Author: Denis Avetisyan
A new study reveals that even finely-tuned language models can be surprisingly vulnerable to phishing attacks, highlighting critical weaknesses in how these systems learn to identify malicious content.

Researchers investigated generalization failures in large language models for phishing detection, finding that data diversity and noisy training examples significantly impact performance and can be diagnosed using interpretability methods like SHAP and attention analysis.
Despite the demonstrated success of fine-tuned Large Language Models (LLMs) on specialized tasks, their propensity for brittle generalization remains a critical challenge. This is explored in ‘Diagnosing Generalization Failures in Fine-Tuned LLMs: A Cross-Architectural Study on Phishing Detection’, which investigates the root causes of these failures through a comparative analysis of Llama, Gemma, and Mistral models applied to phishing detection. Our findings reveal that generalization is fundamentally driven by the synergy between architectural properties and data diversity, with certain models exhibiting inherent robustness while others struggle to integrate diverse information. Ultimately, understanding these nuanced interactions is crucial – can we develop systematic validation strategies to ensure reliable AI performance beyond narrow training domains?
The Illusion of Intelligence: Unmasking Fragility in Language Models
Despite their remarkable ability to generate human-quality text and perform complex linguistic tasks, Large Language Models (LLMs) frequently stumble when confronted with data differing significantly from their training sets. This susceptibility to generalization failure isn’t a matter of simply lacking knowledge, but rather a fragility in their learned representations; LLMs excel at identifying and replicating patterns, yet struggle to extract underlying principles. Consequently, even subtle shifts in input distribution – a change in writing style, the introduction of uncommon terminology, or a variation in topical focus – can trigger unexpected errors and degrade performance. This limitation highlights a critical gap between statistical proficiency and genuine understanding, suggesting that current LLMs often operate as sophisticated pattern-matchers rather than robust reasoning engines capable of adapting to genuinely novel situations.
Though initially promising, standard fine-tuning frequently yields language models that are surprisingly fragile. While these models can rapidly adapt to a specific dataset, their performance degrades substantially when confronted with even slight variations in input-a phenomenon known as domain shift. This brittleness arises because fine-tuning often encourages the model to memorize superficial correlations within the training data rather than develop a deeper understanding of underlying principles. Consequently, these models are easily fooled by adversarial text-carefully crafted inputs designed to exploit these memorized patterns-revealing a lack of genuine reasoning ability. The result is a model that excels in controlled environments but struggles with the messiness and unpredictability of real-world applications, highlighting a critical limitation in current adaptation techniques.
The apparent intelligence of large language models frequently masks a fundamental weakness: a tendency to prioritize superficial correlations over genuine understanding. Current models often succeed by identifying patterns in training data – recognizing, for example, that certain phrases commonly precede specific answers – rather than developing a robust capacity for reasoning. This reliance on surface-level cues renders them susceptible to even minor variations in input, or to data that deviates from the training distribution. Consequently, models may perform well on familiar examples, but falter when presented with novel situations demanding genuine inference or problem-solving, highlighting a critical gap between statistical pattern recognition and true cognitive ability.
The performance of large language models is significantly undermined by the prevalence of inaccurate or misleading labels within training datasets, a phenomenon known as label noise. Studies analyzing corpora of Enron emails and phishing attempts reveal error rates ranging from 17 to 22 percent, indicating a substantial proportion of mislabeled data. This noise doesn’t simply reduce accuracy; it actively hinders the model’s ability to generalize to new, unseen examples, fostering brittle behavior and susceptibility to adversarial manipulation. Consequently, even models exhibiting strong performance on clean datasets struggle to maintain reliability when deployed in real-world applications where imperfect data is the norm, limiting their practical utility and demanding robust methods for noise detection and mitigation.

Beyond Superficial Adaptation: Strategies for Robust Intelligence
Data augmentation techniques artificially increase the size of a training dataset by creating modified versions of existing data points. These modifications can include transformations such as rotations, translations, scaling, noise injection, and color adjustments for image data, or back-translation, synonym replacement, and random insertion/deletion for text. The primary goal is to improve a model’s ability to generalize to unseen data by exposing it to a wider range of variations. By increasing the diversity of the training set, data augmentation reduces overfitting and enhances robustness to common variations encountered during deployment, ultimately leading to improved performance on real-world tasks without requiring the collection of additional labeled data.
Curriculum Learning (CL) is a training strategy that orders examples based on difficulty, presenting easier examples to the model initially and progressively increasing complexity. This approach contrasts with standard training, which typically uses a randomly shuffled dataset. The rationale behind CL is that learning simpler concepts first provides a stronger foundation for mastering more complex ones, improving generalization and reducing overfitting. Difficulty can be determined by various metrics, including loss value on a held-out set, example length, or manually defined criteria. Empirical results demonstrate that CL can enhance model performance, particularly in scenarios with limited data or noisy labels, and has been successfully applied to tasks including machine translation, image recognition, and reinforcement learning.
Domain-Adaptive Pre-training addresses the performance decline observed when deploying models into environments differing from their training data by utilizing unlabeled data representative of the target deployment domain. This technique involves continuing the pre-training phase – typically performed on a large, general corpus – but now with data sourced specifically from the intended application environment. By exposing the model to the statistical characteristics of the target domain before fine-tuning on labeled task-specific data, the model learns feature representations more aligned with real-world inputs. This pre-training step adjusts the model’s internal parameters to better handle the nuances of the deployment distribution, effectively reducing the distribution gap and improving generalization performance without requiring labeled data from the target domain.
QLoRA, or Quantized Low-Rank Adapters, is a parameter-efficient fine-tuning technique that reduces memory requirements by quantizing the pre-trained language model to 4-bit precision. This quantization is coupled with the introduction of low-rank adapter layers, which are significantly smaller than the original model parameters. During fine-tuning, only these adapter layers are updated, while the quantized base model remains frozen. This approach dramatically reduces the number of trainable parameters – often by over 90% – enabling adaptation of large language models on consumer-grade hardware and minimizing computational costs without substantial performance degradation compared to full fine-tuning.
Evidence from the Trenches: Evaluating Resilience on Realistic Data
Evaluation of Mistral, Gemma 2 9B, and Llama 3.1 8B utilized standard fine-tuning techniques, involving the adaptation of pre-trained language models to specific datasets. This process involved updating model weights using a labeled dataset and an optimization algorithm, such as AdamW, with parameters including learning rate, batch size, and number of epochs. The fine-tuning procedure aimed to minimize a loss function – typically cross-entropy – calculated on the training data, enabling the models to better perform the target task of email classification. Consistent application of these standard techniques ensured a fair comparative analysis of model performance across different email corpora.
Model performance was evaluated using three publicly available datasets representing diverse email communication patterns and security threats. The SpamAssassin Corpus provides a collection of unsolicited bulk email, commonly used for identifying spam filtering techniques. The Enron Corpus, comprised of emails from a large corporate dataset, offers a realistic representation of internal business communication. Finally, the Modern Phishing Corpus consists of contemporary phishing emails, reflecting current tactics employed by malicious actors. Utilizing these three corpora allowed for a comprehensive assessment of each LLM’s ability to generalize across varying email styles – from formal business correspondence to informal spam – and to detect threats within different and evolving threat landscapes.
Comparative evaluation of Large Language Models on a combined Generalist test set – consisting of the SpamAssassin, Enron, and Modern Phishing Corpora – indicates that Gemma 2 9B achieved a superior F1 score of 0.9132. This result surpasses the performance of Llama 3.1 8B when configured as a Specialist model, suggesting that a generalist approach to LLM training can yield more robust performance across diverse email datasets and threat profiles. The F1 score, a harmonic mean of precision and recall, provides a balanced measure of the model’s ability to accurately identify both spam and legitimate emails.
SHAP (SHapley Additive exPlanations) values were calculated to interpret the output of the Large Language Models used in this analysis. This method assigns each feature an importance value for a particular prediction, representing its contribution to the deviation from the base value. By analyzing these values, key features influencing model classifications – such as the presence of specific keywords, email header characteristics, or URL patterns – were identified. This feature attribution provides transparency into model decision-making processes and enables understanding of why a given email was classified as spam or phishing, rather than simply that it was classified as such. The resulting insights facilitate model debugging, refinement, and trust-building.

Beyond Peak Performance: Implications and Future Directions for Resilient AI
Current artificial intelligence development often prioritizes achieving peak performance on curated benchmark datasets, yet recent findings demonstrate a concerning disconnect between this performance and real-world applicability. The observed vulnerabilities reveal that models frequently excel at recognizing superficial patterns within these datasets while failing to generalize to slightly altered or novel inputs. This necessitates a fundamental shift in focus; the emphasis must move from solely maximizing accuracy on static benchmarks toward building systems capable of robust generalization. True resilience demands models that understand underlying principles, rather than simply memorizing training examples, enabling them to adapt and perform reliably in the face of unforeseen circumstances and the inherent complexities of real-world data.
Mixture of Experts (MoE) architectures represent a significant departure from traditional monolithic neural networks, offering a pathway to more robust artificial intelligence. Instead of relying on a single, all-encompassing model, MoE systems employ multiple “expert” sub-models, each specializing in a particular subset of the input data. A “gating network” intelligently routes each input to the most relevant expert, allowing the system to handle a diverse range of scenarios with greater precision and resilience. This specialization not only improves performance on known data but also enhances generalization to unseen inputs, as the system isn’t forced to awkwardly fit all data into a single, rigid framework. The modular nature of MoE architectures further facilitates scalability and adaptation, potentially allowing for the seamless integration of new expertise as it becomes available – a crucial attribute for AI operating in dynamic, real-world environments.
Chain-of-Thought (CoT) fine-tuning represents a significant advancement in fostering more robust reasoning within artificial intelligence. This technique moves beyond simply training models to predict outputs based on input data; instead, it encourages the model to explicitly generate a series of intermediate reasoning steps – a ‘thought process’ – before arriving at a final answer. By learning to articulate these steps, the model is less reliant on recognizing superficial patterns in the training data and more capable of generalizing to novel situations requiring genuine inference. The process essentially forces the AI to explain its reasoning, making it less susceptible to being fooled by cleverly disguised inputs designed to exploit shortcut correlations. Consequently, CoT fine-tuning doesn’t just improve accuracy; it enhances the model’s ability to solve problems in a manner that mirrors human cognitive processes, resulting in a system that is demonstrably more reliable and adaptable.
The development of consistently reliable artificial intelligence necessitates a sustained commitment to refining techniques that bolster performance beyond controlled laboratory settings. Data augmentation, through the creation of synthetic or modified training examples, promises to expand the breadth of scenarios an AI can confidently address. Simultaneously, domain adaptation strategies aim to bridge the gap between training and real-world data distributions, preventing performance degradation when faced with unfamiliar inputs. Crucially, adversarial training-where models are deliberately exposed to carefully crafted deceptive examples-forces them to learn more robust features and resist manipulation. These interconnected research avenues-augmentation, adaptation, and adversarial resilience-are not merely incremental improvements, but foundational steps towards building AI systems capable of navigating the complexities and uncertainties of the real world with consistent and dependable accuracy.
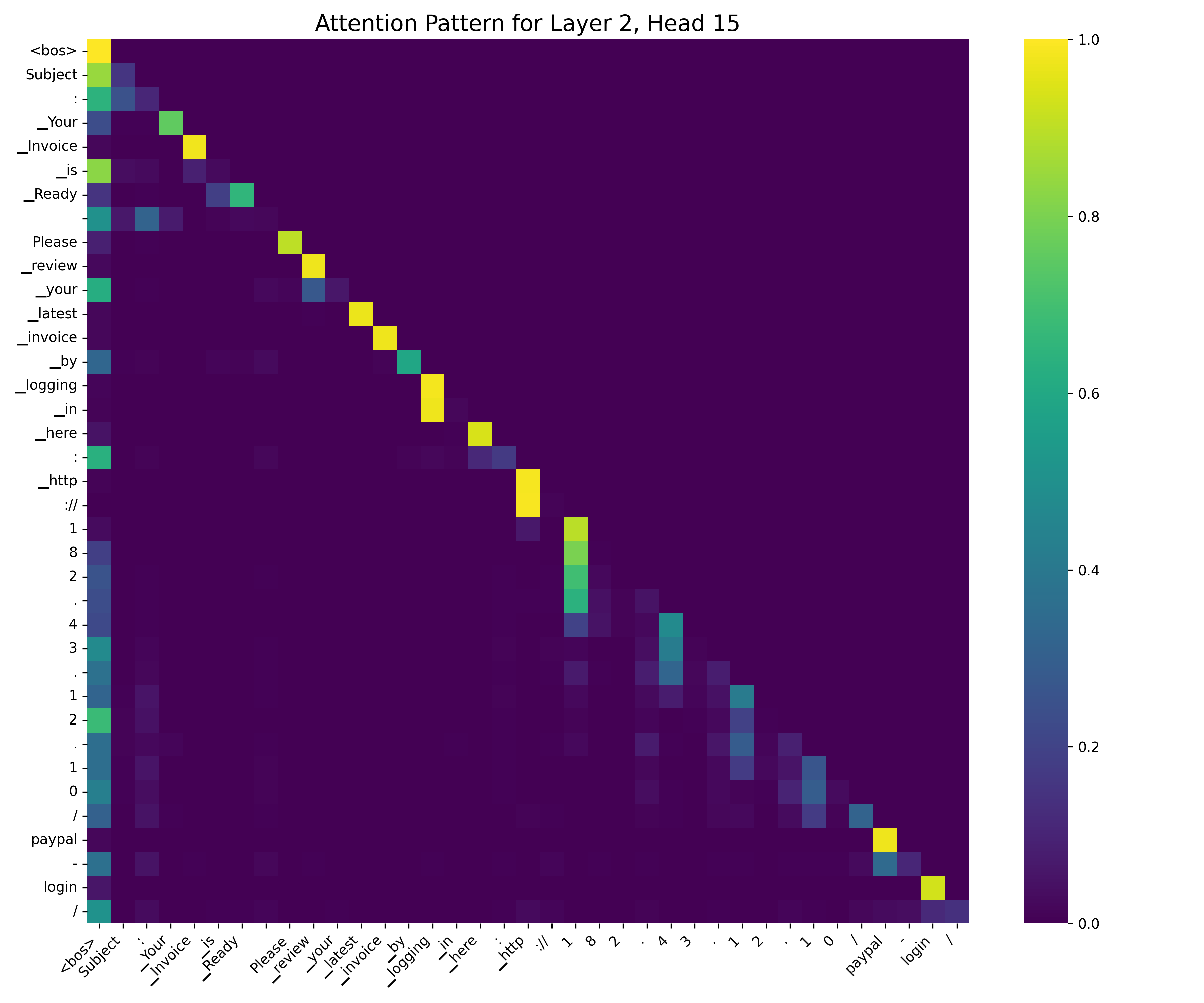
The study reveals a curious paradox: models excel at mimicking patterns but struggle with true understanding. This echoes Alan Turing’s sentiment: “We can only see a short distance ahead, but we can see plenty there that needs to be done.” The research demonstrates that fine-tuned Large Language Models, despite achieving high accuracy on training data, often fail to generalize due to reliance on brittle heuristics learned from noisy datasets. Every exploit starts with a question, not with intent; similarly, every failure in generalization begins with a gap in the model’s underlying comprehension of the task, a gap exposed by insufficient data diversity and revealed through interpretability methods like SHAP analysis. The exploration of attention mechanisms further illustrates how these models ‘see’ only a limited distance ahead, focusing on superficial features rather than robust indicators of malicious intent.
What’s Next?
The pursuit of robust phishing detection via Large Language Models reveals, predictably, that intelligence isn’t simply absorbed from data; it’s painstakingly extracted. This work highlights the fragility of learned heuristics, demonstrating that models often latch onto superficial patterns rather than genuine linguistic indicators of malicious intent. The reliance on data diversity isn’t merely a practical concern, but a fundamental acknowledgment that the signal is buried within a vast ocean of noise. Future investigations should rigorously examine the types of noise most detrimental to generalization – not just quantity, but quality of misinformation.
A compelling avenue lies in actively probing model vulnerabilities. Rather than passively assessing performance on benchmark datasets, researchers must intentionally craft adversarial examples – not to defeat the models, but to map their decision boundaries and reveal the underlying logic, or lack thereof. The interpretability techniques employed here, SHAP and attention analysis, are useful starting points, but represent only a partial view. A deeper understanding requires developing methods to visualize and quantify the confidence with which a model arrives at a decision, recognizing that a seemingly correct answer can be built on a shaky foundation.
Ultimately, the goal isn’t to build a perfect phishing detector, but to create systems that transparently reveal their reasoning. True security isn’t found in opaque complexity, but in the ability to dissect and understand how a decision was reached. This demands a shift in focus – from simply achieving high accuracy to building models that are inherently debuggable, auditable, and, crucially, explainable even when they err.
Original article: https://arxiv.org/pdf/2601.10524.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Off Campus Season 1 Soundtrack Guide
- DoorDash responds after customer uses AI to make food look bad and get a refund
- Euphoria Season 3’s New R-Rated Sydney Sweeney Scene Proves The Show Is Trolling Us
- Jon Bernthal Explains Why Marvel Let Him Make The Darkest Punisher Story Ever
- Gold Rate Forecast
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Oh My God, It’s Her?
- Prime Video Has Officially Found The Next Game Of Thrones
- Law & Order Season 26: Release Date, Story, & Everything We Know
- YouTuber arrested after viral AI bodycam videos spark real police complaints
2026-01-17 12:12