Author: Denis Avetisyan
The EU AI Act aims to regulate high-risk systems, but accurately assessing individual performance becomes complex when multiple equally valid AI models offer differing predictions.
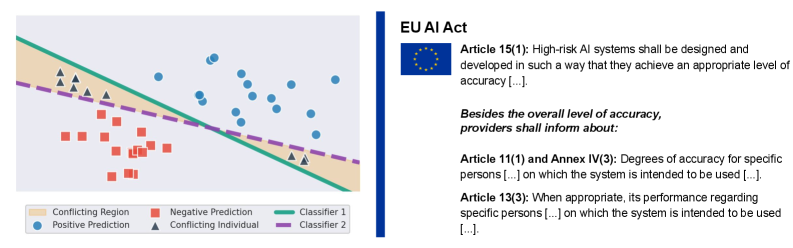
This review explores how ‘predictive multiplicity’ – the existence of multiple accurate but divergent AI predictions – challenges the implementation of the AI Act and necessitates increased transparency in high-risk applications.
A surprising consequence of increasingly accurate machine learning models is that multiple, equally valid predictions can emerge for the same individual case. This phenomenon, known as predictive multiplicity, is the central focus of ‘Using predictive multiplicity to measure individual performance within the AI Act’, where we argue it poses a critical challenge to compliance with the EU AI Act’s requirements for transparency and individual-level accuracy in high-risk systems. We demonstrate that quantifying disagreement between models – using metrics like conflict ratios and δ-ambiguity – is not only legally justifiable under the AI Act but also practically feasible. Will these insights enable deployers to confidently assess the reliability of AI-driven decisions and ensure fairer outcomes for individuals subject to their use?
The Illusion of Consistency: Beyond Simple Accuracy Scores
The pursuit of high statistical accuracy in artificial intelligence frequently overshadows a critical issue: the potential for significant disagreement between models achieving comparable scores. A seemingly robust system, boasting a 95% accuracy rate, might, upon closer inspection, reveal substantial divergence in its predictions on specific instances. This isn’t necessarily a matter of outright error, but rather differing interpretations of the data, leading to inconsistent outcomes despite overall high performance. Such discrepancies are particularly concerning as AI becomes integrated into critical decision-making processes, where even subtle variations in prediction can have substantial consequences. Prioritizing a single, aggregate accuracy score, therefore, can create a misleading impression of reliability, masking underlying unpredictability and the potential for inconsistent application of the technology.
Predictive multiplicity describes a concerning phenomenon in artificial intelligence where several models can attain comparable levels of overall statistical accuracy, yet dramatically disagree on specific instances or predictions. This isn’t merely academic divergence; in high-stakes applications like medical diagnosis or legal assessments, such discrepancies present tangible risks. A model achieving a high average score might consistently fail on a critical subset of cases, while another model excels in those same instances – a pattern obscured by aggregate metrics. Consequently, reliance on overall accuracy alone can foster a false sense of security, masking potentially dangerous inconsistencies and undermining the trustworthiness of AI-driven decisions, particularly when dealing with sensitive or life-altering outcomes.
The reliance on conventional evaluation metrics in artificial intelligence can inadvertently foster a misleading sense of reliability. While a model might achieve a high overall accuracy score, this figure often obscures significant discrepancies in how that accuracy is attained across different instances. These metrics typically provide a singular, aggregated assessment, failing to reveal instances where models consistently disagree on specific cases – a phenomenon known as predictive multiplicity. Consequently, a superficially impressive score can mask underlying instability and potential for wildly inconsistent outcomes, particularly concerning applications where nuanced and reliable predictions are paramount. This creates a critical vulnerability, as decision-makers may place undue trust in a system that, despite its high average performance, is prone to unpredictable errors in certain scenarios, ultimately jeopardizing the integrity of the system’s application.
Defining the Space of Possibilities: Introducing the Rashomon Set
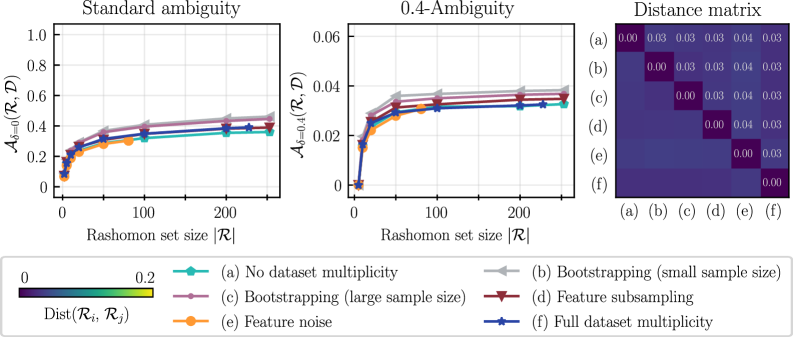
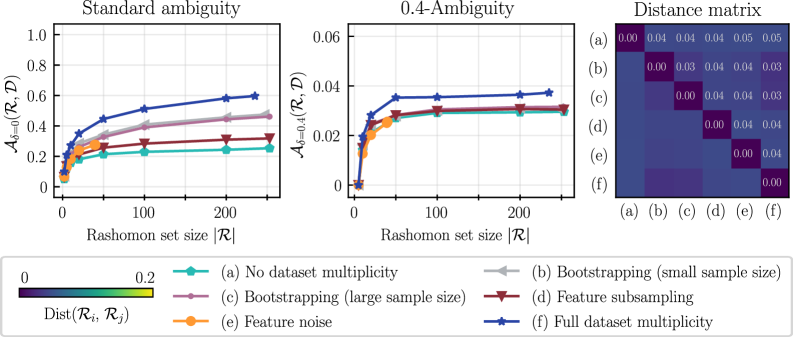
The Rashomon Set addresses the phenomenon of ‘Predictive Multiplicity’ by defining the complete set of models that achieve comparable performance on a given dataset, yet yield differing predictions for individual instances. This set isn’t limited to a single ‘best’ model, but rather encompasses all models within an acceptable error range – typically defined by a chosen performance metric like accuracy or R-squared. The existence of a Rashomon Set demonstrates that, even with high accuracy, predictions aren’t necessarily unique or deterministic, and multiple models can adequately explain the observed data. Quantifying the size and diversity of this set allows for an assessment of the stability and reliability of individual predictions, moving beyond simple point estimates and acknowledging inherent model ambiguity.
The Conflict Ratio, calculated as the number of disagreeing models within the Rashomon Set divided by the total number of models, quantifies the proportion of models making differing predictions for a given input. Delta Ambiguity measures the range of predicted values for a specific feature, calculated as the difference between the maximum and minimum predictions across all models in the Rashomon Set. Both metrics provide a numerical assessment of predictive instability; a high Conflict Ratio indicates substantial disagreement amongst comparably accurate models, while a large Delta Ambiguity signifies considerable variance in individual predictions, suggesting sensitivity to minor changes in model parameters or training data. These values are calculated for each data point, enabling identification of instances where predictions are particularly unreliable or ambiguous.
Low model agreement, as identified through metrics calculated on the Rashomon Set, highlights data instances susceptible to prediction instability. Specifically, data points exhibiting high ‘Conflict Ratio’ or ‘Delta Ambiguity’ indicate scenarios where multiple, comparably accurate models generate divergent outputs. This disagreement doesn’t necessarily imply model error, but rather sensitivity to minor variations in model assumptions or data interpretation. Consequently, these instances warrant further investigation; they may represent edge cases, ambiguous labeling, or areas where additional data collection could substantially improve prediction reliability and reduce overall model uncertainty.
![On the COMPAS dataset with 1212 features, an ad-hoc approach to generating Rashomon sets was compared to TreeFarms[47], revealing comparable performance when training on 4,144 samples and evaluating on 2,763.](https://arxiv.org/html/2602.11944v1/x4.png)
Approximating the Unknowable: Methods for Rashomon Set Analysis
The computational complexity of identifying the complete Rashomon Set – the set of all models that fit training data with comparable performance – often scales exponentially with the number of features and instances. This intractability arises because exhaustive search is required to evaluate all possible model configurations. Consequently, practical applications necessitate the use of approximation techniques that aim to identify a representative subset of the Rashomon Set without guaranteeing completeness. These methods prioritize computational feasibility over exhaustive exploration, accepting a degree of uncertainty in exchange for a manageable runtime and resource consumption. The trade-off between approximation accuracy and computational cost is a central consideration in the selection and implementation of Rashomon Set analysis techniques.
The Ad-hoc approach to Rashomon Set analysis addresses computational intractability by generating a representative subset rather than attempting to compute the complete set. This is achieved through repeated resampling using the bootstrapping technique, which creates multiple datasets from the original. Diverse machine learning algorithms, including XGBoost and Multi-Layer Perceptrons (MLP), are then trained on each bootstrapped dataset. The resulting models, representing a variety of potential solutions, form the approximate Rashomon Set, offering a pragmatic trade-off between computational cost and solution space exploration.
TreeFarms provides a computationally efficient method for determining the complete Rashomon Set specifically for sparse Decision Tree models. This is achieved by establishing inclusion criteria based on objective value and accuracy; models must achieve an objective value of at least 0.6236 and an accuracy of 0.6536 to be included in the set. To manage computational complexity and prevent excessive model proliferation, a penalty of 33 leaf nodes is applied, effectively limiting the size of the generated Rashomon Set while maintaining representational fidelity.
Implications for AI Regulation and High-Risk Systems
The forthcoming European Union’s AI Act establishes a legal framework demanding stringent evaluation of artificial intelligence systems, with a particular emphasis on those categorized as ‘High-Risk’. This legislation recognizes that traditional accuracy metrics offer an incomplete picture of an AI’s reliability, and therefore necessitates a more comprehensive assessment process. High-Risk AI – encompassing applications impacting safety, livelihoods, and fundamental rights – will be subject to rigorous scrutiny before deployment, requiring developers to demonstrate not simply that their systems function, but how they arrive at decisions and to what degree those decisions are dependable across diverse inputs. The Act’s implementation will likely involve standardized testing protocols and independent audits, pushing the field towards greater transparency and accountability in AI development and deployment, ultimately aiming to mitigate potential harms and build public trust.
Traditional accuracy metrics offer a limited view of artificial intelligence system performance, often masking underlying vulnerabilities and potential failure modes. Analyzing the Rashomon Set, however, provides a significantly more nuanced and comprehensive assessment. This approach doesn’t simply determine if a model is correct, but instead identifies multiple plausible solutions – or interpretations – that the model could generate for the same input. The size and composition of this Rashomon Set reveal the degree of ambiguity the AI encounters and highlight areas where slight perturbations in input data could lead to drastically different, and potentially erroneous, outputs. A larger, more diverse Rashomon Set signals a lack of robust understanding, suggesting the AI relies on spurious correlations or superficial features, thereby exposing critical vulnerabilities that standard accuracy tests would miss. This methodology allows for a more granular understanding of model behavior and informs strategies to improve resilience and reliability, particularly crucial for high-risk applications.
Traditional assessments of artificial intelligence often focus solely on whether a model achieves a correct output, neglecting the crucial question of how that conclusion was reached. A more insightful approach involves quantifying the degree of disagreement among multiple models trained on the same data – the Rashomon set – offering a deeper understanding of prediction robustness. This methodology moves beyond a binary ‘accurate/inaccurate’ determination to reveal the underlying reasoning of each model, identifying potential vulnerabilities and biases. Specifically, defining model inclusion within the Rashomon set with an epsilon value of 0.05-a small, quantifiable difference in performance-allows for a precise measurement of disagreement, highlighting models that, while seemingly accurate, may arrive at similar conclusions through vastly different and potentially unreliable pathways. This nuanced evaluation is particularly critical for high-risk AI systems, where understanding the ‘why’ behind a prediction is as important as the prediction itself.
The study’s emphasis on predictive multiplicity and its implications for the AI Act echoes a fundamental principle of systemic design. It posits that a singular, definitive answer – a single ‘accurate’ prediction – may be insufficient, even misleading, when evaluating high-risk AI systems. This resonates with Marvin Minsky’s observation: “You can’t solve problems using the same kind of thinking they were created with.” The Rashomon Set, explored within the paper, exemplifies this – multiple valid solutions highlighting the need for a holistic understanding rather than a search for one ‘correct’ outcome. Infrastructure, in this context, should evolve to accommodate diverse perspectives and varying degrees of accuracy, without necessitating a complete overhaul of the system each time a new prediction emerges.
Beyond the Prediction
The exploration of predictive multiplicity reveals a subtle, yet crucial, point regarding high-risk AI systems: accuracy, while necessary, is demonstrably insufficient. The existence of a ‘Rashomon Set’ of equally valid models forces a reconsideration of evaluation metrics; a single ‘correct’ answer becomes less meaningful when multiple interpretations, all supported by data, are possible. This is not a failure of the technology, but a consequence of its capacity to model complex realities – realities often characterized by inherent ambiguity.
Future work must address the systemic implications of this multiplicity. The current regulatory focus, largely centered on individual model performance, risks treating symptoms rather than the underlying condition. A more holistic architecture is needed – one that accounts for the range of plausible predictions and the potential consequences of each. Simply demanding greater ‘transparency’ feels almost quaint; understanding the structural reasons why multiple models diverge will prove far more valuable than merely knowing that they do.
The AI Act, and similar legislative efforts, may inadvertently incentivize a search for the least ambiguous models, potentially stifling innovation in areas where nuance and contextual understanding are paramount. A system designed to eliminate all uncertainty may, paradoxically, prove less robust in the face of genuinely unpredictable events. The challenge, then, lies in building regulatory frameworks that acknowledge, rather than attempt to erase, the inherent complexities of the systems they seek to govern.
Original article: https://arxiv.org/pdf/2602.11944.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- Gold Rate Forecast
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- How to Solve the Glenbright Manor Puzzle in Crimson Desert
- All Itzaland Animal Locations in Infinity Nikki
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- 8 Actors Who Could Play Blackbeard In One Piece Live-Action Season 3
- All 10 Potential New Avengers Leaders in Doomsday, Ranked by Their Power
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
2026-02-14 14:59