Author: Denis Avetisyan
New research shows that large language models, combined with a clever data retrieval technique, can accurately forecast which startups are likely to thrive, even with limited information.
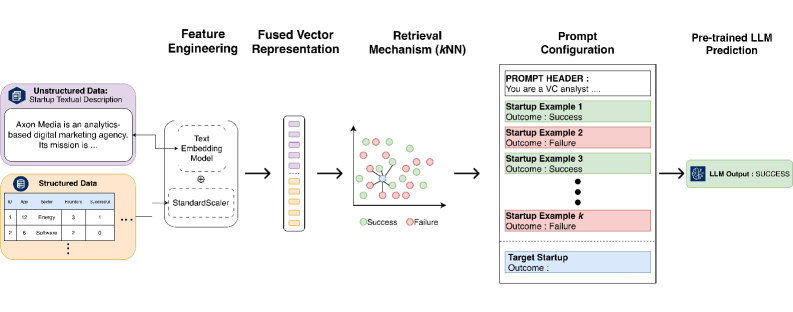
A novel in-context learning framework leveraging k-nearest neighbors and large language models demonstrates improved startup success prediction, particularly in data-scarce environments.
Predicting the success of early-stage startups remains a persistent challenge despite the potential for high returns on venture capital investments. This paper, ‘Predicting Startup Success Using Large Language Models: A Novel In-Context Learning Approach’, introduces a novel framework leveraging large language models (LLMs) to address data scarcity issues common in startup evaluation. Specifically, the authors demonstrate that a k-nearest neighbor-based in-context learning (kNN-ICL) approach can outperform traditional supervised machine learning methods with limited labeled data. Could this paradigm shift offer a viable decision-making tool for venture capital firms operating in data-constrained environments and unlock more accurate startup valuations?
The Persistent Challenge of New Venture Prediction
The pursuit of reliably forecasting startup success represents a persistent hurdle for both those providing capital and the entrepreneurs seeking it. While venture capital and angel investment fuel innovation, the inherent risk associated with nascent companies remains exceptionally high; a significant percentage ultimately fail to deliver expected returns. This difficulty isn’t merely a matter of market volatility; the very nature of startups – characterized by limited historical data, rapidly evolving strategies, and dependence on unproven technologies – complicates predictive modeling. Consequently, investors face substantial uncertainty in allocating resources, and founders struggle to validate their visions and secure necessary funding, highlighting the critical need for improved methods to assess early-stage ventures and navigate the complex landscape of innovation.
The application of supervised machine learning to predict startup success frequently encounters a critical roadblock: a lack of sufficient labeled data, particularly in a venture’s formative months. These algorithms thrive on extensive historical datasets, yet early-stage startups, by their very nature, offer limited operational history for training purposes. Consequently, models struggle to discern meaningful patterns or accurately assess risk, often relying on incomplete information or extrapolating from established businesses in different sectors. This ‘data scarcity’ issue necessitates alternative approaches that can effectively learn from smaller datasets, incorporate external knowledge, or leverage unstructured information sources to compensate for the lack of readily available, labeled examples.
Current methods for evaluating startup potential often operate with a fragmented view of available information. While quantitative metrics – such as founding year, team size, and funding amounts – offer easily digestible data points, they frequently fail to capture the nuances of a company’s vision or market positioning. Conversely, analyses of qualitative data, like business plans and executive summaries, can provide valuable insights into a startup’s strategy and potential, but are difficult to integrate with structured datasets. The inability to effectively combine these distinct data types – leveraging the precision of structured information with the contextual richness of textual data – limits the predictive power of existing models and hinders a holistic assessment of a venture’s likelihood of success. A truly robust evaluation requires a framework capable of synergistically utilizing both, moving beyond isolated analyses to capture the complete picture of a startup’s viability.
Learning from the Past: Introducing kkNN-ICL
kkNN-ICL is a new framework designed to predict startup outcomes by integrating In-Context Learning (ICL) with Large Language Models (LLMs). The system utilizes the predictive capabilities of LLMs, but avoids the typical requirement for large, labeled training datasets. Instead, kkNN-ICL relies on providing relevant examples directly to the LLM within the input prompt – a process known as In-Context Learning. This approach allows the LLM to leverage patterns and insights from these provided examples to make predictions about new startups, effectively learning from a curated set of past data without explicit retraining.
kkNN-ICL improves upon standard In-Context Learning (ICL) by employing a retrieval mechanism based on Cosine Similarity. Rather than utilizing a fixed or random selection of example startups, our framework calculates the similarity between the input startup’s feature vector and those of past startups stored in a reference set. This calculation quantifies the angle between the vectors, with smaller angles indicating higher similarity. The k most similar startups, as determined by their Cosine Similarity scores, are then retrieved and used as examples for the Large Language Model (LLM), effectively focusing the LLM’s attention on the most relevant historical data and improving prediction accuracy. This contrasts with traditional ICL methods that often rely on manually curated or randomly sampled examples, which may not be optimally suited for the current prediction task.
kkNN-ICL reduces reliance on large, labeled datasets for startup prediction by utilizing a retrieval-augmented approach. Instead of requiring extensive training data, the framework identifies past startups with similar characteristics to the current one – as determined by cosine similarity – and incorporates this information directly into the LLM prompt. This allows the LLM to leverage patterns observed in previously successful or unsuccessful ventures to inform predictions about the target startup, effectively performing inference based on analogous examples rather than generalized, learned parameters from a labeled dataset. This circumvention of traditional supervised learning requirements significantly lowers the data acquisition and annotation costs associated with building predictive models.
Validating kkNN-ICL: Performance and Metrics
Experiments were conducted utilizing datasets sourced from Crunchbase, encompassing information on venture capital firms and the startups they fund, to evaluate the performance of kkNN-ICL in predicting startup success. Results demonstrate that kkNN-ICL significantly outperforms comparative baseline models in this predictive capacity. Specifically, kkNN-ICL achieved a balanced accuracy of 71.3% and an F1-score of 0.632, utilizing only 50 in-context examples, which surpasses the performance of supervised machine learning methods such as Random Forest (balanced accuracy of 0.634) and Logistic Regression (F1-score of 0.488).
Performance evaluation utilized both F1-Score and Balanced Accuracy due to the inherent class imbalance within the startup success prediction dataset. F1-Score, calculated as the harmonic mean of precision and recall, provides a single metric representing the model’s accuracy on the minority class, which is crucial for imbalanced data. Balanced Accuracy addresses the impact of imbalanced datasets by averaging the recall obtained on each class, providing a more representative measure of overall performance than standard accuracy. These metrics were selected to ensure a comprehensive assessment that avoids overestimation of performance due to the prevalence of successful startups in the dataset and accurately reflects the model’s ability to identify both successful and unsuccessful ventures.
Evaluations using the Crunchbase dataset demonstrate that the kkNN-ICL model achieves a balanced accuracy of 71.3% and an F1-score of 0.632 when utilizing only 50 in-context examples. This performance surpasses that of several supervised machine learning baselines; specifically, Random Forest attained a balanced accuracy of 63.4%, while Logistic Regression achieved an F1-score of 0.488 under the same testing conditions. These results indicate a quantifiable improvement in predictive capability with kkNN-ICL, even with a limited number of in-context learning examples.
kkNN-ICL’s predictive capability stems from its ability to synthesize information from both structured and textual data sources. Utilizing data from Crunchbase and VC Firms, the model doesn’t rely solely on quantifiable features, but also incorporates qualitative insights present in textual descriptions. This integration allows kkNN-ICL to identify complex relationships and nuanced signals that may be missed by models trained exclusively on structured data, resulting in improved prediction accuracy as evidenced by its performance exceeding supervised machine learning baselines like Random Forest and Logistic Regression when evaluated with metrics like balanced accuracy and F1-score.
Navigating the Future: Impact and Extended Capabilities
The prediction of startup success remains a formidable challenge, often hampered by the limited availability of reliable data – a common scenario for nascent companies. The kkNN-ICL framework presents a pragmatic and demonstrably effective approach to navigating this data scarcity. By combining the strengths of large language models with intelligent example retrieval – specifically, identifying and leveraging the most relevant historical startup data – the system constructs insightful predictions even when faced with minimal information. This methodology moves beyond traditional statistical modeling, offering a nuanced understanding of factors influencing startup outcomes and providing a valuable tool for both investors seeking promising ventures and founders striving to optimize their strategies. The framework’s adaptability and performance suggest it can significantly improve decision-making in the high-stakes world of startup investment and innovation.
The potential for improved decision-making in the volatile startup landscape is significantly enhanced through the combined power of large language models and intelligent example retrieval. This framework doesn’t simply analyze data; it learns from the successes and failures of similar ventures, identifying nuanced patterns often missed by traditional predictive models. By presenting investors and founders with carefully selected, relevant case studies – effectively ‘showing’ rather than ‘telling’ – the system facilitates a more intuitive grasp of potential outcomes. This approach moves beyond mere statistical probability, providing contextual insights that enable more informed risk assessment and strategic planning, ultimately increasing the likelihood of securing funding and achieving sustainable growth.
Investigations are planned to incorporate ‘Fused LLM’ architectures into the kkNN-ICL framework, a move expected to significantly boost computational efficiency and allow for deployment on resource-constrained devices. This advancement will not only reduce the costs associated with prediction but also broaden accessibility for startups lacking extensive infrastructure. Beyond startup success prediction, the team intends to extend the framework’s capabilities to encompass a wider range of forecasting tasks, including market trend analysis and customer behavior prediction. These expansions will leverage the adaptability of the kkNN-ICL approach, demonstrating its potential as a versatile tool for data-driven decision-making across diverse business applications and potentially beyond, fostering a more proactive and informed approach to risk assessment and opportunity identification.
The pursuit of predictive accuracy, as demonstrated in this study of startup success, often leads to increasingly complex models. However, the kkNN-ICL framework elegantly sidesteps this tendency. It prioritizes effective information retrieval and leverages the inherent capabilities of large language models with minimal parameters-a testament to the power of simplicity. As Brian Kernighan aptly stated, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This sentiment resonates deeply with the approach detailed within; the method eschews unnecessary intricacy in favor of a robust, easily interpretable system, acknowledging that true innovation lies not in complexity, but in refined clarity.
What Lies Ahead?
The demonstrated efficacy of kkNN-ICL, while encouraging, does not resolve the fundamental tension inherent in predicting ventures built on novelty. Success, by definition, often resides outside the bounds of existing data. This work offers a refinement of the method of prediction, but does not address the irreducible uncertainty of the subject matter. Future iterations should not focus solely on increasing predictive accuracy – a pursuit approaching asymptotic futility – but rather on quantifying the limits of predictability itself.
A crucial extension lies in disentangling correlation from causation within the retrieved examples. The model identifies patterns associated with success, but offers no insight into why those patterns matter. Investigating the informational content of the nearest neighbors – moving beyond simple cosine similarity – could reveal the underlying mechanisms driving startup outcomes. Furthermore, the framework’s sensitivity to the quality of the initial data remains a practical constraint. A robust methodology for data augmentation, or for identifying and mitigating biased examples, is essential.
Ultimately, the value of this approach may not be in forecasting which startups will succeed, but in providing a clearer understanding of what constitutes a viable venture. The model, when viewed not as an oracle, but as a sophisticated distillation of past attempts, offers a lens through which to examine the anatomy of innovation. The pursuit of prediction should yield, as a byproduct, a more rigorous taxonomy of entrepreneurial strategies.
Original article: https://arxiv.org/pdf/2601.16568.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Netflix’s Little House On The Prairie Reboot: Release Date, Cast & Everything We Know
- Off Campus Season 1 Soundtrack Guide
- YouTuber arrested after viral AI bodycam videos spark real police complaints
- Silver Rate Forecast
- Prime Video’s New R-Rated Spy Thriller Is Officially No.1 On Streaming Despite Poor Reviews
- Gold Rate Forecast
- Brent Oil Forecast
- Bulgakov’s Take: Koreans Bet the Farm on Chips, Crypto, and Chaos
- Peaky Blinders: The Immortal Man’s Tommy Shelby Is a Better Father Than Michael Corleone
- EUR ZAR PREDICTION
2026-01-26 11:39