Author: Denis Avetisyan
New research explores whether the internal representations of advanced audio AI models align with the way the human brain processes sound during natural listening.
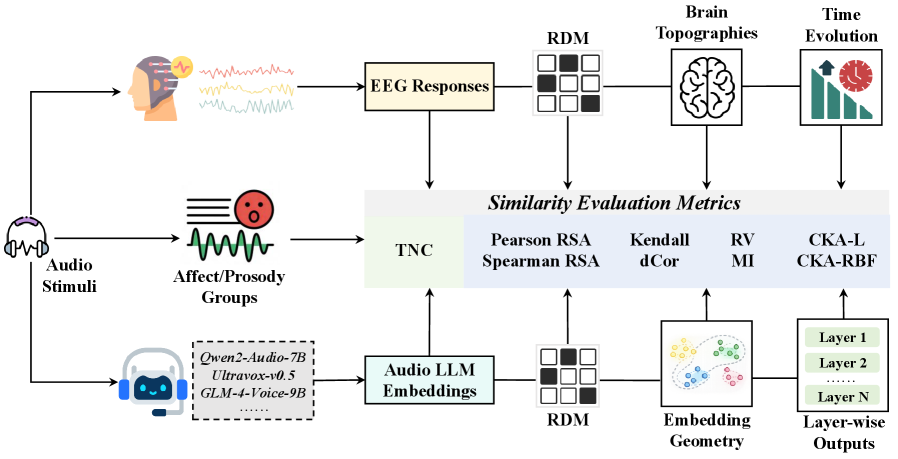
Researchers used EEG and representational similarity analysis to investigate the alignment between audio large language models and human brain activity, revealing depth- and time-dependent patterns and highlighting the importance of prosodic features.
While recent advances in Audio Large Language Models (Audio LLMs) demonstrate impressive capabilities in understanding speech, a critical gap remains in understanding whether their internal processing mirrors human auditory cognition. This work, ‘Do Models Hear Like Us? Probing the Representational Alignment of Audio LLMs and Naturalistic EEG’, systematically investigates the alignment between layer-wise representations of 12 open-source Audio LLMs and human electroencephalogram (EEG) signals during naturalistic listening. Our analysis reveals depth- and time-dependent representational patterns, notably peaking within the 250-500ms window consistent with N400 responses, and a modulation of alignment by prosodic content. Ultimately, these findings raise the question of how incorporating neurobiological constraints can further refine the design and interpretability of future Audio LLMs.
The Erosion of Ecological Validity in Speech Perception
Historically, speech perception research has favored highly controlled stimuli – isolated words or syllables presented in quiet environments. While offering experimental precision, this approach often sacrifices ecological validity, the extent to which findings generalize to real-world listening conditions. The human auditory system rarely encounters speech in such pristine form; instead, it navigates a constant stream of continuous, overlapping sounds, background noise, and varying acoustic properties. Consequently, insights gleaned from these simplified laboratory settings may not fully capture the complexities of how the brain decodes speech in naturalistic environments, where contextual cues and prosodic features play a crucial role in successful communication. This discrepancy highlights a persistent challenge in speech science: bridging the gap between controlled experimentation and the messy, dynamic reality of auditory perception.
The human brain’s capacity to decipher speech extends far beyond the cleanly articulated words of a laboratory setting; it thrives on the messy, continuous stream of naturalistic speech-conversations, stories, and ambient auditory environments. However, this very naturalness presents a formidable challenge for neuroscientists. Unlike the predictable timing and clarity of controlled stimuli, real-world speech is characterized by coarticulation, rapid shifts in prosody, overlapping sounds, and significant variability in accent and delivery. Consequently, pinpointing the neural mechanisms responsible for segregating, tracking, and interpreting these complex auditory signals requires innovative analytical approaches. Current research focuses on disentangling the brain’s ability to predict upcoming phonemes, utilize contextual cues, and dynamically adjust to the ever-changing acoustic landscape-a process far more intricate than processing isolated words, and one that remains a key frontier in understanding the neural basis of language comprehension.
The intricacies of human speech extend far beyond isolated phonemes; prosodic features – encompassing rhythm, stress, and intonation – are crucial for conveying meaning and emotional nuance. However, current speech processing technologies often fall short in accurately capturing this complexity when faced with naturalistic auditory environments. Existing methods, frequently trained on carefully curated datasets of isolated words or sentences, struggle to disentangle the rapid shifts and subtle variations inherent in continuous speech. This limitation stems from the difficulty in modeling the interplay between acoustic signals, contextual cues, and individual speaking styles present in real-world conversations, hindering advancements in areas like speech recognition, emotion detection, and ultimately, a complete understanding of how the brain decodes spoken language. Capturing the full spectrum of prosodic information remains a central challenge in bridging the gap between artificial systems and the fluidity of human communication.
Audio LLMs: A Computational Echo of Auditory Processing
Audio Large Language Models (Audio LLMs) represent a significant advancement in computational modeling of auditory information by leveraging the principles of deep learning and sequence modeling. These models, typically based on transformer architectures, are trained on extensive datasets of audio to learn complex relationships between acoustic features and semantic meaning. Unlike traditional signal processing techniques which often rely on handcrafted features, Audio LLMs automatically learn relevant representations directly from raw or minimally processed audio waveforms. This allows them to capture nuanced acoustic patterns, prosodic information, and contextual dependencies within audio signals, enabling tasks such as speech recognition, audio classification, and sound event detection with state-of-the-art performance. The capacity of these models to encode and process audio in a sequence-to-sequence manner also facilitates generation of novel audio content and manipulation of existing audio signals.
Audio Large Language Models require the conversion of raw audio waveforms into quantifiable features for processing. This feature extraction commonly involves techniques like Mel-Frequency Cepstral Coefficients (MFCCs), which represent the spectral envelope of a sound, and pitch estimation, capturing prosodic information related to intonation and stress. Furthermore, models often utilize filterbank energies to capture broad spectral characteristics and delta and delta-delta coefficients to represent temporal changes in these features. The selection and processing of these acoustic and prosodic features are critical, as they determine the information available to the LLM and directly impact its ability to model and understand audio content.
Investigating the internal representations of Audio Large Language Models (Audio LLMs) provides a method for examining the neural basis of auditory processing in the brain. This approach involves quantifying the similarity between the feature activations within the Audio LLM and recorded brain activity, typically using representational similarity analysis (RSA) and Centered Kernel Alignment (CKA). RSA, utilizing Spearman Correlation, assesses the correspondence between the representational dissimilarity matrices derived from both the model and neural data. CKA, a kernel-based method, directly computes the alignment between the learned feature spaces, providing a metric independent of linear transformations. These metrics allow researchers to determine to what extent the model’s internal representations reflect the computations performed by the auditory system.

Layer-Wise Alignment: Unveiling Hierarchical Processing
Temporal alignment was performed to establish a correspondence between the internal representations of an Audio Language Model and electroencephalography (EEG) data. This involved shifting and stretching the model’s feature vectors in time to maximize the correlation with ongoing brain activity recorded via EEG sensors. Specifically, dynamic time warping and cross-correlation methods were utilized to account for potential delays and variations in processing speed between the model and the neural signals. The resulting aligned data enabled a direct comparison of model activations with specific moments in time within the recorded brain activity, forming the basis for subsequent layer-wise correlation analyses.
Layer-wise alignment of the Audio LLM with electroencephalography (EEG) data indicated that distinct layers of the model engage with differing facets of neural processing. Specifically, shallower layers exhibited stronger correlations with auditory cortical regions associated with early sound feature extraction, while deeper layers demonstrated increased alignment with brain areas involved in higher-level cognitive functions such as semantic processing and contextual integration. This suggests a hierarchical correspondence between the model’s internal representations and the stages of information processing within the human auditory system, with each layer capturing information at a different level of abstraction.
Layer-wise correlation analysis between the Audio LLM and EEG data revealed statistically significant depth-dependent processing patterns. Specifically, the degree to which individual layers of the model correlated with brain activity varied considerably across the network’s depth, with permutation test p-values consistently below 0.05 indicating the reliability of these findings. This suggests that different layers of the Audio LLM capture and represent information in a manner that aligns with distinct stages or aspects of neural processing, rather than exhibiting a uniform relationship with overall brain activity.
Semantic Echoes: Bridging the Gap Between Silicon and Synapse
A compelling correspondence between artificial and biological systems emerges when examining the temporal dynamics of semantic processing. Researchers aligned signals from an Audio Language Model – a computational system designed to understand spoken language – with neural activity recorded via electroencephalography. This time-resolved analysis revealed a robust correlation, suggesting that the way the model represents meaning mirrors how the brain processes it. Specifically, the model’s internal representations at various moments in time systematically corresponded to patterns of brain activity, indicating a shared computational substrate for understanding language. This synchronization isn’t merely a coincidence; it implies that the model captures essential features of human semantic processing, offering a powerful tool for investigating the neural basis of meaning and potentially bridging the gap between artificial intelligence and human cognition.
Research reveals a compelling link between human brain activity and artificial intelligence, specifically demonstrating that patterns of neural response during semantic processing closely mirror those within certain layers of an Audio Language Model. Analysis focused on the N400 window – a component of the electroencephalogram associated with semantic categorization – showed significant alignment with the internal representations developed by the AI. This isn’t merely a correlation; the findings suggest a shared computational mechanism underlying how both the brain and this sophisticated AI process meaning from audio input. The overlap implies that the AI, in building its understanding of language, is utilizing principles similar to those employed by the human brain, offering valuable insights into the neural basis of semantic processing and potentially informing the development of more human-like artificial intelligence.
Investigations incorporating affective prosody reveal that emotional content is not merely added to semantic processing, but is represented in a structured, hierarchical fashion within neural networks. Analysis demonstrates that negative prosody-such as a harsh or critical tone-alters the way information is organized and related. Specifically, this type of prosody diminishes the reliance on simple rank ordering of concepts-where ideas are judged by their position in a list-but simultaneously amplifies the importance of covariance-style dependence, indicating a focus on the relationships between concepts. This shift is quantified using the Tri-modal Neighborhood Consistency (TNC) metric, suggesting that negative emotional cues promote a more nuanced and interconnected understanding of information, emphasizing relational processing over straightforward categorization.
The study’s exploration of temporal resolution in aligning Audio LLMs with human EEG signals reveals a fascinating truth about system decay. While models strive for ever-increasing complexity, the brain, and by extension any natural system, operates within the constraints of time. The observed depth- and time-dependent alignment isn’t a failure of the model, but rather a demonstration of how all systems, even those built on silicon, are subject to the inevitable erosion of perfect correspondence. As Barbara Liskov observed, “It’s one of the difficult things about systems – that you have to have a balance between changing things and keeping things stable.” This paper subtly underscores that stability, in this context, isn’t permanence, but a carefully managed delay of the inherent drift between model and reality.
What Lies Ahead?
The pursuit of brain-model alignment, as demonstrated by this work, inevitably reveals not so much convergence as differential rates of decay. Models, unburdened by the constraints of biological systems, can scale rapidly, yet often at the cost of representational fidelity to the nuanced temporal dynamics of naturalistic input. The observed depth- and time-dependent alignment suggests that the question isn’t simply if models hear like us, but when, and at what level of abstraction. The study highlights that systems learn to age gracefully, and that focusing on prosodic information is a crucial step, but it simultaneously reveals the vastness of what remains uncaptured.
Future work will likely grapple with the limitations of current representational similarity analysis techniques. Static comparisons, even with improved temporal resolution, offer only snapshots of a profoundly dynamic process. Tri-modal consistency is a laudable goal, but complete correspondence may be a mirage. Perhaps the more fruitful path lies not in forcing alignment, but in understanding the unique representational strategies employed by both biological and artificial systems.
Ultimately, the field may find that sometimes observing the process of divergence is more informative than attempting to accelerate convergence. A complete duplication of human auditory processing is likely unattainable, and perhaps even undesirable. The true value lies in teasing apart the essential principles underlying intelligent sound processing, regardless of the substrate.
Original article: https://arxiv.org/pdf/2601.16540.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- All Itzaland Animal Locations in Infinity Nikki
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- How to Get to the Undercoast in Esoteric Ebb
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- Crimson Desert: Disconnected Truth Puzzle Guide
- A Dark Scream Theory Rewrites the Only Movie to Break the 2-Killer Rule
- Gold Rate Forecast
- 6 Ways Invincible Season 4’s Hell Episode Rewrites The Comics
2026-01-27 05:58