Author: Denis Avetisyan
New research reveals that repeated interactions between generative AI models can exacerbate existing demographic biases, leading to the reinforcement of harmful stereotypes.

Iterative exchanges between generative and recognition models demonstrate a concerning trend of associational bias and demographic drift in generated content.
Despite advances in generative AI, subtle biases can propagate and amplify within complex, interconnected systems. This research, ‘Investigating Associational Biases in Inter-Model Communication of Large Generative Models’, examines how demographic biases evolve during iterative exchanges between generative and recognition models-specifically, in pipelines alternating between image generation and description for human activity and affective expression. Our findings reveal a consistent drift toward younger and more female-presenting representations, driven by spurious visual cues rather than concept-relevant information, and demonstrate that these shifts can impact downstream prediction accuracy. How can we develop effective mitigation strategies to safeguard against the perpetuation of harmful stereotypes in increasingly interconnected human-centred AI systems?
The Iterative Echo: Refinement Through Visual-Textual Dialogue
Contemporary image captioning systems, despite advancements in artificial intelligence, frequently struggle with providing richly detailed and consistently accurate descriptions of visual content. These models often produce generalized captions that fail to capture the subtleties of a scene – missing key objects, overlooking intricate relationships between elements, or misinterpreting complex actions. This limitation stems from a reliance on broad statistical patterns learned from massive datasets, rather than a true understanding of visual information; consequently, the resulting captions can be vague, incomplete, or even contain factual inaccuracies. The inability to discern and articulate nuanced details hinders the utility of these systems in applications requiring precise visual understanding, such as assistive technologies for the visually impaired or detailed image retrieval.
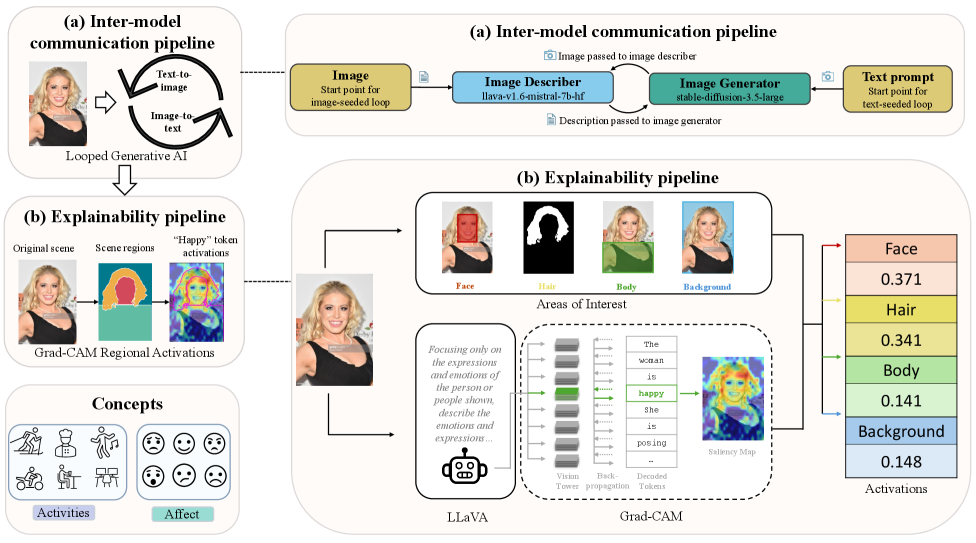
An innovative approach to image captioning utilizes a communication pipeline connecting image-to-text and text-to-image models in a continuous loop. Initially, an image is processed by the image-to-text model, generating a descriptive caption. This caption is then fed into the text-to-image model, which reconstructs an image based on the textual description. The reconstructed image is compared to the original, and discrepancies are used to refine the caption in a subsequent iteration. This cyclical process-where text informs image generation, and image quality guides textual improvement-allows the system to progressively enhance the detail and accuracy of the description. By repeatedly synthesizing and evaluating, the pipeline effectively ‘self-corrects’, yielding captions that surpass the fidelity of traditional, single-pass methods, though careful consideration must be given to potential amplification of existing biases within the models.
The advancement of visually-grounded language models relies heavily on the availability of high-quality, richly annotated datasets. Collections like PHASE and RAF-DB are particularly valuable, as they move beyond simple object recognition to incorporate detailed labels for human activity, emotional states, and facial expressions. These datasets provide the necessary training data for models to learn the subtle connections between visual cues and descriptive language, enabling them to generate captions that are not only accurate but also nuanced and contextually relevant. The depth of annotation within these resources allows researchers to rigorously evaluate a model’s ability to perceive and articulate complex human behaviors, ultimately driving improvements in areas such as assistive technology, behavioral analysis, and human-computer interaction.
The strength of iteratively refined image captioning lies in its capacity for self-correction, surpassing the limitations of single-pass methods by continuously comparing generated text with the original image and adjusting accordingly. This feedback loop fosters increasingly accurate and detailed descriptions, allowing the model to progressively refine its understanding of visual content. However, this process isn’t without caveats; research indicates that these iterative systems can inadvertently introduce and even amplify existing demographic biases present within the training data. Subtle, yet pervasive, prejudices can become exaggerated through repeated cycles of generation and refinement, leading to descriptions that unfairly stereotype or misrepresent individuals based on attributes like gender or ethnicity – a critical challenge demanding ongoing attention and mitigation strategies.
Unveiling the ‘Why’: Towards Interpretable Visual Reasoning
Historically, image understanding systems, particularly those employing deep learning architectures, have operated as largely “black box” models. While achieving high accuracy in tasks like image classification and object detection, these methods often provide limited insight into why a particular prediction was made. This lack of transparency stems from the complex, non-linear transformations applied to input images across numerous layers. Consequently, identifying the specific visual features – edges, textures, objects – that most strongly influenced the model’s decision is challenging. Without this interpretability, debugging model errors, ensuring fairness, and building trust in the system’s outputs become significantly more difficult, hindering broader adoption in critical applications.
Grad-CAM (Gradient-weighted Class Activation Mapping) is a visualization technique used to identify the image regions most influential to a convolutional neural network’s (CNN) prediction. It works by utilizing the gradients of any target concept flowing into the final convolutional layer to weight the feature maps. These weighted feature maps are then globally average-pooled to obtain a single activation map highlighting the important regions in the input image. This resulting heatmap indicates the areas the CNN focused on when making its classification, providing insight into the model’s decision-making process and enabling a degree of interpretability. The technique is model-agnostic, applicable to any CNN architecture, and requires only forward propagation of the gradient during training.
Token-Conditioned Saliency builds upon techniques like Grad-CAM by moving beyond a single heatmap representing overall image importance. It operates at the level of individual output tokens, identifying the specific regions within the input image that most strongly support the generation of each word or sub-word unit in the descriptive caption. This is achieved by calculating the gradient of the token’s log-probability with respect to the input image features, effectively mapping which visual elements contributed most to that particular token’s prediction. The resulting saliency maps, one per token, provide a more fine-grained and interpretable understanding of the model’s reasoning process, revealing how different parts of the image contribute to different aspects of the generated description.
Regional Aggregation enhances interpretability by moving beyond pixel-level saliency maps to analyze model behavior at the level of semantically meaningful image regions. This technique involves partitioning an image into distinct regions and then aggregating the saliency contributions from individual tokens that correspond to those regions. By summing or averaging the saliency values within each region, we obtain a more robust and localized indication of which areas are most influential in driving the model’s prediction. This aggregated view reduces noise, clarifies the model’s focus, and provides a more readily understandable visualization of the image features contributing to the final output, offering a granular understanding of model behavior beyond broad, pixel-wise highlighting.

Mitigating Bias: A Pursuit of Fair Representation
Generative models, when trained on datasets containing societal biases, demonstrate a tendency to replicate and intensify existing stereotypes, manifesting as Associational Bias. This bias occurs when the model learns and reinforces correlations present in the training data, even if those correlations are inaccurate or unfair. A key consequence of this is Demographic Drift, wherein the distribution of demographic attributes in the generated outputs diverges from the distribution in the training data or desired representation. This drift indicates a systematic skewing of generated content, potentially underrepresenting or misrepresenting certain demographic groups and perpetuating harmful stereotypes. The degree of this drift is measurable, and observed variations can significantly impact the fairness and inclusivity of model outputs.
Spurious correlations occur when machine learning models identify and leverage unintended relationships between input features and target variables, leading to biased outcomes. These correlations, while statistically present in the training data, are not causally related to the desired prediction and can be based on irrelevant attributes. Consequently, models may prioritize these spurious features during inference, resulting in inaccurate or unfair predictions, particularly for underrepresented groups. The reliance on these irrelevant features amplifies existing biases within the dataset, as the model learns to associate demographic characteristics with outcomes based on these accidental relationships rather than genuine patterns. This phenomenon can manifest as decreased performance and increased disparity in model outputs across different demographic segments.
Several training techniques are employed to mitigate biases present in generative models. Counterfactual Data Augmentation involves creating modified versions of training examples by altering sensitive attributes, thereby exposing the model to a wider range of scenarios and reducing reliance on biased correlations. Attribute-Aware Training explicitly incorporates sensitive attributes as inputs during training, allowing the model to learn representations that are less correlated with these attributes. Adversarial Training introduces an adversarial network that attempts to predict sensitive attributes from the model’s output; the generator is then trained to minimize the adversary’s accuracy, effectively decorrelating the generated content from those attributes and promoting fairness.
Fair Diffusion and Group Tagging techniques, while intended to improve demographic representation in generated outputs, demonstrated a statistically significant demographic drift during evaluation (Stuart-Maxwell Test p-value < 0.001). Analysis revealed limited overlap between pre- and post-loop demographic distributions, with Cohen’s Kappa values ranging from 0.22 to 0.85 and weighted Jaccard Similarity ranging from 0.33 to 0.91. Demographic Parity exhibited variable changes, increasing bias by up to +6.53% and decreasing it by up to -10.96% depending on the specific activity and emotion. Furthermore, model accuracy on the RAF-DB dataset decreased significantly following the application of these loops, falling within the range of 47% to 85%. These results indicate that while these methods offer control mechanisms, they can also introduce or exacerbate biases and negatively impact performance.

Towards Robust and Ethical Visual Storytelling
The creation of trustworthy artificial intelligence for visual storytelling hinges on a multi-faceted approach to system development. Current research indicates that simply increasing model size is insufficient; instead, continuous refinement-where systems learn from feedback and improve over time-is crucial. This process is strengthened by incorporating interpretability techniques, allowing researchers to understand why an AI generates a particular description and identify potential flaws. Critically, bias mitigation strategies are essential to counteract inherent prejudices within training data, ensuring generated narratives are not only accurate and detailed but also equitable and free from harmful stereotypes. By converging these elements, developers are striving to build AI systems capable of producing visual descriptions that are both technically sound and ethically responsible, paving the way for more inclusive and reliable applications.
The potential of AI-driven visual storytelling extends far beyond simple image captioning, promising transformative applications across multiple sectors. For individuals with visual impairments, these systems offer the prospect of richly detailed and nuanced descriptions of the world around them, fostering greater independence and access to information. Simultaneously, content creators can leverage this technology to streamline workflows, generate diverse visual content, and explore novel artistic avenues. Perhaps most significantly, automated reporting benefits from the capacity to rapidly analyze and summarize visual data, offering a powerful tool for journalists, researchers, and organizations requiring efficient information dissemination – ultimately democratizing access to visually-sourced insights and narratives.
Establishing reliable metrics for fairness in visual storytelling remains a significant hurdle, as current evaluations often struggle to capture nuanced biases embedded within generated narratives. Beyond immediate accuracy, ensuring long-term robustness requires proactive strategies to counter ‘concept drift’ – the tendency of AI models to degrade in performance as the real world evolves and data distributions shift. Researchers are actively exploring techniques like adversarial training and continual learning to fortify these systems against unforeseen scenarios and maintain equitable outcomes over extended periods. This includes developing methods to detect and mitigate subtle yet pervasive biases that might perpetuate harmful stereotypes or misrepresent diverse perspectives, ultimately fostering trust and responsible innovation in AI-driven visual communication.
The capacity of contemporary AI to generate visual storytelling hinges significantly on the art of prompt engineering. These models, while powerful, are fundamentally reactive to the instructions they receive; carefully crafted prompts serve as the crucial interface between human intention and machine output. A well-designed prompt doesn’t merely request a description, but actively shapes the narrative-specifying desired details, stylistic elements, and even ethical considerations. This process requires iterative refinement, as subtle changes in wording can dramatically alter the generated content, influencing both its accuracy and its potential biases. Consequently, prompt engineering isn’t simply a technical skill, but a creative practice demanding nuanced understanding of both the AI’s capabilities and the potential implications of the stories it constructs.

The research into associational biases within interconnected generative models reveals a predictable truth about complex systems: decay is not failure, but an inherent property. As models iteratively communicate, demographic drifts amplify, creating stereotypical associations – a form of technical debt accruing with each exchange. Grace Hopper famously stated, “It’s easier to ask forgiveness than it is to get permission.” This resonates deeply, for attempting to prevent all bias upfront is often a futile exercise; instead, the focus must shift to detecting and mitigating these drifts as they emerge. The study highlights that while initial models may be relatively unbiased, the very act of communication introduces a timeline of potential corruption, demanding continuous auditing and corrective action. Every bug, or biased association, is a moment of truth in the timeline, revealing the system’s age and necessitating a response.
What’s Next?
The observed amplification of associational biases across iterative model exchanges isn’t a failure of technique, but a predictable consequence of system evolution. Each communication step, ostensibly refining the output, subtly layers existing societal preconceptions onto the generative process. The drift isn’t random; it’s a directed accumulation of error, traceable to the initial conditions embedded within the training data-and the implicit assumptions baked into the architecture itself. Time, in this context, isn’t a metric for progress, but the medium in which these errors propagate.
Future work must move beyond simply detecting bias and focus on quantifying the rate of demographic drift within interconnected systems. Understanding the dynamics of this decay-the specific architectural features that accelerate or mitigate it-is paramount. Mitigation strategies that attempt to ‘correct’ outputs after bias manifests are treating symptoms, not addressing the underlying pathology. The challenge lies in designing systems that acknowledge the inevitability of error and build in mechanisms for graceful degradation, rather than striving for an illusory state of neutrality.
Ultimately, this line of inquiry isn’t solely about improving generative AI. It’s a study in applied epistemology-a recognition that all models, regardless of their complexity, are imperfect representations of reality, perpetually subject to the pressures of time and the accumulation of systemic flaws. The incidents observed here aren’t anomalies; they are system steps toward maturity-a painful, but necessary, process of revealing underlying assumptions.
Original article: https://arxiv.org/pdf/2601.22093.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Brent Oil Forecast
- Gold Rate Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- EUR ZAR PREDICTION
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
2026-01-31 16:06