Author: Denis Avetisyan
New research tackles the problem of ‘hallucinations’ in large language models to create more trustworthy AI systems for managing and responding to security incidents.
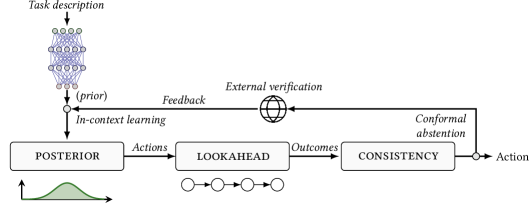
A novel framework leveraging consistency verification and iterative refinement enhances the reliability of large language models in security planning and incident response.
Despite the promise of large language models (LLMs) for automating complex tasks, their propensity for generating factually inconsistent outputs-or “hallucinations”-remains a critical barrier to adoption in high-stakes domains like cybersecurity. This paper, ‘Hallucination-Resistant Security Planning with a Large Language Model’, introduces a novel framework that mitigates this risk by integrating iterative consistency verification and refinement within an incident response planning workflow. Through a principled approach combining lookahead prediction and in-context learning, the framework demonstrably controls hallucination risk and bounds the regret associated with LLM-driven decision-making. Can this approach unlock the full potential of LLMs for reliable and automated security management, and what further refinements are needed to address evolving threat landscapes?
The Challenge of Reliable Automation
For decades, cybersecurity teams have depended on pre-defined playbooks and the meticulous work of human analysts to address security incidents. This traditional approach, while foundational, struggles to keep pace with the speed and sophistication of modern threats. Static playbooks quickly become outdated as attackers continually evolve their tactics, and manual analysis is inherently slow and prone to human error, especially when facing a high volume of alerts. This creates a critical vulnerability: the time it takes to detect, understand, and respond to an incident often exceeds the attacker’s operational window. Consequently, organizations find themselves consistently playing catch-up, reacting to breaches rather than proactively preventing them, and exposing themselves to significant financial and reputational damage.
The potential of Large Language Models (LLMs) to revolutionize security automation is significant, yet hampered by a fundamental challenge: the risk of ‘hallucinations’. These models, while adept at generating human-like text, can produce outputs that appear logical and coherent, but are factually incorrect or irrelevant to the security context. This isn’t simply a matter of occasional errors; LLMs can confidently fabricate information, potentially leading security teams to pursue false positives, misdiagnose threats, or even implement incorrect remediation steps. The plausibility of these fabricated responses is particularly concerning, as it can bypass traditional validation mechanisms and require specialized techniques to detect and mitigate the risk of acting on unreliable information. Consequently, simply deploying an LLM isn’t enough; robust methods for ensuring the trustworthiness and accuracy of its outputs are essential for safe and effective security automation.
Achieving effective security automation with Large Language Models necessitates robust mechanisms for verifying the validity of their recommendations. While LLMs demonstrate an impressive capacity for analyzing complex security data and suggesting responses, their propensity for ‘hallucinations’ – generating confident but inaccurate outputs – poses a significant risk. Current research focuses on techniques like Retrieval-Augmented Generation (RAG), which grounds LLM responses in verified knowledge bases, and the implementation of ‘red teaming’ exercises where LLM-generated actions are systematically challenged. Furthermore, the development of confidence scoring systems and explainability tools allows security teams to assess the reliability of LLM proposals and understand the reasoning behind them, ensuring human oversight remains a critical component of the automated response process. Ultimately, trustworthy automation isn’t about replacing human analysts, but augmenting their capabilities with AI that can be demonstrably relied upon.

A Framework for Trustworthy Security Planning
The LLM-Based Security Planning framework employs Large Language Models to dynamically generate response actions to security incidents. Traditional security systems rely on pre-defined rules which struggle to address novel or complex threats. This framework overcomes these limitations by leveraging LLMs to analyze incident data and propose tailored actions, enabling a more adaptable and comprehensive security posture. The system moves beyond simple pattern matching to incorporate contextual understanding and reasoning, allowing it to address incidents that would bypass static rule-based defenses. This approach aims to reduce both false positives and missed detections by applying a more nuanced evaluation of security events.
Lookahead Optimization functions by simulating the execution of proposed security actions within the LLM-Based Security Planning framework. This predictive capability assesses the potential consequences of each candidate action before implementation, identifying scenarios that could lead to unintended negative outcomes or exacerbate the initial security incident. The process involves modeling the system’s state following the action and evaluating the resulting configuration against predefined security policies and known vulnerabilities. By proactively identifying potential issues, Lookahead Optimization enables the selection of more robust and reliable security responses, mitigating risks associated with unforeseen consequences and improving the overall efficacy of the security planning process.
The Consistency Check component within the LLM-Based Security Planning framework functions as a safeguard against illogical or contradictory actions proposed by the LLM. This process verifies that each recommended action aligns with established security protocols, system configurations, and previously identified incident details. By evaluating the internal coherence of proposed steps, Consistency Check aims to mitigate the risk of ‘hallucinations’ – instances where the LLM generates plausible but factually incorrect or nonsensical responses – and ensures the proposed security interventions are logically sound and executable within the defined operational environment. This verification step is crucial for preventing actions that could inadvertently compromise system integrity or escalate the severity of a security incident.
Refining Actions Through Continuous Learning
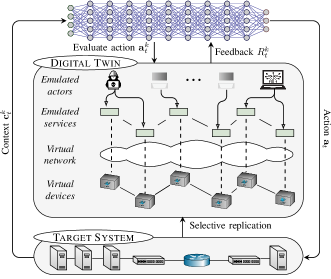
In-Context Learning (ICL) within the framework utilizes a ‘Digital Twin’ – a virtual representation of the physical system – to facilitate action refinement. This involves executing actions within the simulated environment and receiving immediate feedback on their outcomes without impacting the real-world system. The framework then analyzes this feedback to adjust its action selection policies. The Digital Twin provides a safe and cost-effective means of experimentation, allowing the ICL process to iterate rapidly and improve performance by identifying and correcting suboptimal actions based on the simulated consequences. This closed-loop system of action, simulation, and feedback is central to the framework’s adaptive capabilities.
In-Context Learning (ICL) utilizes Bayesian Learning to refine the framework’s environmental model through iterative updates based on observed data. This approach employs Bayes’ Theorem to calculate the probability of different environmental states given new information from the Digital Twin, allowing the system to move beyond simple memorization and generalize to unseen scenarios. Specifically, a prior probability distribution, representing initial beliefs about the environment, is updated with a likelihood function – quantifying the probability of observing specific data given a particular environmental state – resulting in a posterior probability distribution. This posterior then serves as the new prior in subsequent iterations, enabling continuous refinement of predictive capabilities and improved action selection over time. The process inherently manages uncertainty by assigning probabilities to different possibilities, rather than relying on deterministic assumptions.
Regret minimization is a core principle employed to refine action selection within the framework. This principle centers on consistently choosing actions that minimize the cumulative difference between the reward received and the maximum possible reward that could have been achieved with perfect foresight. The framework doesn’t simply maximize immediate rewards; it focuses on minimizing the potential loss from choosing suboptimal actions over time. This is achieved through algorithms that explore alternative actions, balancing exploration and exploitation to improve long-term performance and adapt to changing environmental conditions. By continually reducing this ‘regret’, the system converges towards an optimal policy, enhancing its predictive capabilities and overall efficiency in selecting effective actions.
Building a Proactive and Adaptive Security Posture
The framework’s proactive security capabilities are significantly enhanced through integration with established threat intelligence resources, notably the MITRE ATT&CK knowledge base. This connection allows the system to move beyond simple alert generation and instead contextualize security incidents by mapping observed behaviors to specific adversary tactics, techniques, and procedures (TTPs). By recognizing these patterns, the framework can accurately prioritize responses, focusing on actions that address the most critical threats and effectively disrupt ongoing attacks. This contextual awareness not only improves the speed and accuracy of incident response but also enables security teams to anticipate potential future attacks based on known adversary profiles and proactively strengthen defenses against them.
The framework’s adaptability hinges on a crucial component: the ‘Consistency Threshold’. This parameter doesn’t dictate a rigid response, but instead allows security teams to fine-tune the system’s approach to incident response. A lower threshold encourages greater exploration – the framework will proactively investigate a wider range of potential solutions, even if those solutions have lower initial confidence scores. Conversely, a higher threshold prioritizes exploitation, focusing on actions with established reliability and minimizing the risk of implementing untested strategies. This tunable balance is vital, as organizations with a high risk tolerance might favor exploration to identify novel threats, while those prioritizing stability will lean towards exploitation to ensure consistent and predictable outcomes. Ultimately, the ‘Consistency Threshold’ empowers security teams to mold the framework’s behavior, aligning it precisely with their specific risk appetite and operational requirements.
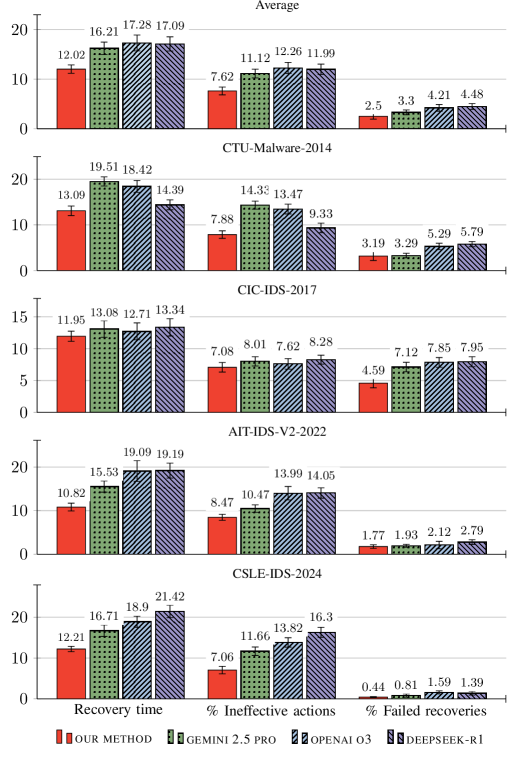
The security framework leverages the Deepseek-r1 large language model to markedly enhance the dependability of automated actions and substantially curtail instances of hallucination – inaccurate or nonsensical responses – by up to 3030% when contrasted with currently available frontier LLMs. This improvement in reliability directly translates to a significant acceleration in incident recovery, with testing demonstrating a 3030% reduction in the time required to effectively remediate security threats. By minimizing false positives and ensuring accurate action selection, the framework empowers security teams to respond more swiftly and decisively, bolstering overall security posture and minimizing potential damage from cyberattacks.
The pursuit of reliable security planning, as detailed in the framework, echoes a fundamental tenet of elegant system design. The paper’s emphasis on mitigating LLM ‘hallucinations’ through consistency checks and iterative refinement demonstrates a commitment to paring away unnecessary complexity. As Donald Davies observed, “Simplicity is the key to reliability.” This aligns directly with the core idea of the paper, which prioritizes a focused approach to incident response. By actively seeking to eliminate inconsistencies and reduce the potential for fabricated information, the framework embodies a principle of achieving clarity through relentless reduction-a process where the strength of the system resides not in what is added, but in what is removed.
The Road Ahead
The pursuit of reliable automation in security, as demonstrated by this work, invariably encounters the limits of probabilistic reasoning. Mitigating ‘hallucinations’ in Large Language Models is not a solved problem, but a perpetual refinement. Consistency checks and iterative refinement represent a necessary, though insufficient, corrective. The framework presented offers a reduction in risk, not its elimination. Future work must grapple with the inherent ambiguity of threat landscapes and the evolving tactics of malicious actors – a moving target for any predictive system.
A particularly thorny problem lies in scaling these techniques. The computational cost of exhaustive verification increases with model size and complexity. The Bayesian Regret minimization offers a pragmatic compromise, but begs the question: how much error is acceptable when the consequences involve genuine security breaches? The field should turn its attention to developing more efficient validation methods, perhaps by leveraging adversarial training to proactively expose and correct model weaknesses.
Ultimately, the true measure of success will not be the sophistication of the algorithms, but the humility of their application. A system that confidently asserts incorrect conclusions, even with reduced frequency, remains a liability. The goal is not to replace human judgment, but to augment it – providing well-reasoned suggestions, clearly delineating the limits of its certainty, and accepting that, in matters of security, a degree of skepticism is not a flaw, but a virtue.
Original article: https://arxiv.org/pdf/2602.05279.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- Chainsaw Man Volume 24’s Cover Art Reveals a Brand-New Denji
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Hideo Kojima says Metal Gear Solid 2 became the future he hoped would not happen
- Euphoria Season 3’s New R-Rated Sydney Sweeney Scene Proves The Show Is Trolling Us
- Dragon Quest II HD-2D Remake: Where to get the Magic Key
- Gold Rate Forecast
- HSR Banner Schedule (Honkai Star Rail)
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- How to Get to the Undercoast in Esoteric Ebb
2026-02-06 18:34