Author: Denis Avetisyan
A new approach to artificial intelligence mimics the way animals learn to avoid harm, creating more robust and adaptable systems.
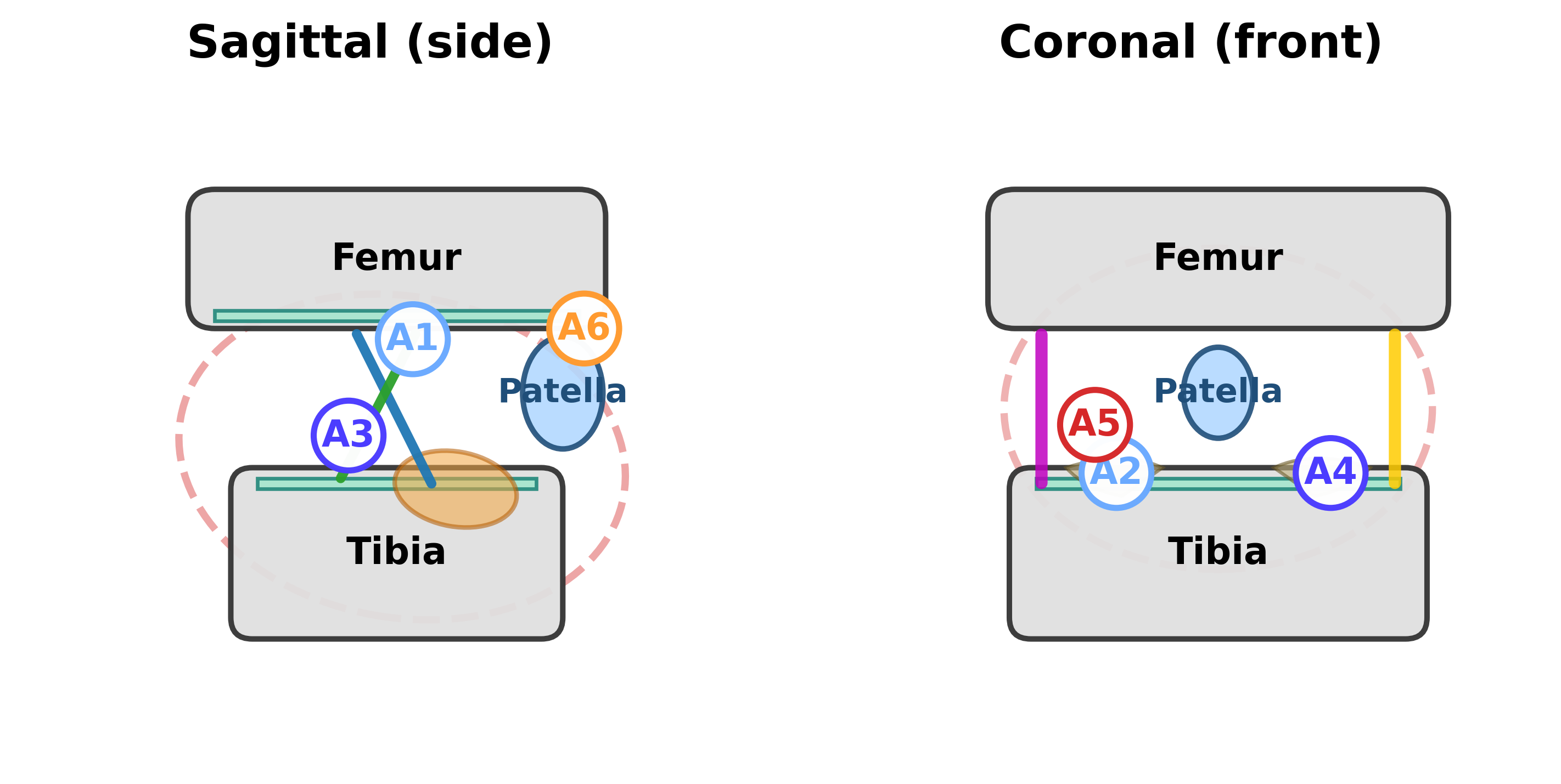
This review details ‘Afferent AI’, a bi-level learning architecture utilizing evolutionary optimization of computational afferents for damage avoidance in simulated environments.
Achieving robust, long-lived intelligence in complex environments remains a fundamental challenge for artificial agents. This is addressed in ‘Evolving Afferent Architectures: Biologically-inspired Models for Damage-Avoidance Learning’, which introduces a novel framework – Afferent AI – that learns to anticipate and avoid damage through the co-evolution of sensory architectures and damage-avoidance policies. By integrating reinforcement learning with an outer loop of evolutionary optimization focused on ‘Computational Afferents’, the approach demonstrates significant gains in efficiency and age-robustness within biomechanical digital twins. Could this biologically-inspired bi-level learning paradigm unlock more adaptable and resilient AI systems capable of thriving across decades of simulated life-course challenges?
The Inevitable Drift: Addressing Predictability in Language Models
Despite their remarkable ability to generate human-quality text, Large Language Models frequently exhibit a tendency towards predictable and repetitive outputs, ultimately limiting their potential for truly creative endeavors. This isn’t a matter of lacking information, but rather a consequence of how these models operate – prioritizing the most probable continuation of a given text sequence. While effective for tasks demanding consistency, this emphasis on probability can stifle novelty and lead to formulaic writing, where outputs, though grammatically correct and contextually relevant, lack the surprising twists, unique phrasing, and imaginative leaps that characterize genuinely creative content. The result is often text that feels technically proficient, yet strangely homogenous, hindering the model’s application in fields like artistic writing, brainstorming, and open-ended exploration.
Large language models, despite their capacity for fluent text generation, often exhibit a fundamental limitation: determinism. This means that, presented with identical prompts, these models consistently produce strikingly similar outputs, effectively narrowing the range of potential creative expression. While seemingly a technical detail, this predictability arises from the core mechanics of how LLMs function – specifically, the calculation of token probabilities and the constraints imposed by fixed model parameters. Consequently, the models tend to converge on the most probable, rather than the most diverse, responses, hindering their ability to explore genuinely novel ideas or generate truly surprising content. This inherent tendency towards repetition presents a significant challenge for applications requiring originality, adaptability, and the generation of varied perspectives.
The perceived lack of originality in large language models isn’t simply a matter of insufficient training data; it’s deeply rooted in how these systems function. At their core, LLMs operate by predicting the probability of the next token – a word or sub-word unit – given the preceding sequence. While sophisticated, this process inherently favors statistically likely continuations, effectively narrowing the range of possible outputs. The model’s parameters, learned during training, encode these probabilities, creating a landscape where certain responses are consistently favored over others. Consequently, even with slight variations in prompting, the model often converges on similar, predictable phrases and structures, limiting the exploration of truly novel or unexpected linguistic possibilities. This deterministic tendency, stemming from the interplay of token probabilities and fixed parameters, presents a significant hurdle for achieving genuine creative output from these powerful systems.
Controlled Deviation: Tools for Introducing Calculated Randomness
Large Language Models (LLMs) generate text by predicting the probability of the next token in a sequence; however, these probability distributions must be translated into actual text outputs via decoding strategies. These strategies address the inherent ambiguity in the probabilistic predictions, determining which token is ultimately selected at each step of text generation. Without a decoding strategy, simply selecting the highest probability token at each step would result in deterministic and repetitive text. Effective decoding strategies, therefore, are crucial for converting the LLM’s probabilistic outputs into coherent, varied, and contextually relevant text, enabling control over the style and creativity of the generated content.
The temperature parameter in Large Language Models (LLMs) scales the logits of the predicted token probabilities before applying a softmax function. A temperature of 1.0 represents the standard probability distribution. Increasing the temperature flattens the distribution, making less probable tokens more likely to be selected, which increases output diversity but can also lead to less coherent or grammatically correct text. Conversely, decreasing the temperature sharpens the distribution, favoring the most probable tokens and resulting in more predictable, but potentially repetitive, outputs. Values typically range from 0.0 to 2.0, with lower values prioritizing accuracy and higher values prioritizing creativity.
Top-p sampling, also known as nucleus sampling, dynamically adjusts the candidate token set based on cumulative probability; it considers the smallest set of tokens whose cumulative probability exceeds the probability p, and rescales the probabilities within this set. Beam search, conversely, maintains a fixed number of likely candidate sequences – the “beam” – at each step, expanding each candidate with the most probable next tokens and pruning to maintain the beam size. This approach favors higher-probability sequences, increasing coherence, but can reduce diversity if the beam width is too narrow. Both methods offer finer-grained control than temperature scaling, allowing developers to prioritize either coherence or diversity by adjusting algorithm-specific parameters.
Breaking the Cycle: Mitigating Repetition in Language Generation
Repetition in Large Language Model (LLM) generated text manifests as the frequent recurrence of specific tokens, phrases, or sentence structures, directly diminishing the diversity of the output. This phenomenon arises from the probabilistic nature of LLM text generation; the model predicts the next token based on preceding tokens, and can become trapped in loops, particularly with high-probability sequences. The presence of repetitive content negatively impacts output quality by reducing coherence, readability, and the perceived novelty of the generated text, ultimately hindering the model’s ability to produce engaging and informative content.
The Repetition Penalty is a decoding-time parameter used in Large Language Models (LLMs) to reduce the likelihood of generating redundant text. This technique functions by applying a multiplicative penalty to the probability of each token based on its recent appearance in the generated sequence; frequently occurring tokens receive a lower probability score. The penalty is typically applied to the log probabilities of the next token, effectively discouraging the model from selecting tokens that have already been used, thereby promoting lexical diversity and preventing the model from getting stuck in repetitive loops. The strength of this penalty is controlled by a user-defined parameter, allowing for adjustments to balance diversity with coherence and fluency.
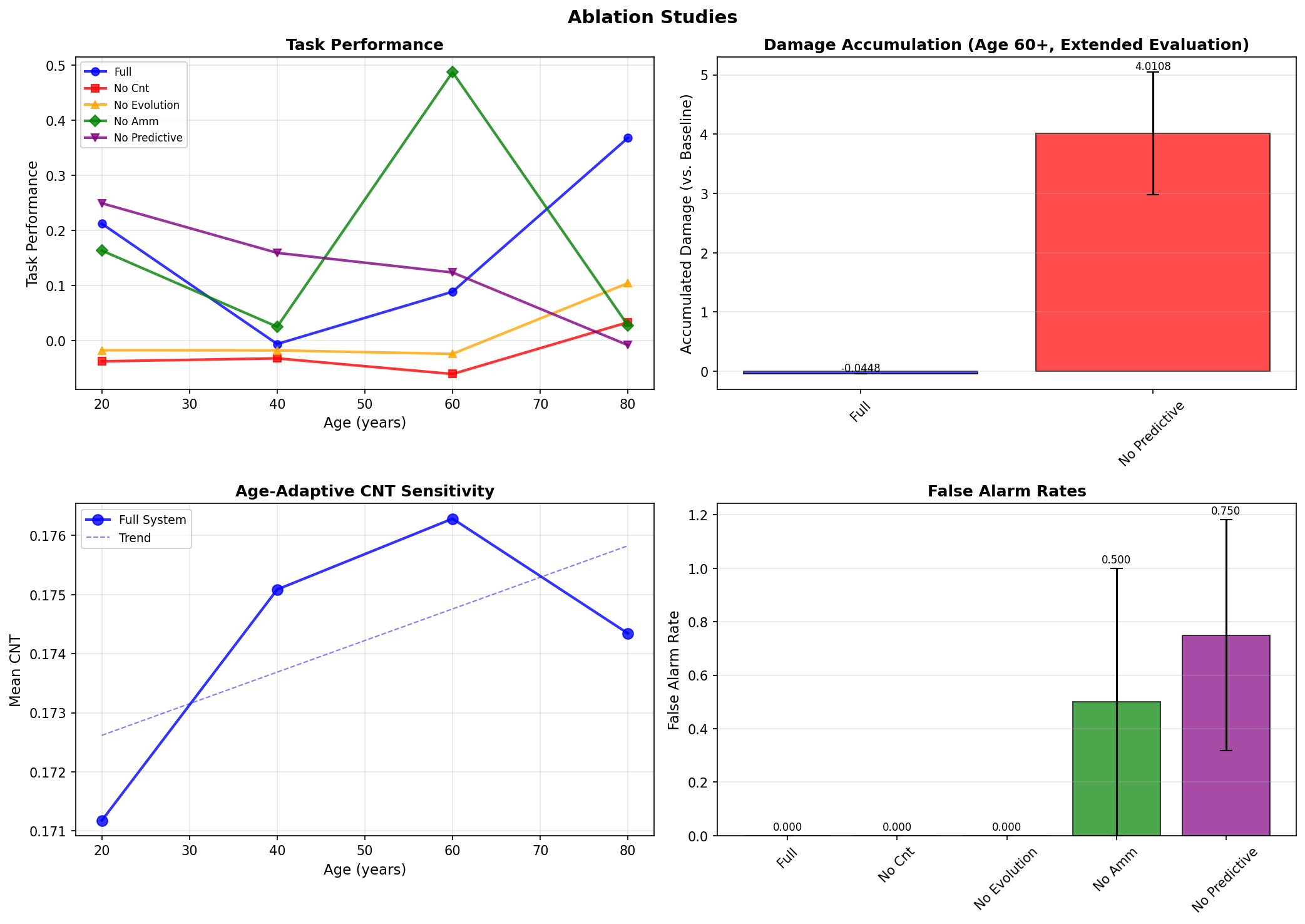
The application of a Repetition Penalty is demonstrably more effective when integrated with other decoding methods such as Beam Search or Top-p Sampling. This combination produces a synergistic effect on output diversity, exceeding the improvements achieved by the Repetition Penalty in isolation. Recent research utilizing a biologically-inspired AI framework has quantified this effect, showing a 2.8x increase in efficiency – measured by the ratio of unique tokens to total tokens – when these techniques are used in conjunction. This indicates that the combined approach not only discourages repetition but also facilitates a more efficient exploration of the model’s vocabulary, leading to significantly more diverse text generation.
Beyond Fluency: Unlocking Creative Potential and Broadening Application
The capacity to modulate diversity in large language model outputs unlocks substantial potential across creative and communicative applications. Precisely controlling the randomness of text generation allows developers to move beyond predictable, formulaic content and cultivate outputs tailored to specific needs – from crafting highly focused, factual reports to generating expansive, imaginative narratives. In creative writing, this means a system capable of producing both tightly-plotted thrillers and stream-of-consciousness poetry. For content generation, it allows for the creation of varied marketing copy or diverse educational materials. Dialogue systems benefit through the ability to produce responses ranging from concise and informative to empathetic and elaborative, significantly enhancing user engagement and realism. Ultimately, this control over diversity isn’t simply about generating more text; it’s about generating better text, suited to a wider range of purposes and audiences.
Large language models don’t simply generate text; the manner of that generation is remarkably pliable. Developers wield considerable influence through decoding strategies – the algorithms that translate the model’s internal probabilities into actual words – allowing for outputs precisely tuned to specific needs. A carefully chosen strategy can prioritize predictability and factual accuracy, yielding coherent reports or technical documentation. Conversely, adjusting those same parameters can unlock a more exploratory mode, encouraging the model to venture beyond established patterns and produce strikingly original, even unexpected, prose. This control isn’t merely about randomness; it’s about systematically shifting the balance between exploitation – sticking to what the model ‘knows’ – and exploration, fostering creativity and allowing for nuanced control over the generated content’s style and substance.
The capacity to manipulate the diversity of large language model outputs unlocks possibilities for increasingly sophisticated content creation. This fine-grained control allows developers to move beyond predictable text generation, fostering outputs that are not only more engaging and original but also exhibit greater nuance in style and tone. Recent advancements demonstrate this potential with a framework exhibiting enhanced robustness – specifically, a measured 5-13% reduction in undesirable outcomes across a broad demographic, ranging from 20 to 80 years of age. This improved performance suggests a pathway towards more reliable and creatively versatile applications of LLMs, pushing the boundaries of automated content generation and opening doors to novel forms of digital expression.
The pursuit of Afferent AI, as detailed in the study, echoes a fundamental truth about all complex systems. Though the architecture focuses on damage avoidance through learned anticipation, it implicitly acknowledges the inevitability of decay. As Blaise Pascal observed, “All of humanity’s problems stem from man’s inability to sit quietly in a room alone.” This, in the context of computational systems, suggests that even the most robust architectures-those designed to circumvent failure-are ultimately operating within a framework of impermanence. The system’s bi-level learning process, optimizing both afferent design and reinforcement learning, simply delays the inevitable, caching stability against the constant pressure of latency and eventual entropy. The elegance lies not in preventing damage entirely, but in extending the period of graceful degradation.
The Horizon of Anticipation
The pursuit of damage-avoidance learning, as demonstrated by this work with Afferent AI, inevitably reveals a fundamental tension. The architecture excels at optimizing for known failure modes within a defined simulation. However, the very act of simplifying a real-world system into a computational model introduces a debt-a narrowing of the possible failures. Each solved problem merely reshapes the landscape of potential, unforeseen consequences. The system, in becoming adept at navigating present threats, accumulates the memory of what it doesn’t know.
Future iterations will likely focus on expanding the representational capacity of these ‘Computational Afferents’. The challenge isn’t merely to detect a wider range of damage, but to model the potential for damage-to predict novelty itself. This requires moving beyond reactive adaptation towards a form of predictive modeling that acknowledges inherent uncertainty. A digital twin, no matter how detailed, remains a static echo of a dynamic reality.
Ultimately, the true metric of success won’t be the avoidance of damage, but the graceful degradation of the system over time. Every structure fails, every algorithm decays. The question is not whether to prevent this, but to design for it – to create systems that, like resilient biological organisms, can learn, adapt, and even benefit from the inevitable pressures of existence.
Original article: https://arxiv.org/pdf/2602.04807.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Brent Oil Forecast
- Gold Rate Forecast
- EUR ZAR PREDICTION
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- 币安人生 PREDICTION. 币安人生 cryptocurrency
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
2026-02-06 03:21