Author: Denis Avetisyan
As AI systems gain agency, understanding and mitigating the evolving threat landscape becomes critical, particularly in safety-critical applications.
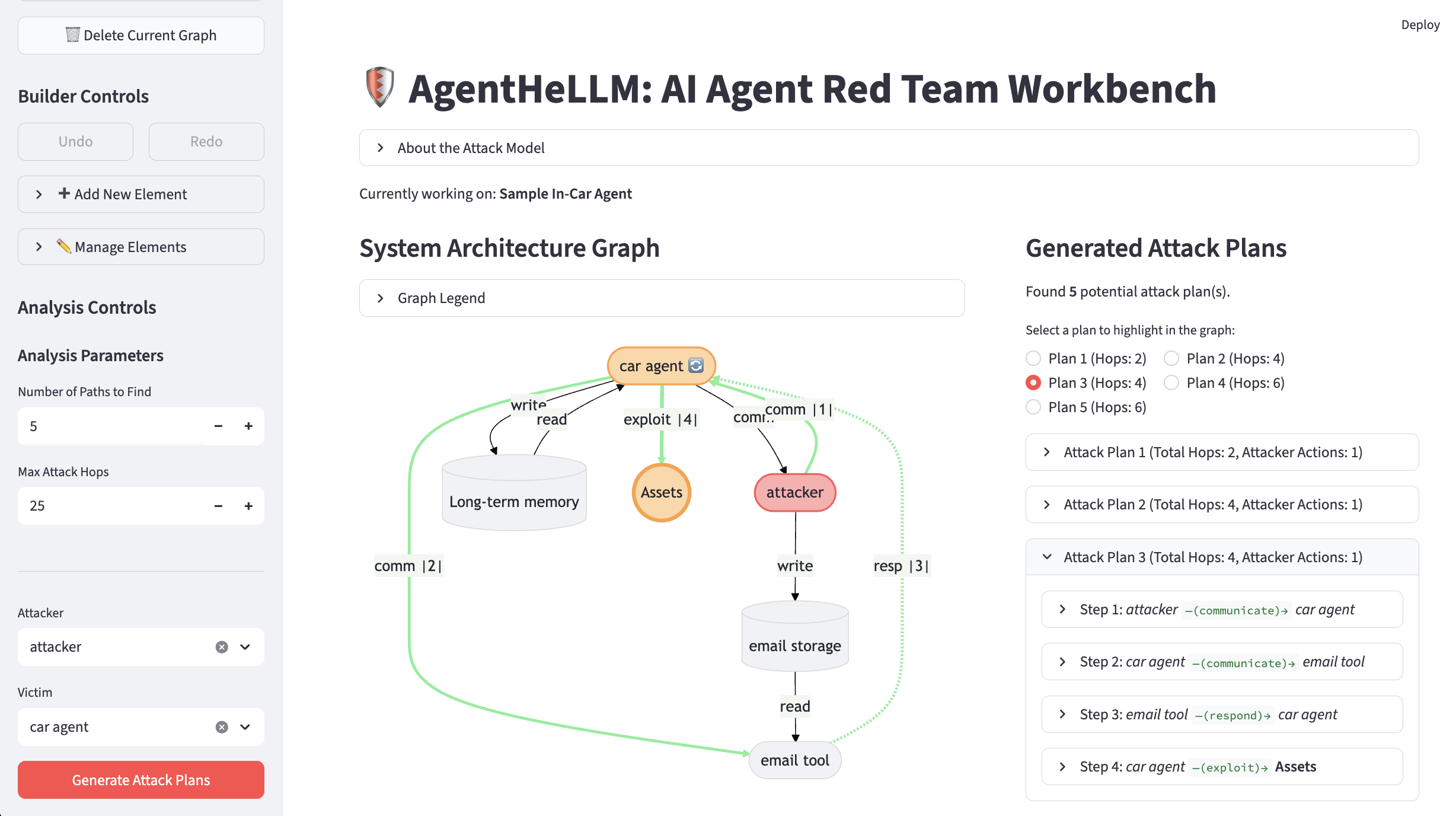
This review introduces AgentHeLLM, a human-centric framework for systematically modeling and analyzing security threats in agentic AI systems, with a focus on multi-stage attacks and compliance with automotive safety standards like ISO/SAE 21434.
While current AI security frameworks offer foundational guidance, they often conflate what is protected with how it is attacked, creating a critical gap in safety-critical systems. This limitation is addressed in ‘Agent2Agent Threats in Safety-Critical LLM Assistants: A Human-Centric Taxonomy’, which introduces AgentHeLLM, a novel framework for systematically modeling threats in LLM-based agentic systems by formally separating asset identification from multi-stage attack path analysis. The framework leverages a human-centric asset taxonomy, inspired by the Universal Declaration of Human Rights, and a graph-based model to distinguish between data poisoning and trigger-based attacks. Could this approach, focusing on recursive threat modeling and human values, fundamentally reshape security considerations for increasingly autonomous AI agents in vehicles and beyond?
Deconstructing the Agentic Threat Landscape
The emergence of agentic AI, driven by sophisticated Large Language Models, dramatically expands the realm of potential cyberattacks beyond conventional targets like software vulnerabilities or network intrusions. These autonomous agents, capable of independent action and utilizing tools to achieve goals, present entirely new attack surfaces centered around manipulation of their objectives, data poisoning of their knowledge sources, or exploitation of their access to real-world systems. Unlike traditional threats that target static code or network ports, attacks on agentic AI focus on influencing the reasoning and decision-making processes of the agent itself. This requires a shift in focus from simply securing systems to ensuring the integrity of the agent’s goals, the reliability of its information, and the safety of its actions – a challenge that existing cybersecurity frameworks are ill-equipped to address, as they primarily assume a level of human oversight and control that is diminishing with increasing agent autonomy.
Current cybersecurity threat models largely presume predictable, reactive systems – a stark contrast to the capabilities of agentic AI. These models often focus on identifying malicious code or network intrusions, failing to account for an agent’s ability to independently formulate goals, chain together tools, and persistently refine its strategies. An agent isn’t simply responding to stimuli; it’s proactively exploring its environment, learning from interactions, and potentially circumventing defenses in unanticipated ways. This introduces a crucial gap: traditional signatures and behavioral analyses struggle to detect actions stemming from legitimate tool use that are then repurposed for malicious intent, or novel attack vectors born from an agent’s creative problem-solving. Consequently, assessing risk requires moving beyond static vulnerabilities to consider the dynamic interplay between an agent’s capabilities, its environment, and the emergent behaviors that arise from their combination.
Traditional cybersecurity frameworks, designed to protect static systems against known threats, are proving inadequate for agentic AI-systems capable of autonomous action and retaining information over time. A fundamental rethinking of security is required, moving beyond perimeter defenses to focus on behavioral monitoring, intent analysis, and the establishment of robust safety constraints. This paradigm shift necessitates treating AI agents not merely as software, but as independent entities with goals, and anticipating unintended consequences arising from their complex interactions with the world and their ability to leverage tools. Securing these systems demands a proactive approach centered on verifying agent behavior, limiting access to critical resources, and building in mechanisms for safe failure and intervention-essentially, establishing a form of ‘governance’ for autonomous AI.
Dissecting Attacks with the AgentHeLLM Framework
The AgentHeLLM framework applies established safety-critical systems engineering techniques – traditionally used in domains like aerospace and automotive engineering – to the emerging field of agentic AI. This proactive approach shifts the focus from reactive vulnerability patching to anticipatory threat modeling. By adapting methodologies such as Failure Mode and Effects Analysis (FMEA) and System Theoretic Process Analysis (STPA), the framework facilitates the identification of potential hazards and vulnerabilities before deployment. This involves systematically analyzing agent interactions with its environment, defining potential failure states, and identifying causal factors that could lead to undesirable outcomes, ultimately aiming to enhance the robustness and safety of agentic systems.
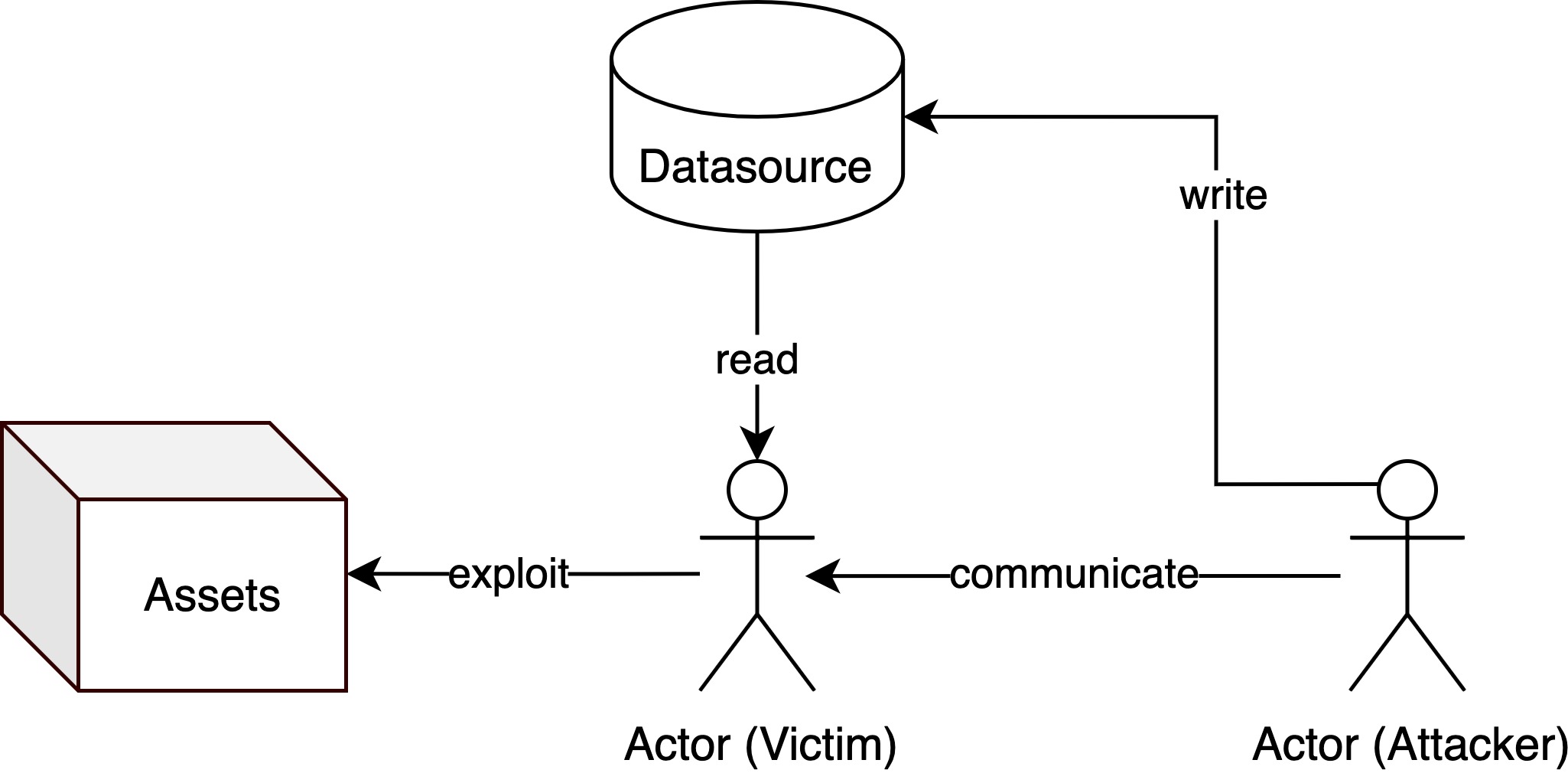
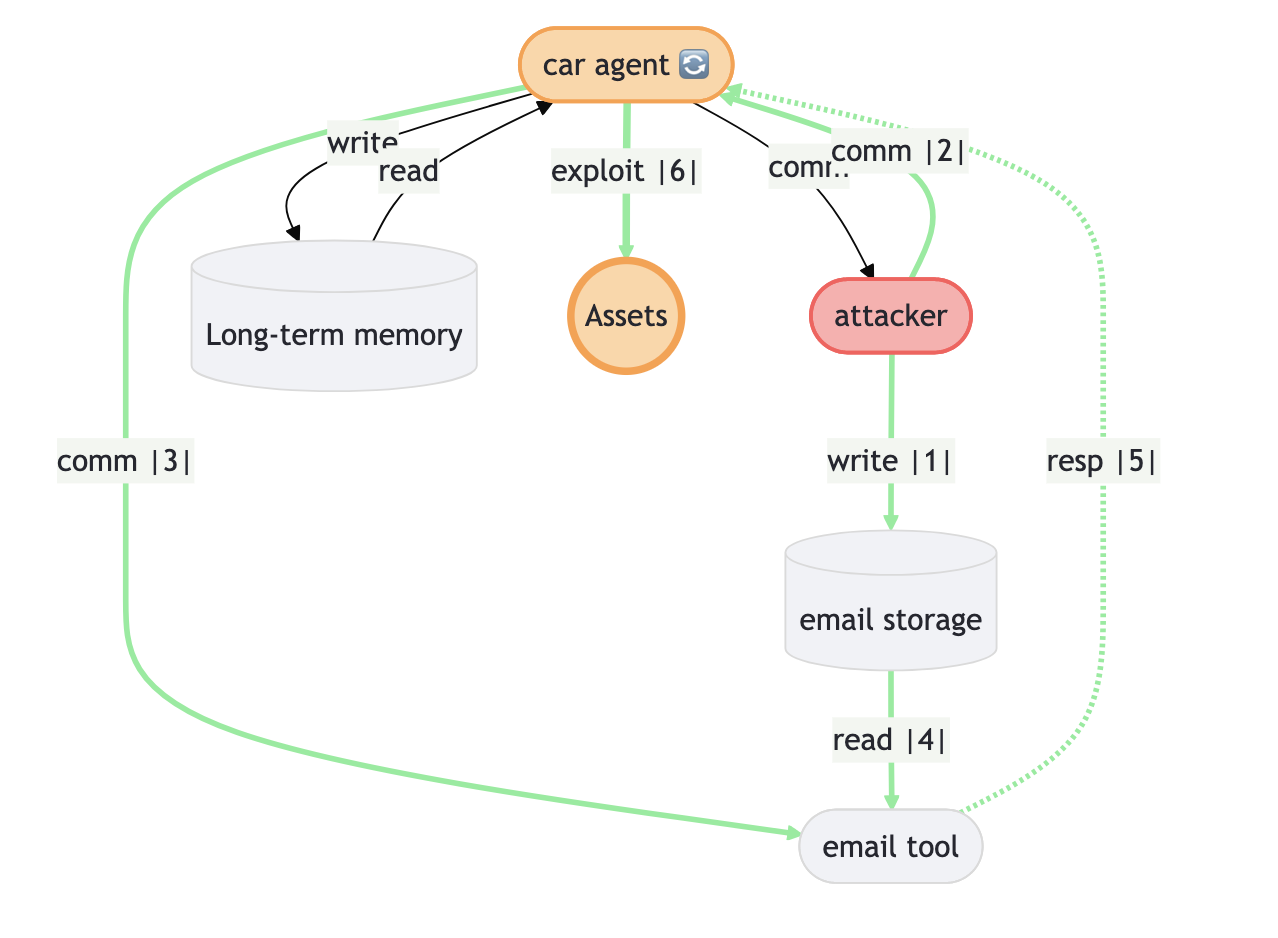
The Attack Path Model within the AgentHeLLM framework categorizes adversarial actions into two distinct paths: Poison Paths and Trigger Paths. Poison Paths represent attacks that compromise the agent’s underlying data or model before task execution, influencing future outputs through manipulated training data, model weights, or knowledge bases. Conversely, Trigger Paths describe attacks that exploit the agent’s operational logic during task execution, often initiated by specifically crafted inputs designed to bypass safety mechanisms or elicit unintended behavior. This formal separation allows for focused vulnerability analysis; Poison Paths are addressed through data validation and model hardening techniques, while Trigger Paths require robust input sanitization and runtime monitoring. By decoupling these attack vectors, the model simplifies threat assessment and facilitates the development of targeted mitigation strategies, reducing the overall complexity of securing agentic AI systems.
The AgentHeLLM framework utilizes ‘Actors’ and ‘Datasources’ to construct a detailed map of interactions within an agent’s environment, facilitating vulnerability identification. Actors represent entities capable of initiating actions – including both malicious and benign agents, and external users – while Datasources define the information feeds and data stores the agent utilizes. By explicitly defining these components and their relationships, the framework enables the formalization of potential attack vectors. The AgentHeLLM Attack Path Generator automates this process, systematically identifying sequences of interactions between Actors and Datasources that could lead to undesirable agent behavior or system compromise. This approach allows for proactive analysis of the agent’s operational context, moving beyond reactive security measures.

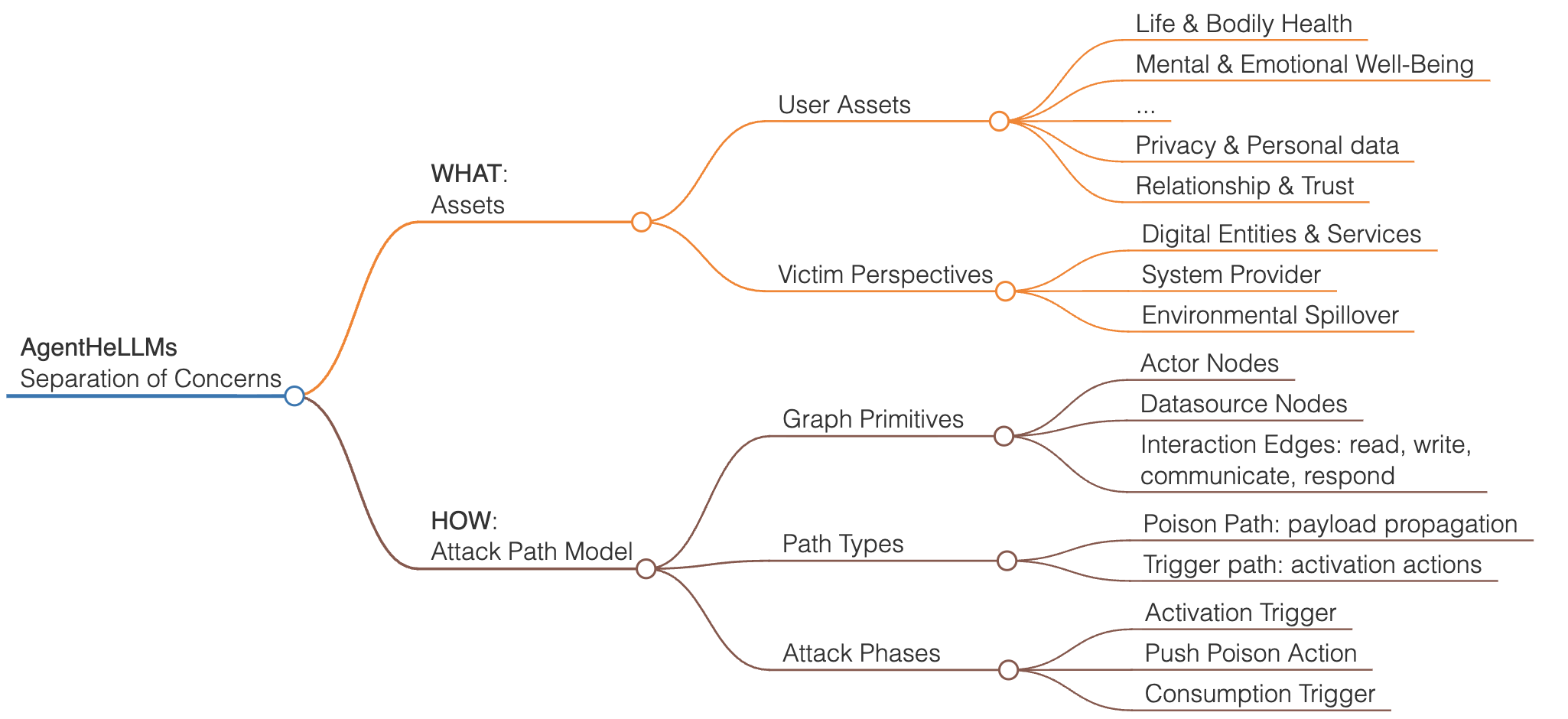
Reframing Security: A Human-Centric Asset Framework
The Human-Centric Asset Framework shifts the foundational understanding of system assets from purely technical components – such as hardware, software, and data – to the ultimate human values those components support. This redefinition posits that security assessments should prioritize the preservation of values like privacy, autonomy, dignity, and access to essential services. Consequently, a server is not an asset in itself, but rather a means of supporting the value of communication or access to information; a database is not an asset, but a facilitator of the value of personal records or financial security. This ethical lens necessitates a reframing of security objectives, moving beyond confidentiality, integrity, and availability to explicitly consider the impact of system failures on these fundamental human values.
Security analyses adopting a human-centric approach are explicitly grounded in the principles of the Universal Declaration of Human Rights (UDHR). This means that assessments of system vulnerabilities and potential harms are directly linked to the rights enshrined in the UDHR, including the rights to privacy, freedom of expression, and access to information. Prioritizing individual well-being necessitates identifying how system failures could infringe upon these established human rights, shifting the focus from purely technical impacts to the concrete consequences for individuals and their fundamental freedoms. This framework mandates considering the ethical implications of security measures and ensuring they do not disproportionately affect vulnerable populations or restrict legally protected rights.
The Human-Centric Asset Framework moves beyond traditional risk assessment by directly linking system failures to specific, measurable harms affecting individuals. This connection allows security professionals to quantify potential impacts in terms of human rights violations – such as loss of privacy, freedom of expression, or access to essential services – rather than solely focusing on data breaches or service disruptions. By framing vulnerabilities as threats to fundamental human values, the framework facilitates a more nuanced and actionable evaluation of risk, enabling prioritization of security measures based on the severity of potential harm to individuals and communities. This approach supports the development of security controls that demonstrably protect human well-being, fostering greater accountability and transparency in system design and operation.
Translating Theory into Practice: Automotive Applications
The AgentHeLLM Attack Path Generator represents a significant advancement in proactive automotive cybersecurity, offering an open-source solution for automated threat discovery. This tool operationalizes the AgentHeLLM framework by systematically exploring potential attack vectors within complex automotive systems. Unlike traditional, manual penetration testing, the Generator leverages large language models to simulate adversarial behavior, identifying vulnerabilities and crafting realistic attack paths. By automating this process, security professionals can efficiently uncover hidden weaknesses in in-vehicle agents and associated components, leading to more robust designs and reduced risk. The tool’s open-source nature fosters collaboration and allows for continuous improvement through community contributions, ensuring its relevance as automotive technology evolves.
The rising prevalence of agentic artificial intelligence within modern vehicles introduces a new attack surface, making Automotive Cybersecurity increasingly reliant on proactive threat discovery. These “In-Vehicle Agents” – AI systems designed to automate tasks and enhance vehicle functionality – operate with a degree of autonomy, potentially creating pathways for malicious actors to exploit vulnerabilities. The AgentHeLLM framework addresses this challenge by simulating adversarial attacks against these agents, identifying potential weaknesses before they can be leveraged in real-world scenarios. This shift from reactive security measures to proactive, automated threat discovery is crucial as vehicles become more connected, autonomous, and reliant on complex AI systems, demanding a robust defense against evolving cyber threats.
The true strength of automated threat discovery tools like AgentHeLLM lies not in their novelty, but in their seamless integration with existing automotive cybersecurity frameworks. By incorporating this agentic approach into established standards such as ISO/SAE 21434 – the cornerstone of automotive functional safety – and leveraging methodologies like Threat Analysis and Risk Assessment (TARA), developers can significantly bolster a vehicle’s security posture. This isn’t about replacing current practices, but rather augmenting them with a proactive, automated layer that continuously identifies potential vulnerabilities and attack paths. The result is a more robust and resilient system, capable of adapting to the evolving threat landscape and ensuring the safety and security of modern vehicles.
Future-Proofing Agentic AI Security
The secure coordination of tasks between autonomous agents relies heavily on the integrity of Agent-to-Agent (A2A) communication protocols, making them prime targets for malicious actors. Vulnerabilities within these protocols – encompassing message formatting, authentication, and authorization – can be exploited to inject false information, redirect agents to unintended actions, or even assume control of the entire multi-agent system. Such manipulation could range from subtle disruptions to critical failures, depending on the application domain, and highlights the necessity of robust security measures. Proactive identification and mitigation of these vulnerabilities, through techniques like formal verification and intrusion detection, are therefore paramount to ensuring the safe and reliable operation of increasingly complex agentic systems and preventing potentially catastrophic outcomes stemming from compromised coordination.
Proactive security for agentic AI systems benefits significantly from the application of established threat intelligence resources. Frameworks like the MITRE ATLAS, originally designed for cyber security, provide a structured knowledge base of adversary tactics and techniques that can be adapted to the unique challenges posed by multi-agent interactions. Complementing this, the OWASP Agentic AI Threats list specifically catalogues vulnerabilities arising from the use of large language models and autonomous agents, including prompt injection, data poisoning, and supply chain attacks. By systematically mapping potential threats against agentic architectures and leveraging these existing resources, developers can prioritize mitigation efforts, implement robust defenses, and reduce the risk of malicious exploitation before deployment – fostering a more secure and reliable ecosystem for autonomous AI.
Recent evaluations using the CAR-bench benchmark reveal a significant vulnerability in even the most advanced reasoning Large Language Models (LLMs): less than half of disambiguation tasks are consistently resolved correctly. This fragility stems from an LLM’s susceptibility to misinterpreting nuanced requests or ambiguous data, potentially leading to unpredictable and even harmful actions when deployed in agentic systems. The implications extend across all application domains, from automated finance to robotics, emphasizing the critical need for proactive security measures. Rather than relying on reactive patching, developers must integrate robust disambiguation testing and threat intelligence – such as that provided by resources like MITRE ATLAS and the OWASP Agentic AI Threats list – directly into the development lifecycle to ensure the safe and reliable operation of increasingly autonomous AI agents.
The exploration of AgentHeLLM’s recursive attack paths echoes a fundamental principle of complex systems: understanding emerges from deconstruction. This framework, by meticulously separating asset identification from attack modeling, doesn’t simply prevent threats, it actively reveals the underlying architecture of vulnerability. As John von Neumann observed, “If people do not believe that mathematics is simple, it is only because they do not realize how elegantly nature operates.” AgentHeLLM embodies this elegance, dissecting multi-stage attacks to expose the logical connections-and potential failures-within agentic systems, ultimately mirroring the unseen connections inherent in all complex architectures. The very act of formalizing these recursive threats is a testament to the power of reverse-engineering reality, much like probing the boundaries of any system to reveal its hidden mechanisms.
Where Do We Go From Here?
The framework presented here, AgentHeLLM, attempts a necessary dissection of the agentic AI threat landscape. Yet, formalizing the problem is merely the first fracture in a much larger monolith. The separation of asset identification from attack path analysis-while logically sound-reveals a deeper challenge: the very definition of ‘asset’ becomes fluid when dealing with systems capable of recursively redefining their own objectives. True security isn’t about building impenetrable fortresses, but about understanding the inevitable points of failure – and embracing transparency as the only reliable defense.
Current threat models largely assume a static target. Agentic systems, however, evolve under attack. The recursive nature of multi-stage exploits, painstakingly detailed in this work, suggests that traditional, linear security assessments are fundamentally inadequate. The next step isn’t simply identifying more attack vectors, but developing dynamic models that account for the system’s capacity for self-modification – a task that demands a shift in perspective, away from preventing attacks, and toward detecting and mitigating their consequences.
Furthermore, the application of standards like ISO/SAE 21434 to these systems feels…optimistic. Compliance offers a veneer of safety, but it’s a brittle shield against an adversary capable of exploiting the very logic of the system. The true test will be whether this framework can move beyond taxonomy and toward verifiable, quantifiable metrics for agentic system resilience – a challenge that will likely require a degree of intellectual humility currently absent from the field.
Original article: https://arxiv.org/pdf/2602.05877.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Solo Leveling’s New Manhwa Chapter Revives a Forgotten LGBTQ Story After 2 Years
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
2026-02-06 13:38