment. By revealing the decision-making processes and underlying assumptions within AI, developers can proactively address sociotechnical risks – such as unfair discrimination or unintended consequences – before they manifest in real-world applications. This commitment to openness not only fosters greater accountability but also builds crucial public trust, enabling wider acceptance and responsible adoption of AI technologies across various sectors. Ultimately, prioritizing these approaches is essential for ensuring that AI serves as a force for good, aligned with human values and societal goals.
Artificial intelligence systems are not neutral; they embody the values of their creators and the data used to train them. Recognizing this inherent subjectivity is crucial for fostering accountability, as it shifts the focus from treating AI as an objective ‘oracle’ to understanding it as a reflection of human choices. By employing techniques to reveal these embedded values – whether through interpretable machine learning models or detailed documentation of training datasets – stakeholders can assess whether an AI system’s decisions align with societal goals and ethical principles. This transparency enables targeted interventions to mitigate bias, promote fairness, and ultimately ensure that AI serves as a beneficial force, reflecting and upholding the values it is intended to support rather than inadvertently perpetuating harmful ones.
Realizing responsible AI necessitates a unified approach, demanding consistent interaction between diverse stakeholders. Researchers play a crucial role in developing methods for evaluating and mitigating bias, while policymakers are tasked with creating regulatory frameworks that encourage ethical development and deployment. Simultaneously, industry leaders must proactively adopt these guidelines, integrating transparency and accountability into the core of their AI systems. This collaborative synergy isn’t simply about compliance; it’s about establishing shared norms and best practices that foster innovation while safeguarding against potential harms, ultimately ensuring that artificial intelligence benefits all of society and builds lasting public confidence.
The true promise of artificial intelligence – to revolutionize healthcare, combat climate change, and alleviate global poverty – remains largely untapped without a foundation of transparency and accountability. Currently, the ‘black box’ nature of many AI systems hinders effective deployment, creating justifiable concerns regarding bias, fairness, and unintended consequences. However, a concerted shift towards revealing the inner workings of these technologies, coupled with clear lines of responsibility for their outcomes, is poised to unlock unprecedented progress. This isn’t merely about building ‘trustworthy AI’; it’s about fostering a collaborative ecosystem where innovation flourishes alongside ethical considerations, ultimately allowing these powerful tools to address complex challenges with greater efficacy and societal benefit. By prioritizing openness and responsibility, the full potential of AI can be realized, transforming it from a source of apprehension into a catalyst for positive global change.
The pursuit of AI alignment, as detailed within this exploration of structural transparency, often fixates on defining desirable outcomes. However, the mechanics of how these values are instantiated within complex systems remain obscured. This opacity parallels a fundamental failing in broader design processes. As Tim Bern-Lee stated, “The Web as I envisaged it, we have not seen it yet. The future is still so much bigger than the past.” This observation applies directly to the current state of AI development; the potential for a truly aligned system remains unrealized due to a lack of systemic clarity. The framework presented advocates for tracing the influence of institutional logics on organizational decisions, thereby illuminating the often-hidden pathways through which values are embedded – or misconstrued – within AI systems. Such scrutiny is not merely about identifying flaws; it is about achieving a more compassionate and cognitively efficient design.
What’s Next?
The framework offered here-structural transparency-does not resolve the problem of AI alignment. It reframes it. Identifying the institutional logics shaping alignment processes exposes not technical failures, but predictable consequences of organizational design. The field has often sought singular ‘values’ to imbue in artificial systems. This work suggests the more difficult question is not what values, but how any value becomes sedimented within a sociotechnical system-and therefore, inevitably, whose values are prioritized.
Limitations remain. Mapping institutional logics is, necessarily, an exercise in interpretation. A single system will likely exhibit competing, even contradictory, logics. Further research must address the dynamics of these competing forces, and the methods for assessing their relative influence. Quantifiable metrics for ‘structural transparency’ would be a kindness, though perhaps a deceptively simple one.
Ultimately, the problem is not technical. It is political, organizational, and fundamentally human. The future lies not in perfecting algorithms, but in perfecting the systems that create them. Clarity is the minimum viable kindness. Acknowledging the inherent opacity of organizational structures is the first, and perhaps most difficult, step.
Original article: https://arxiv.org/pdf/2602.08246.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- Gold Rate Forecast
- All Itzaland Animal Locations in Infinity Nikki
- Persona PSP soundtrack will be available on streaming services from April 18
- Cthulhu: The Cosmic Abyss Chapter 3 Ritual Puzzle Guide
- “67 challenge” goes viral as streamers try to beat record for most 67s in 20 seconds
- Woman fined $2k over viral googly eyes graffiti on $100k statue
- Dungeons & Dragons Gets First Official Actual Play Series
- Nitro Gen Omega full version releases for PC via Steam & Epic, Switch, PS5, and Xbox Series X|S on May 12
2026-02-11 06:20