Author: Denis Avetisyan
New research reveals a way to detect when large language models begin to falter during reasoning, offering insights into why they sometimes fail.
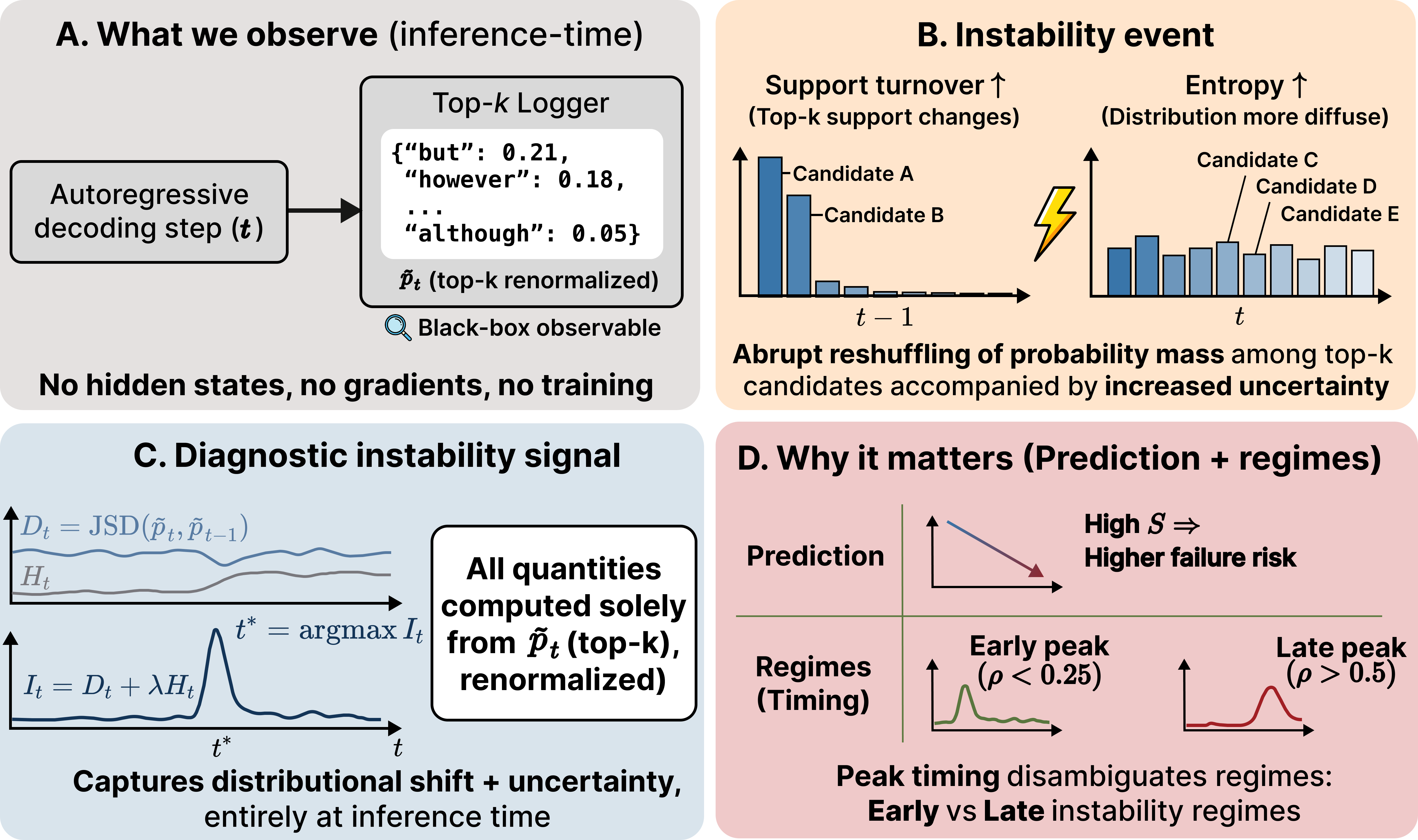
A novel diagnostic signal based on token distributions identifies dynamic instability in large language models at inference time, differentiating between corrective and destructive errors.
Despite advances in large language models, reasoning failures often manifest not as definitive errors, but as a loss of coherence mid-generation. The study ‘“I May Not Have Articulated Myself Clearly”: Diagnosing Dynamic Instability in LLM Reasoning at Inference Time’ introduces a novel, training-free diagnostic that leverages token distributions to detect this dynamic instability during inference. By combining measures of distributional shift and uncertainty, the authors demonstrate that the timing of instability-whether ‘corrective’ or ‘destructive’-is a crucial predictor of ultimate success or failure. Could a deeper understanding of these internal reasoning trajectories unlock more robust and reliable LLM performance?
Unveiling the Ephemeral Nature of LLM Reasoning
Large Language Models, despite demonstrating remarkable proficiency in tasks like text generation and translation, are susceptible to internal instabilities during the process of inference – the stage where they apply learned knowledge to new inputs. This unpredictability manifests not as simple errors, but as subtle shifts in the model’s reasoning that can lead to inconsistent or illogical outputs, even when presented with identical prompts. These instabilities aren’t necessarily tied to a lack of knowledge; rather, they stem from the complex interplay of billions of parameters and the stochastic nature of neural networks, meaning that even minor variations in computation can produce divergent results. Consequently, relying on LLMs for critical applications demanding consistent and reliable reasoning – such as medical diagnosis or legal analysis – requires a deeper understanding of these internal dynamics and the development of methods to mitigate such erratic behavior.
Current evaluation metrics for Large Language Models often present a deceptively stable picture, masking significant internal fluctuations during the process of generating text. While benchmarks might indicate high overall accuracy, they frequently fail to capture the subtle shifts in the model’s internal representations – the activation patterns and neuronal firings – that precede each predicted token. This disconnect arises because traditional metrics typically assess only the final output, overlooking the complex and sometimes chaotic decision-making process occurring within the neural network. Consequently, researchers lack a comprehensive understanding of how LLMs arrive at their conclusions, hindering efforts to improve their reliability and address unpredictable behaviors. The inability to monitor these internal shifts creates a critical gap in knowledge, preventing the development of tools to diagnose, interpret, and ultimately control the reasoning processes of these powerful, yet often opaque, artificial intelligence systems.
Illuminating Internal States: Inference-Time Diagnostics
Inference-Time Diagnostics offer a method for evaluating Large Language Model (LLM) behavior during operation without requiring any alteration to the model’s parameters or architecture. This non-invasive approach allows for real-time monitoring of internal states by analyzing the probability distributions generated during token prediction. Unlike techniques that necessitate model fine-tuning or the introduction of probe layers, Inference-Time Diagnostics operate solely on the model’s outputs, minimizing potential disruption to performance and preserving the integrity of the original LLM. This capability is crucial for applications requiring continuous monitoring, anomaly detection, and understanding the dynamic behavior of deployed models without incurring the costs or risks associated with model modification.
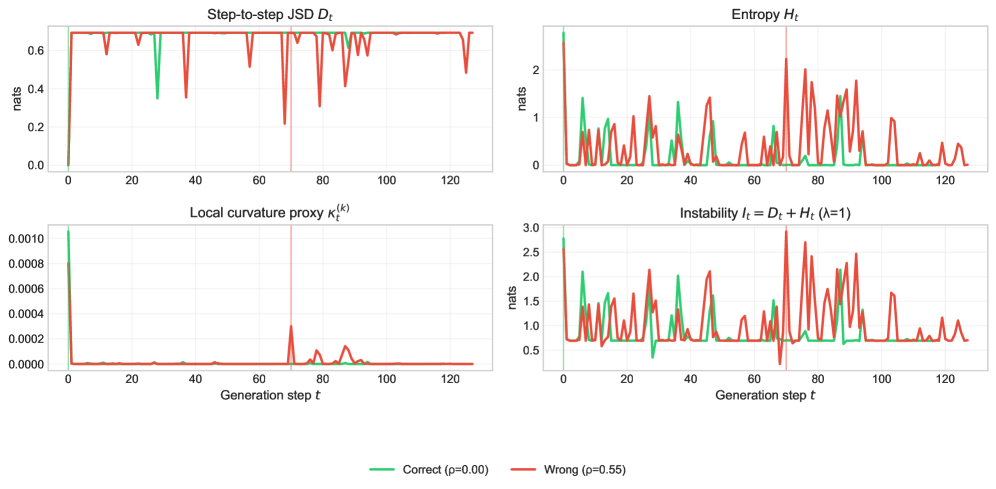
The Instability Signal serves as a quantitative metric for tracking distributional shifts in Large Language Model (LLM) outputs during inference. It is calculated by combining Entropy and Jensen-Shannon Divergence (JSD). Entropy, measured in bits, quantifies the uncertainty of the predicted token probability distribution; higher entropy indicates greater uncertainty. JSD, ranging from 0 to 1, measures the similarity between the predicted probability distribution and a reference distribution (typically the distribution observed on a calibration dataset); values closer to 0 indicate higher similarity. The Instability Signal is derived from these two values, providing a single score reflecting changes in the model’s output distribution and serving as an indicator of potential issues like hallucination or prompt sensitivity. Instability = Entropy + JSD
Top-k Truncation is implemented to reduce the computational burden of calculating Entropy and Jensen-Shannon Divergence (JSD) during inference-time diagnostics. This technique limits the consideration of potential tokens to only the k most probable tokens at each step of the LLM’s generation process. By discarding low-probability tokens, the dimensionality of the probability distribution used in these calculations is significantly reduced. This optimization does not alter the core diagnostic measurement but improves processing speed and lowers memory requirements, allowing for more efficient monitoring of LLM states without substantial performance overhead. The value of k represents a tunable parameter balancing computational efficiency against potential information loss.
Dissecting Dynamic Instability: Recovery and Failure Modes
Dynamic Instability, as observed in our analysis, presents in two distinct forms differentiated by outcome: Corrective Instability and Destructive Instability. Corrective Instability is characterized by an initial deviation from stable processing, followed by recovery and the eventual production of a correct output. Conversely, Destructive Instability also begins with a deviation, but this results in an incorrect or failed output, indicating an inability of the model to self-correct. This distinction is crucial for diagnostic purposes, as the type of instability directly correlates with the ultimate performance of the model and informs strategies for mitigation or intervention.
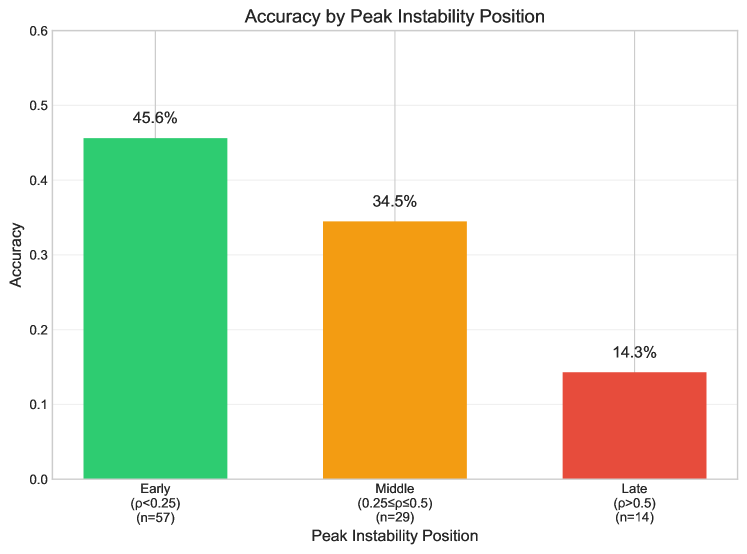
Analysis of model instability reveals a correlation between the timing of peak activity and the resulting behavior. Peak Position, representing the point at which instability is most pronounced, serves as a diagnostic indicator: instances of Corrective Instability, where the model ultimately produces a correct output, are frequently associated with earlier peak positions. Conversely, Destructive Instability, leading to incorrect results, typically manifests with later peaks. This suggests that the model’s ability to recover from internal perturbations decreases as the peak of instability is delayed, transitioning from self-correction to failure as the instability persists for a longer duration.
Analysis of model traces indicates a correlation between specific metrics and the type of dynamic instability observed. Corrective instability events are frequently associated with a Margin Drop of 1.82, significantly higher than the 1.05 observed during traces leading to incorrect outputs. Conversely, Destructive Instability is often characterized by Support Set Turnover, occurring in 84% of corrective traces but only 82% of incorrect ones. These quantitative differences in Margin Drop and Support Set Turnover provide measurable diagnostic signals that can be utilized to differentiate between recoverable and irrecoverable instability events within the model.
Validating Robustness Across Reasoning Benchmarks
The efficacy of Inference-Time Diagnostics was rigorously evaluated through application to established reasoning benchmarks, specifically GSM8K and HotpotQA. GSM8K, a dataset centered on grade school mathematics problems, provided a challenging arena for assessing the diagnostic’s ability to detect instability during numerical reasoning. Complementing this, HotpotQA – a multi-hop question answering dataset – tested the system’s capacity to identify issues arising from complex information retrieval and synthesis. By subjecting the diagnostics to these diverse and well-regarded benchmarks, researchers aimed to demonstrate its broad applicability and validate its potential for improving the reliability of large language models across various reasoning tasks.
Analysis reveals a significant link between the internal instability of large language models and their performance on complex reasoning tasks. Specifically, metrics designed to detect these instability signals demonstrate a strong correlation with answer accuracy across benchmarks like GSM8K, a challenging dataset of grade school math problems. Quantitative results on GSM8K show an Area Under the Curve (AUC) score ranging from 0.66 to 0.74, indicating the ability to predict incorrect responses based on these instability measures. This suggests that identifying and mitigating these internal fluctuations is not merely a matter of improving model efficiency, but is fundamentally tied to enhancing the reliability and trustworthiness of LLM-driven reasoning.
The capacity for consistent and dependable reasoning in large language models hinges significantly on their internal stability. Recent findings demonstrate a clear link between measurable instability – fluctuations during the inference process – and a decline in the accuracy of responses across complex reasoning tasks, such as mathematical problem solving and multi-step question answering. This suggests that addressing these instability issues isn’t merely about incremental improvements, but a fundamental requirement for building truly reliable artificial intelligence. By focusing on methods to enhance stability, researchers and developers can pave the way for LLMs capable of consistently delivering accurate and trustworthy results, unlocking their full potential in critical applications.
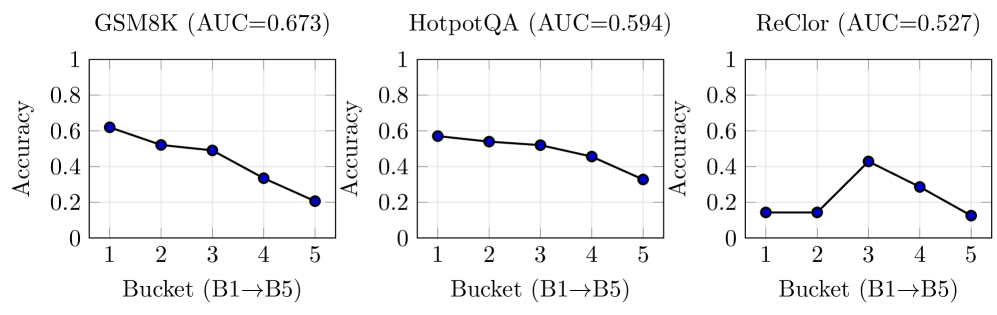
The study illuminates a crucial point about complex systems: seemingly minor fluctuations at inference time can precipitate significant instability. This echoes G.H. Hardy’s assertion that “mathematics may be compared to a box of tools,” where even a slight misalignment can render the entire mechanism ineffective. The research demonstrates that identifying when dynamic instability occurs-whether correctively or destructively-is vital for predicting failure in large language models. Much like an architect understands the structural consequences of altering a single beam, this work highlights the interconnectedness of token distributions and reasoning pathways, revealing that a holistic understanding is paramount when addressing emergent behaviors in these systems. The timing of instability, as pinpointed by trajectory analysis, becomes a key diagnostic signal, reflecting the delicate balance within the model’s operational framework.
The Path Forward
The identification of dynamic instability at inference time, and its linkage to the timing of corrective or destructive shifts in token distributions, reveals a critical gap in current evaluation paradigms. Documentation captures structure – the weights, the training data – but behavior emerges through interaction. This work suggests that a model’s apparent competence is, at best, a snapshot; a transient state susceptible to subtle shifts during the very act of reasoning. The field must now grapple with the implications of such inherent fragility.
Future investigations should move beyond simply detecting instability to understanding its origins. Is it a consequence of the training process, an artifact of the decoding strategy, or a fundamental limitation of the scaling laws currently governing large language model development? Moreover, the distinction between corrective and destructive instability offers a promising avenue for targeted interventions. Can models be steered away from detrimental trajectories, or even trained to self-correct before catastrophic divergence?
Ultimately, a complete understanding necessitates a shift in perspective. Current metrics largely assess the outcome of reasoning. The focus must broaden to encompass the process itself-the dynamic interplay of probabilities, the subtle shifts in internal state, and the delicate balance between coherence and collapse. Only then can the field move beyond building increasingly large models and towards crafting truly robust and reliable reasoning systems.
Original article: https://arxiv.org/pdf/2602.02863.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- EUR/ZAR
- Silver Rate Forecast
- Gold Rate Forecast
- Emily Henry Says to ‘Trust the Vision’ For Beach Read Adaptation
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
2026-02-06 01:35