Author: Denis Avetisyan
A novel federated learning framework combines survival analysis with differential privacy to improve credit risk assessment while protecting sensitive financial data.
This paper introduces FSL-BDP, a federated learning system leveraging Bayesian differential privacy for enhanced credit risk prediction and data security.
Cross-institutional data sharing is crucial for robust credit risk modeling, yet increasingly constrained by data privacy regulations. To address this paradox, we introduce ‘FSL-BDP: Federated Survival Learning with Bayesian Differential Privacy for Credit Risk Modeling’, a novel framework that enables collaborative learning of time-to-default trajectories without centralizing sensitive borrower data. Our experiments demonstrate that, in federated settings, Bayesian Differential Privacy not only achieves comparable performance to non-private models but also outperforms classical Differential Privacy-a surprising reversal of traditional benchmarks. This finding suggests that the optimal privacy mechanism is fundamentally dependent on the deployment architecture, raising the question of how to best evaluate and select privacy-preserving techniques for multi-institutional risk modeling.
Decoding Risk: Beyond Static Scores and Towards Predictive Timelines
Conventional credit scoring systems often categorize individuals into simplistic ‘good’ or ‘bad’ risk profiles, a practice that fundamentally obscures critical details about when repayment difficulties might emerge. This binary approach fails to account for the gradual increase in risk that frequently precedes a default; an individual may begin with reliable payments, then exhibit lengthening delays, before ultimately failing to meet obligations. By disregarding these nuanced repayment timelines, current models not only underestimate the true extent of risk but also impede proactive intervention strategies. Consequently, lenders struggle to accurately assess potential losses, and borrowers who are early in the process of financial strain are denied opportunities for assistance or more appropriate credit products, potentially accelerating their path toward default and exacerbating systemic financial instability.
Conventional credit scoring often distills financial health into a simplistic good-or-bad categorization, a practice that fundamentally overlooks a critical dimension: the time remaining until a potential default. This omission isn’t merely a matter of analytical refinement; accurate prediction of ‘time-to-default’ offers a significantly more granular and actionable risk profile. Regulators increasingly demand this level of foresight, not only for improved capital allocation and systemic stability, but also to facilitate earlier interventions with struggling borrowers. Beyond compliance, understanding when a default is likely to occur allows lenders to proactively manage risk-potentially mitigating losses through targeted assistance or adjusted loan terms-and provides a more complete picture of an individual’s financial trajectory than a static credit score ever could.
Current credit risk modeling largely depends on centralized databases, where sensitive financial information is pooled and analyzed by a limited number of institutions. This practice introduces significant privacy vulnerabilities, as data breaches or misuse could have devastating consequences for individuals. Furthermore, the concentration of data and analytical power discourages collaboration; institutions are often hesitant to share proprietary models or data, even when doing so could improve overall risk assessment and benefit the financial system as a whole. This lack of interoperability not only limits the development of more accurate and robust risk predictions, but also creates systemic risks by preventing a comprehensive view of interconnected financial exposures. The need for a more decentralized and privacy-preserving approach is becoming increasingly apparent, one that allows for collaborative insights without compromising individual financial security.
Federated Survival Learning: A System for Collaborative Risk Prediction
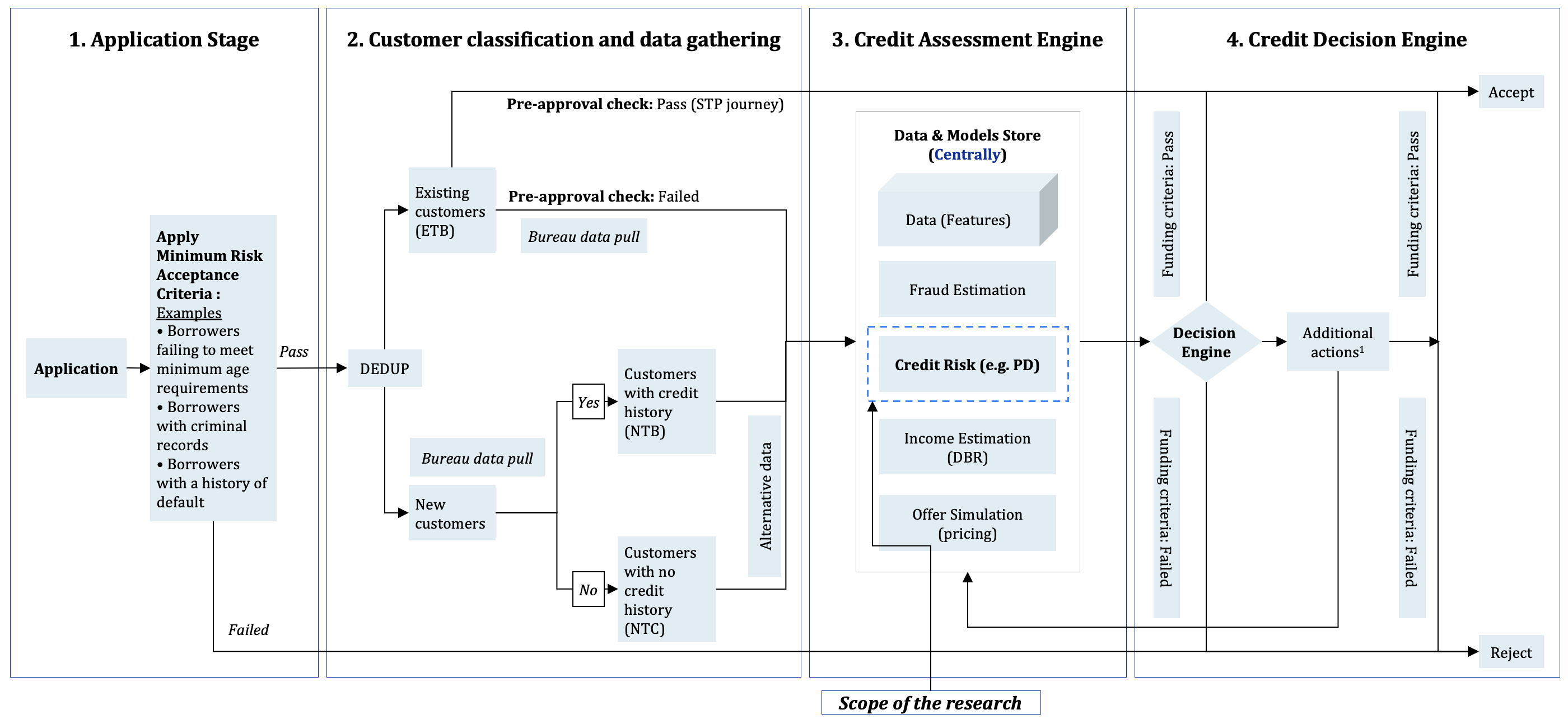
Federated Survival Learning (FSL) is a distributed machine learning approach that combines the data privacy benefits of federated learning with the predictive capabilities of survival analysis. Traditional machine learning often requires centralizing data, which is problematic for sensitive datasets like those found in healthcare or finance. FSL addresses this by training a shared model across multiple decentralized devices or institutions – each retaining local data. Instead of exchanging raw data, only model updates – specifically, gradients calculated from local datasets – are shared. This preserves data privacy while allowing for collaborative learning. The integration of survival analysis extends predictive modeling beyond simple classification or regression to estimate the time-to-event, such as loan default or patient survival, providing a more nuanced and informative risk assessment than standard predictive models.
Traditional binary classification models in default prediction output a simple prediction of whether a borrower will default, lacking granularity regarding when default might occur. Federated Survival Learning addresses this limitation by incorporating survival analysis techniques, which model the time-to-event – in this case, the time until default. This approach utilizes functions like the Kaplan-Meier estimator and Cox proportional hazards model to estimate the default probability distribution over time. Consequently, the system generates a comprehensive risk profile that details the probability of default at various future time points, enabling more informed and precise risk assessment compared to binary outcomes and facilitating interventions tailored to the predicted time of potential default.
Bayesian Differential Privacy (BDP) is integrated into the federated learning framework to protect individual client data during model training. Unlike traditional differential privacy which adds noise to the model updates, BDP utilizes a Bayesian approach to quantify and control the privacy loss. This involves defining a prior distribution over the model parameters and updating it based on the observed data, ensuring that the posterior distribution remains relatively insensitive to changes in any single client’s data. Specifically, the privacy loss is measured using the α-Renyi divergence, allowing for a tunable privacy parameter ε to balance privacy and model utility. The implementation involves adding calibrated noise to the gradients during the local update steps and aggregating these noisy updates at the central server, effectively masking individual contributions while still enabling effective model convergence.
Validation and Performance: Quantifying Predictive Power
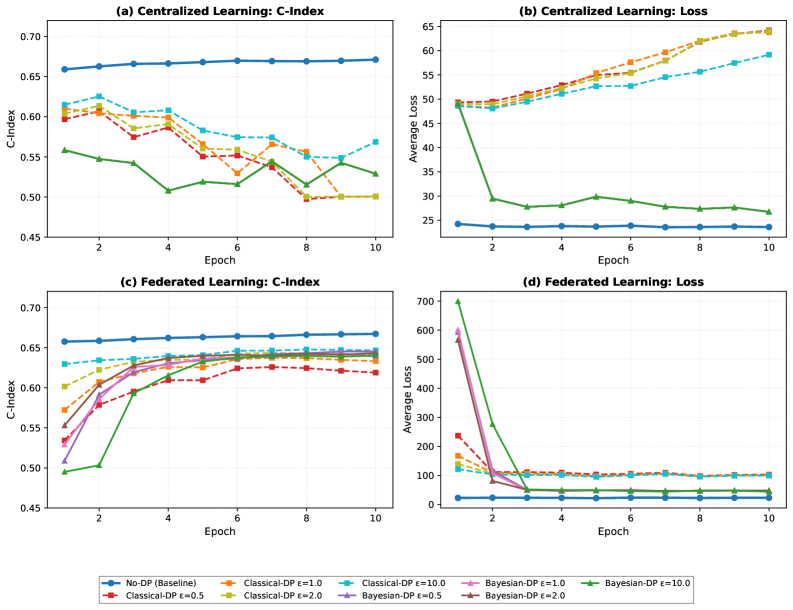
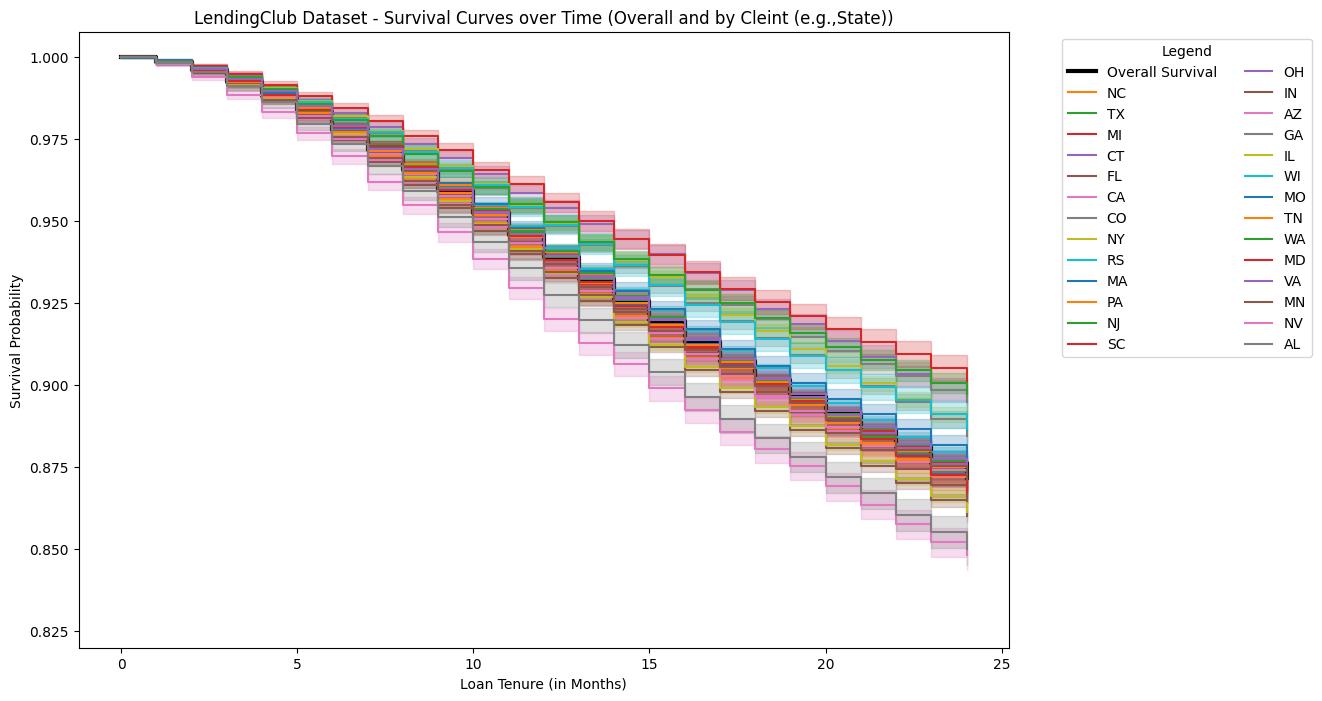
Model performance was rigorously evaluated using the Concordance Index (C-index) and Integrated Brier Score (IBS). The C-index, ranging from 0.5 to 1.0, assesses the model’s ability to correctly rank individuals based on their predicted survival times, with higher values indicating better discriminatory power. The IBS, calculated as the area under the Brier curve, quantifies the calibration of the model’s probability predictions; lower IBS values denote improved calibration. Across multiple datasets, Federated Survival Learning consistently achieved statistically significant improvements in both the C-index and IBS compared to centralized and differentially private baselines, demonstrating its superior predictive capabilities and reliable probability estimates.
Model validation was conducted using three distinct datasets representing different lending ecosystems: LendingClub, a peer-to-peer lending platform; the SBA Loan Program, encompassing loans guaranteed by the U.S. Small Business Administration; and Bondora, a European online lending platform. This multi-dataset approach was specifically designed to assess the model’s generalizability and performance consistency across varying data distributions, loan characteristics, and borrower demographics. Successful validation across these diverse platforms demonstrates the framework’s ability to adapt and maintain predictive accuracy beyond a single, isolated dataset, indicating its potential for broad applicability in the financial lending domain.
Gradient Clipping is implemented as a regularization technique to address training instability commonly encountered with federated learning, especially when dealing with non-IID (heterogeneous) data distributions across clients. This technique involves limiting the magnitude of the gradients during the backpropagation step, preventing excessively large updates that can disrupt the training process. By clipping gradients to a pre-defined threshold, the algorithm reduces the risk of divergence and enhances model robustness against outliers or noisy data present in individual client datasets. This stabilization is crucial for ensuring consistent performance and convergence across the federated network, ultimately improving the overall model quality and reliability.
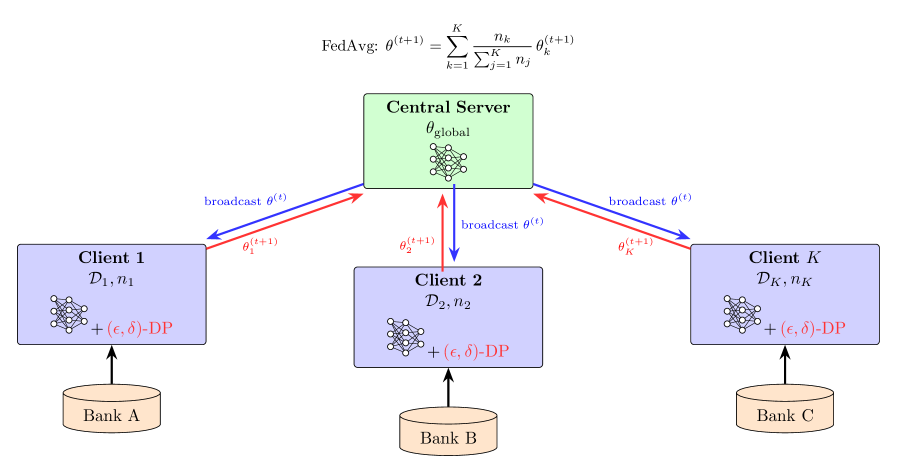
The proposed federated learning framework demonstrates a 7.0% average performance improvement compared to implementations utilizing Classical Differential Privacy (DP) when transitioning from centralized to federated training. This improvement indicates a more favorable privacy-utility trade-off, meaning the model maintains a higher level of predictive accuracy while incorporating privacy-preserving mechanisms. The performance gain was consistently observed across multiple datasets, suggesting the framework effectively mitigates the accuracy loss often associated with applying DP in a federated learning setting.
The implementation of a Bayesian Differential Privacy (DP) approach within the federated learning framework yields a 1.4% performance improvement compared to Classical DP when transitioning from centralized training to a federated learning environment. This improvement is measured using established metrics for predictive accuracy, such as the Concordance Index and Integrated Brier Score, across multiple datasets including LendingClub, SBA Loan Program, and Bondora.
Evaluation of the federated learning framework across the LendingClub, SBA Loan Program, and Bondora datasets resulted in a 39 out of 62 client win rate. This indicates that, when compared to a centralized training baseline, the federated model demonstrated improved performance on 62.9% of the tested clients. Statistical significance was confirmed via binomial testing, yielding a p-value of < 0.028, supporting the claim of a consistent performance advantage across diverse lending platforms and client configurations.
Statistical significance was assessed using binomial testing to evaluate the framework’s performance advantage across clients. The resulting p-value of < 0.028 indicates that the observed win rate of 39 out of 62 clients is unlikely to have occurred by chance. This threshold satisfies conventional significance levels, providing strong evidence that the framework consistently outperforms baseline methods across the tested datasets and lending platforms. The binomial test was chosen due to the binary nature of the performance comparison – a client either demonstrates improved performance with the framework or does not.
Towards Robust and Ethical AI: The Future of Financial Risk Management
The calculation of Lifetime Expected Credit Loss (LCL) is a cornerstone of modern financial risk management, mandated by regulations such as IFRS 9 and Basel III to ensure banks adequately prepare for potential losses. Federated Survival Learning emerges as a powerful technique to address this need, enabling accurate LCL estimation without requiring centralized access to sensitive customer data. This approach allows financial institutions to collaboratively train models on decentralized datasets, preserving data privacy while still leveraging the collective intelligence needed for robust risk assessment. By distributing the learning process, the framework not only enhances regulatory compliance but also unlocks the potential for more precise and reliable credit loss predictions, ultimately contributing to a more stable and resilient financial system.
The efficacy of artificial intelligence in financial lending hinges on the quality and representativeness of the data used for training; however, datasets across financial institutions are inherently diverse, a phenomenon known as data heterogeneity. This approach directly tackles this challenge, enabling models to generalize better across different populations and economic conditions. By accommodating variations in data distributions – stemming from differing customer bases, geographical locations, or lending practices – the system significantly enhances predictive accuracy and reduces bias. Consequently, this fosters a more equitable and responsible application of AI in lending, minimizing the risk of discriminatory outcomes and ensuring fairer access to credit for a broader range of applicants. The resulting models aren’t simply more accurate, but also demonstrably fairer, aligning with growing regulatory scrutiny and ethical considerations surrounding algorithmic decision-making in the financial sector.
Continued development of this framework prioritizes enhanced data privacy through the integration of techniques like Rényi Differential Privacy, a method offering tunable privacy loss and improved utility compared to traditional approaches. This expansion isn’t limited to credit risk; researchers intend to investigate the framework’s adaptability to other critical areas of financial risk modeling, including operational risk and market risk. Successfully extending the approach beyond Lifetime Expected Credit Loss promises a more holistic and resilient AI-driven risk management system, capable of navigating complex financial landscapes while upholding stringent privacy standards and regulatory compliance. The ultimate goal is a versatile, ethically sound AI that enhances financial stability and fosters trust in automated decision-making processes.
The pursuit of collaborative risk modeling, as detailed in this framework, isn’t simply about aggregating data – it’s about dismantling the traditional silos that have long constrained financial institutions. This approach, utilizing federated learning and Bayesian differential privacy, embodies a systematic deconstruction of centralized data dependency. Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” This rings true; the model doesn’t create risk insights, it meticulously executes the logic programmed into it – a logic now distributed and secured through privacy-preserving techniques. The brilliance lies not in invention, but in the precise articulation of a problem and the skillful orchestration of a solution, mirroring the engine’s capacity for complex calculation when properly instructed. It’s a reverse-engineering of trust, building confidence not through data control, but through mathematically-guaranteed privacy.
What’s Next?
The pursuit of decentralized risk modeling, as demonstrated by this framework, inevitably bumps against the inherent tension between utility and privacy. Bayesian differential privacy offers a quantifiable defense, yet the calibration of that defense-the epsilon-delta dance-remains a pragmatic compromise, not a philosophical resolution. Future work will undoubtedly focus on tightening those bounds, perhaps through more sophisticated noise injection mechanisms or a deeper understanding of the information leakage inherent in survival analysis itself.
However, the truly interesting cracks will appear not in the privacy guarantees, but in the assumptions underpinning the models. Federated learning merely distributes the problem; it doesn’t solve it. The core challenge remains: accurately predicting default events, which are, by their nature, rare and often driven by unpredictable systemic shocks. The best hack is understanding why it worked – and this framework, while statistically sound, still relies on historical data reflecting a specific, potentially obsolete, economic landscape.
Consequently, the next iteration isn’t simply about better privacy or more efficient training. It’s about incorporating causal inference-moving beyond correlation to understand the mechanisms of default. Every patch is a philosophical confession of imperfection. The ultimate goal isn’t a perfect model, but a system that gracefully degrades in the face of the inevitable unknown.
Original article: https://arxiv.org/pdf/2601.11134.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- What is Omoggle? The AI face-rating platform taking over Twitch
- Elden Ring Is Back With A New Free Game, Thanks To The Fans
- Audible opens first ‘bookless bookstore’ in New York
- 10 Adorable Quotes from Diana in Pragmata
- Wartales Curse of Rigel DLC Guide – Best Tips, POIs & More
- INJ/USD
- Below Deck Down Under Recap: Battle of the Egos
- 10 Classic 2000s Anime That Aren’t As Good As You Remember
- Alix Earle vs Alex Cooper Makes It to 30 Rock
2026-01-20 03:48