Author: Denis Avetisyan
Researchers have developed a framework that learns the governing equations of complex, changing systems in real time, even with incomplete information.
A Bayesian Regression-Based Symbolic Learning method unifies interpretability and uncertainty quantification for online identification of nonlinear time-varying systems.
Achieving both interpretable models and robust uncertainty quantification remains a central challenge in system identification. Addressing this, our work, ‘Online identification of nonlinear time-varying systems with uncertain information’, introduces a novel Bayesian Regression-based Symbolic Learning (BRSL) framework for real-time discovery of governing equations in dynamic systems. By unifying sparse Bayesian inference with symbolic regression, BRSL enables simultaneous system identification, uncertainty quantification, and online adaptation with provable convergence. Could this approach unlock more reliable and transparent digital twins for complex cyber-physical systems and predictive maintenance?
The Inevitable Drift: Modeling Dynamic Systems in a Changing World
Digital twin technology promises revolutionary advancements in optimizing and controlling complex systems – from manufacturing processes and smart cities to personalized healthcare and energy grids. However, the efficacy of a digital twin is fundamentally linked to the fidelity of its underlying model. A static or inaccurate representation of the physical asset limits the twin’s ability to predict behavior, diagnose issues, or propose effective interventions. Consequently, these virtual counterparts require models that not only capture the initial characteristics of the system but also continuously adapt to reflect changes in operational conditions, environmental factors, and component degradation. This demand for dynamic accuracy underscores the need for sophisticated modeling techniques capable of learning and evolving alongside their physical counterparts, ensuring the digital twin remains a reliable and insightful representation throughout the system’s lifecycle.
Conventional system identification techniques, while foundational, frequently encounter difficulties when applied to the intricate and noisy data characteristic of real-world systems. These methods typically demand batch processing of data – a complete dataset must be collected before model parameters can be estimated – which proves inefficient and often necessitates periodic re-estimation as system dynamics evolve. This reliance on offline analysis creates a significant bottleneck for applications requiring real-time performance, such as adaptive control or predictive maintenance. The computational burden associated with frequent re-estimation further exacerbates the problem, limiting the ability to respond promptly to changing conditions and potentially compromising system stability or effectiveness. Consequently, a shift towards methodologies capable of continuous, incremental learning is crucial to unlock the full potential of model-based optimization and control.
The escalating complexity of modern systems, coupled with the increasing volume of real-time data, is driving a critical need for continuous learning capabilities within digital twin technology. Traditional system identification, typically performed offline on static datasets, proves inadequate for dynamic environments where conditions are constantly evolving. Consequently, research is heavily focused on developing online methods – algorithms that can incrementally update system models as new data streams in. These approaches allow digital twins to adapt to changing circumstances, maintain accuracy over extended periods, and ultimately, provide more reliable predictions and control actions. The ability to learn and refine models continuously is no longer a desirable feature, but a fundamental requirement for deploying effective digital twins in real-world applications, particularly those involving complex, time-varying processes.
Uncovering Governing Principles: A Bayesian Approach to Symbolic Learning
Bayesian Regression for Symbolic Learning (BRSL) offers a data-driven method for constructing governing equations by directly learning relationships from observed data. Unlike traditional regression techniques, BRSL prioritizes model parsimony, meaning it automatically identifies and retains only the most influential terms within the equation, effectively simplifying the model while maintaining accuracy. This is achieved through Bayesian inference, which provides a probabilistic framework for estimating model parameters and quantifying uncertainty. The resulting models are inherently interpretable, as the retained terms directly correspond to physically meaningful variables and their interactions, facilitating understanding of the underlying system dynamics and enabling predictive capabilities based on a concise representation of the data.
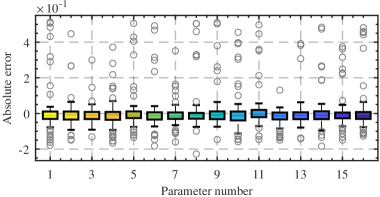
The methodology employs Bayesian inference coupled with a Horseshoe prior to achieve model sparsity. The Horseshoe prior facilitates the identification of significant model terms by shrinking the coefficients of less important terms towards zero, effectively performing feature selection during the regression process. Simulations have demonstrated a high degree of precision in estimating true parameter values when approximately 30% of the parameters are non-zero, indicating the model’s ability to accurately recover the underlying relationships within the data while mitigating the risk of overfitting. This is achieved through the posterior distribution induced by the Horseshoe prior, which provides a probabilistic measure of parameter importance.
This Bayesian regression framework builds upon Sparse Identification of Nonlinear Dynamics (SINDy) by incorporating a probabilistic approach to model selection and parameter estimation. Unlike traditional SINDy which often relies on thresholding or regularization techniques, this method utilizes Bayesian inference with a Horseshoe prior to directly induce sparsity, allowing for automatic determination of relevant terms in the governing equations. Furthermore, the integration of Recursive Least Squares (RLS) facilitates efficient online parameter estimation, enabling the model to adapt to streaming data and update its parameters incrementally without requiring full retraining from scratch. This combination of Bayesian sparsity and RLS provides a computationally efficient and statistically rigorous approach to learning dynamic models from data.
Accounting for the Inevitable: Uncertainty Quantification and Adaptive Stability
Uncertainty Quantification (UQ) is a critical component of reliable prediction in dynamic systems, particularly those deployed in safety-critical applications such as aerospace, autonomous vehicles, and medical devices. UQ methods move beyond point estimates to provide a probabilistic characterization of model predictions, acknowledging and representing the inherent uncertainties arising from limited data, model inaccuracies, and noisy measurements. This probabilistic output, often expressed as confidence intervals or probability distributions, allows for a more informed assessment of risk and enables decision-making that accounts for potential failures or unexpected behaviors. Techniques employed in UQ range from statistical methods like Monte Carlo simulation and Bayesian inference to more advanced approaches involving ensemble modeling and sensitivity analysis, all aimed at providing a robust and trustworthy estimate of prediction reliability.
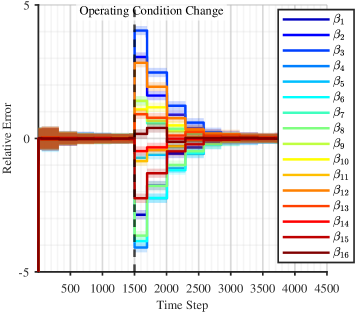
Convergence analysis within adaptive systems relies on the principle of Persistent Excitation (PE) to ensure algorithm stability and long-term performance. PE dictates that the regressor vector, z(t), must exhibit sufficient linear independence over time; specifically, the integral from 0 to t of z(t)z(t)^T must be positive definite. This condition guarantees that the algorithm’s parameter estimates will converge to a finite value, preventing unbounded oscillations or divergence. Without PE, the learning algorithm may become stuck in suboptimal solutions or fail to track time-varying system dynamics, rendering it ineffective for control or prediction tasks. The strength of the excitation directly impacts the rate of convergence; stronger excitation generally leads to faster adaptation, but can also increase sensitivity to noise.
The forgetting factor, denoted as λ, within a recursive least squares (RLS) or similar adaptive filtering algorithm, controls the trade-off between tracking current data and preserving past information. A value of \lambda = 1 equates to a standard least squares solution, giving equal weight to all observations. Values between 0 and 1 introduce a weighting that exponentially decays the influence of older data, enabling the algorithm to adapt to non-stationary environments. Specifically, the influence of a data point from k time steps ago is reduced by a factor of \lambda^k. This mechanism is critical for tracking time-varying systems, as it allows the model to prioritize recent information while still leveraging the stability provided by historical data, preventing excessive sensitivity to noise or temporary fluctuations.
Demonstrating Resilience: Validation and Interpretability Through the Lorenz System
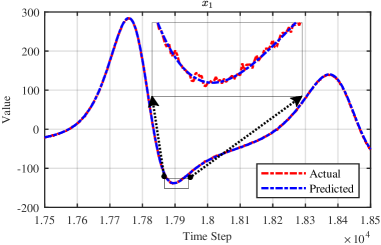
The Lorenz system, a cornerstone in chaos theory and a notoriously difficult problem for nonlinear system identification, served as a critical test case for this research. Researchers represented the system using a StateSpaceModel, a mathematical framework allowing for the dynamic relationships within the Lorenz attractor to be explicitly modeled. This approach enabled the application of novel learning techniques to uncover the underlying principles governing the system’s complex, seemingly unpredictable behavior. By framing the challenge in this manner, the study successfully transitioned from theoretical possibility to practical demonstration, paving the way for applying these methods to other complex dynamical systems encountered in scientific and engineering disciplines.
The efficacy of the learned model was demonstrated through its precise prediction of the Lorenz system’s future states, a hallmark of successful nonlinear dynamic modeling. Rigorous verification involved simulations performed under challenging conditions, specifically within complex, noisy environments designed to mimic real-world uncertainties. These simulations confirmed the model’s robust ability to accurately track system states despite the presence of disruptive noise, indicating a high degree of resilience and generalization capability. This successful tracking wasn’t merely a static snapshot; the model dynamically mirrored the Lorenz system’s chaotic behavior, successfully forecasting its evolution over extended periods and affirming its capacity to capture the underlying dynamics of this notoriously sensitive system.
The efficacy of the learned StateSpaceModel extends beyond predictive accuracy, demonstrated through the application of SHAP (SHapley Additive exPlanations) values. This approach facilitated a detailed examination of feature importance, revealing which variables most strongly influenced the Lorenz system’s chaotic behavior. By quantifying each feature’s contribution to specific predictions, SHAP values provided a transparent understanding of the model’s decision-making process. This level of interpretability is crucial for establishing trust in complex systems, allowing researchers to validate not just what the model predicts, but how it arrives at those predictions, and confirming alignment with known physical principles governing the Lorenz attractor. Consequently, SHAP values served as a powerful tool for model debugging, refinement, and ultimately, increasing confidence in the learned representation of the system’s dynamics.
The pursuit of identifying nonlinear time-varying systems, as detailed in this work, echoes a fundamental truth about all constructed models. Every attempt to capture dynamic systems-whether through Bayesian Regression-Based Symbolic Learning or any other method-is a temporary bulwark against inevitable decay. As Ken Thompson observed, “Software is like entropy: It is difficult to stop it from spreading.” This framework, with its emphasis on uncertainty quantification and provable convergence, doesn’t promise to halt that spread, but rather offers a means to understand and adapt to it – a graceful aging process for the digital twins it seeks to create. The ability to recursively estimate governing equations acknowledges the transient nature of these models, striving for robustness not through static perfection, but through continuous learning and refinement.
What Lies Ahead?
The pursuit of identifying dynamic systems, particularly those nonlinear and time-varying, reveals a familiar pattern. Each refinement in estimation, each attempt to quantify uncertainty, simply exposes the next layer of complexity. This work, with its Bayesian Regression-Based Symbolic Learning framework, does not erase this truth, but rather accepts it. Systems learn to age gracefully; their governing equations are not static truths to be discovered, but rather transient descriptions valid within specific operational regimes. The framework’s strength lies not in a promise of perfect identification, but in a principled approach to acknowledging and propagating the inherent unknowns.
Future efforts will likely focus on the limits of interpretability. As models grow more complex-attempting to capture increasingly subtle dynamics-the symbolic representations themselves may become intractable. The question then shifts: is a perfectly interpretable, yet inaccurate, model preferable to a black box that more faithfully reflects the system’s behavior? Sometimes observing the process-the evolution of uncertainty, the adaptation to changing conditions-is better than trying to speed it up.
Ultimately, the value of such research may not reside in achieving definitive answers, but in developing tools to navigate the inevitable decay of knowledge. The digital twin, often touted as a perfect replica, is more accurately a continually evolving approximation, and the art lies in understanding how it diverges from reality, not in pretending it doesn’t.
Original article: https://arxiv.org/pdf/2601.10379.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- DoorDash responds after customer uses AI to make food look bad and get a refund
- HSR Banner Schedule (Honkai Star Rail)
- Hideo Kojima says Metal Gear Solid 2 became the future he hoped would not happen
- Gold Rate Forecast
- 10 Most Universally Beloved Sci-Fi Movie Villains, Ranked
- Umamusume has been transformed into a D&D game with new race
- Euphoria Season 3’s New R-Rated Sydney Sweeney Scene Proves The Show Is Trolling Us
- Jon Bernthal Explains Why Marvel Let Him Make The Darkest Punisher Story Ever
- Ethereum Eyes Break Above $2,420 as Rally Hangs in the Balance
2026-01-17 22:10