Author: Denis Avetisyan
A new federated learning framework enables identifying the origins of anomalies in industrial control systems without compromising data privacy or requiring model changes.
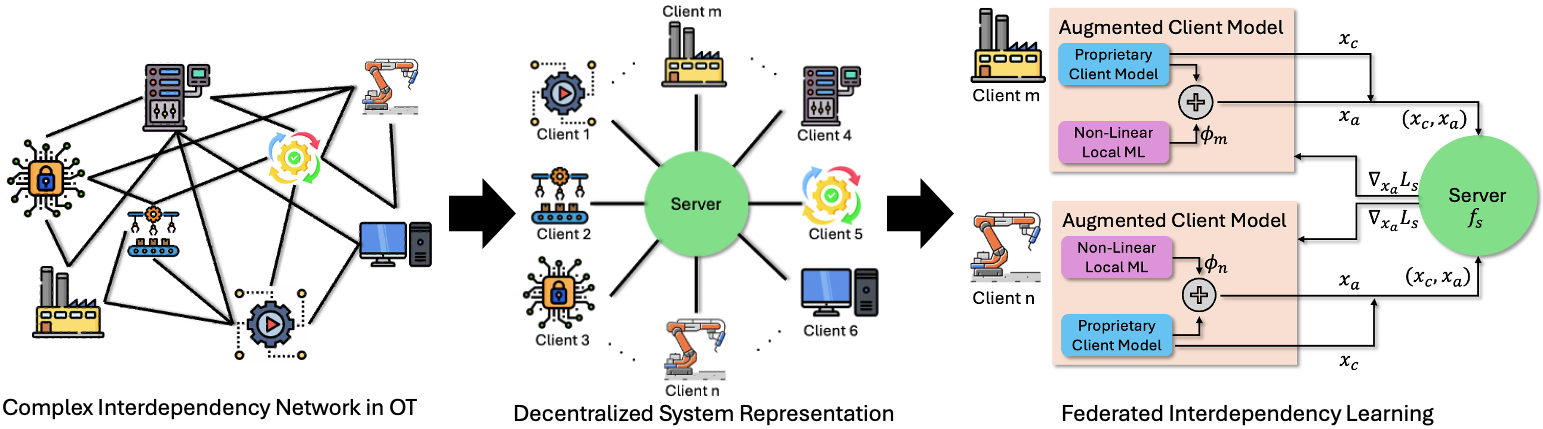
This work presents a privacy-preserving system for decentralized root cause analysis in nonlinear dynamical systems, leveraging federated learning to infer interdependencies and pinpoint failure sources.
Identifying the root causes of failures in complex, networked industrial systems remains challenging due to dynamically evolving interdependencies and data heterogeneity. This paper, ‘Learning Unknown Interdependencies for Decentralized Root Cause Analysis in Nonlinear Dynamical Systems’, introduces a federated learning framework to address this problem, enabling decentralized anomaly detection and root cause identification without requiring access to raw data or modification of existing client models. By learning cross-client interdependencies from feature-partitioned time-series data, our approach achieves representation consistency while preserving privacy through calibrated differential privacy. Could this methodology unlock more robust and scalable solutions for maintaining the resilience of critical infrastructure in the face of increasingly complex threats?
The Inherent Flaws of Centralized Intelligence
Conventional machine learning systems typically demand the aggregation of data into centralized repositories, a practice that introduces significant vulnerabilities and practical hurdles. The consolidation of sensitive information – be it personal health records, financial transactions, or proprietary industrial data – creates a single point of failure for privacy breaches and cyberattacks. Furthermore, the sheer volume of data often necessitates substantial bandwidth and processing power for transmission and storage, leading to communication bottlenecks and increased costs, particularly when dealing with geographically distributed data sources. This centralized approach fundamentally limits the scalability and applicability of machine learning in contexts where data privacy is paramount, or where the cost of data movement is prohibitive, necessitating a shift towards more decentralized paradigms.
The conventional approach to machine learning often falters when confronted with data that is either highly sensitive or widely distributed. Regulations protecting personal information, such as those concerning healthcare records or financial transactions, frequently restrict the movement of data to a central location for analysis. Simultaneously, the sheer volume of data generated by an increasingly interconnected world – think of sensor networks spanning vast geographical areas or mobile devices constantly collecting user data – creates significant logistical and communication hurdles. Transferring these massive datasets to a central server not only strains bandwidth and introduces latency, but also amplifies the risk of data breaches and compromises privacy. Consequently, the efficacy of traditional machine learning diminishes in these crucial real-world applications, necessitating alternative strategies that prioritize data locality and privacy preservation.
Conventional machine learning systems typically necessitate the aggregation of data in a central location for processing, a practice that introduces vulnerabilities regarding data privacy and creates substantial communication demands. However, a shift in approach is gaining momentum: distributed intelligence prioritizes bringing the computational process to the data itself. This fundamentally alters the paradigm by eliminating the need for massive data transfers and enabling learning directly at the point of origin. Such a strategy not only safeguards sensitive information but also unlocks the potential of data generated in remote or bandwidth-constrained environments, promising more efficient and secure artificial intelligence systems capable of operating on a truly decentralized scale.
Decentralized learning represents a significant shift in machine learning methodology, addressing limitations inherent in centralized approaches. Rather than consolidating data in a single location for model training, this paradigm distributes the learning process to the very devices or locations where data originates – think smartphones, IoT sensors, or individual hospital networks. This localized training enhances data privacy by minimizing data transfer and reduces communication bottlenecks, especially crucial when dealing with massive datasets or intermittent network connectivity. By enabling model adaptation directly at the data source, decentralized learning facilitates personalized and efficient AI applications, fostering a more robust and scalable infrastructure for the future of intelligent systems. The implications extend to diverse fields, from healthcare and finance to autonomous vehicles and edge computing, promising a new era of data-driven innovation.
Federated Learning: A Mathematically Sound Distribution
Federated Learning (FL) builds upon the principles of Decentralized Learning by establishing a comprehensive framework for collaborative machine learning. Unlike traditional centralized approaches where data is pooled in a single location, FL enables model training across a multitude of decentralized devices or servers holding local data samples. This distributed paradigm avoids the direct exchange of data, instead focusing on sharing model updates – such as gradients or model parameters – to achieve a globally optimized model while preserving data privacy. The FL framework encompasses algorithms, protocols, and system designs necessary for coordinating this distributed training process, addressing challenges such as statistical heterogeneity, communication costs, and system reliability inherent in decentralized environments.
Vertical Federated Learning (VFL) is a machine learning approach designed for scenarios where multiple parties, each holding a distinct subset of features for the same set of samples, collaboratively train a model without directly exchanging data. This contrasts with traditional distributed learning where each party possesses complete samples. In VFL, data remains locally stored with each participant; only model updates – specifically, gradients or encrypted intermediate representations – are shared during the training process. This is achieved through secure multi-party computation (SMPC) techniques, enabling model convergence while preserving data privacy and addressing challenges posed by feature heterogeneity across clients. The primary use case is often found in industries where data is naturally partitioned, such as banking (where one client may have transaction history and another credit scores) or healthcare (where different hospitals may hold various patient records).
Effective Federated Learning (FL) performance is directly reliant on addressing the inherent statistical dependencies existing across data held by different clients. Distributed datasets, even when representing the same underlying population, rarely consist of independent and identically distributed (i.i.d.) samples. Cross-client interdependencies arise from factors such as overlapping features, shared entities, or systemic biases present in individual client datasets. Ignoring these dependencies can lead to model divergence, reduced generalization performance, and compromised privacy benefits. Consequently, FL algorithms must incorporate mechanisms to detect, model, and leverage these interdependencies to ensure robust and accurate collaborative learning.
Non-linear local machine learning models are essential for capturing cross-client interdependencies in federated learning because they allow for the creation of complex, high-dimensional local representations. Linear models, by definition, cannot represent non-linear relationships present in real-world data, limiting their ability to encode nuanced interactions between features held by different clients. Utilizing models such as deep neural networks or gradient boosting machines enables the extraction of intricate feature combinations and dependencies, resulting in richer local representations that improve the overall performance of the federated learning process. These richer representations better reflect the underlying data distribution and facilitate more accurate global model aggregation by capturing subtle, yet important, relationships within the distributed dataset.
Global Aggregation: A System-Wide State of Knowledge
The Global Server Model functions as the primary aggregation point for data generated by distributed local models. These local models, deployed on individual client devices, perform initial data processing and inference; their resulting insights, rather than raw data, are transmitted to the Global Server. This aggregation is not a simple averaging; the Global Server employs a defined process to consolidate these local insights into a unified, system-wide understanding. This centralized processing enables global optimization and the identification of patterns that would be undetectable from isolated local data streams, facilitating improved system performance and predictive capabilities. The architecture minimizes data transmission costs and preserves user privacy by transmitting processed insights instead of raw, potentially sensitive, data.
The efficacy of the Global Server Model is fundamentally dependent on the Loss Function utilized during aggregation. This function quantifies the discrepancy between predicted and actual values, guiding the optimization process and ensuring the model converges towards the desired global objective. A poorly defined Loss Function can lead to inaccurate aggregation, suboptimal performance, and divergence from the true system state. Specifically, the Loss Function must accurately represent the priorities of the overall system – for example, prioritizing precision, minimizing latency, or balancing competing objectives – and appropriately weight the contributions of individual local models to achieve the desired global outcome. The selection and tuning of this function are therefore critical to the successful operation of the aggregation process and the overall system performance.
State Estimation is the process of inferring the internal state of a system based on a series of incomplete and noisy measurements. Its importance is heightened in dynamic environments where the system’s parameters change over time, requiring continuous updates to the estimated state. Accurate state estimation enables prediction of future system behavior, facilitating proactive control and optimization. Techniques employed range from simple filtering to more complex recursive Bayesian estimation, with the Kalman filter and its variants – such as the Extended Kalman Filter – being commonly used to maintain a probability distribution representing the current state, incorporating both prior knowledge and new observations. The accuracy of state estimation directly impacts the performance of downstream applications relying on predicted system trajectories and values.
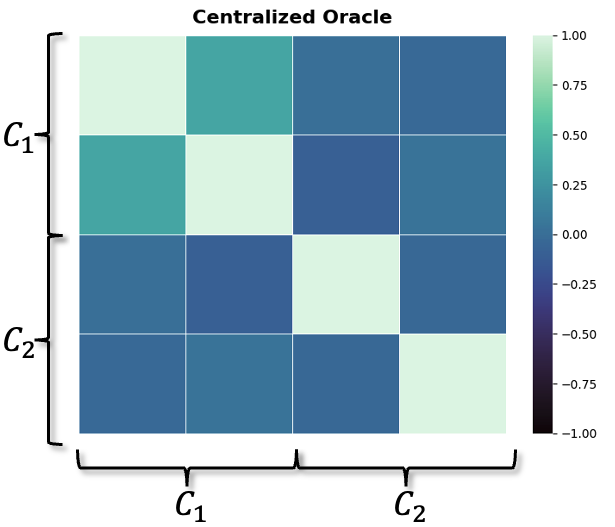
The Extended Kalman Filter (EKF) addresses state estimation in non-linear systems by linearizing the state transition and observation models around the current estimate. This linearization allows the application of the standard Kalman Filter equations, albeit with Jacobian matrices representing the partial derivatives of the non-linear functions. Client models leverage EKF to achieve performance metrics comparable to a centralized oracle, despite operating with decentralized data. The EKF’s robustness stems from its ability to handle process and measurement noise, providing statistically optimal estimates under Gaussian assumptions. Performance is contingent on accurate Jacobian calculation and appropriate noise covariance tuning; however, the EKF provides a computationally efficient solution for real-time state tracking in complex, dynamic environments where a centralized solution is impractical.

Preserving Privacy and Detecting Anomalies in Distributed Networks
To protect the confidentiality of individual client data within distributed systems, a technique called differential privacy is employed during the process of model aggregation. This is achieved by strategically adding carefully calibrated Gaussian noise to the updates contributed by each client before they are combined to form a global model. The noise obscures the specific contributions of any single client, ensuring that the presence or absence of their data has a limited impact on the final result. This approach provides a quantifiable privacy guarantee; while it introduces a degree of statistical uncertainty, it prevents adversaries from inferring sensitive information about individual clients, even with access to the aggregated model. The amount of noise added is carefully balanced against the need to maintain the accuracy and utility of the overall model, representing a crucial trade-off in privacy-preserving machine learning.
In distributed systems, the capacity to pinpoint anomalous behaviors is paramount, serving as a crucial defense against both malicious attacks and unexpected system failures. These systems, often characterized by decentralized data and processing, present unique challenges for traditional security measures; a compromised node or an unforeseen operational shift can rapidly cascade into widespread disruption. Effective anomaly detection isn’t simply about flagging irregularities, but also about discerning genuine threats from benign variations, particularly within the constant stream of data inherent to distributed environments. Consequently, robust frameworks are needed to monitor system metrics, user actions, and network traffic, identifying deviations from established baselines that could indicate intrusions, data breaches, or critical performance degradation-ultimately safeguarding the integrity and reliability of the entire system.
Residual analysis and Mahalanobis distance represent complementary approaches to pinpointing unusual system behavior. Residual analysis examines the difference between predicted and actual values; significant deviations from the expected residual distribution suggest anomalies. Mahalanobis distance, conversely, measures the distance between a data point and the mean of the distribution, taking into account the covariance between variables – effectively identifying outliers relative to the natural spread of the data. By combining these techniques, the framework can discern subtle anomalies that might be missed by either method alone, particularly in high-dimensional distributed systems where simple thresholding proves ineffective. The strength of Mahalanobis distance lies in its ability to account for correlations within the data, allowing for the identification of anomalies that fall outside the expected multivariate distribution, even if they are not extreme in any single dimension.
Rigorous evaluation of the framework utilized the HAIL dataset, a collection of data derived from a functioning industrial control system, to assess its anomaly detection capabilities in a realistic cybersecurity scenario. Results demonstrate a strong ability to accurately pinpoint anomalous behavior, even when subjected to substantial noise – maintaining training stability at noise levels as high as 101 and 105. Importantly, the system’s performance scaled effectively to accommodate a distributed network of 16 clients, suggesting its viability for deployment in complex, large-scale industrial environments where distributed anomaly detection is crucial for proactive threat mitigation and system resilience.
This distributed framework demonstrates a notable capability in not only identifying anomalous behaviors within a system, but also in pinpointing the root causes of those anomalies with high precision. Rigorous evaluation reveals that its performance in anomaly detection rivals that of a centralized oracle – a system with complete access to all data – despite operating in a decentralized manner. This suggests the framework effectively mitigates the information loss typically associated with distributed learning, providing actionable insights into system malfunctions or malicious activities without sacrificing diagnostic accuracy. The ability to accurately trace anomalies back to their origin is crucial for rapid response and effective mitigation, enhancing the resilience and security of distributed systems in complex operational environments.

The pursuit of decentralized root cause analysis, as detailed in the article, mirrors a fundamental tenet of mathematical rigor. The framework’s emphasis on identifying interdependencies without centralizing data aligns with the need for provable solutions, rather than relying on empirical observation alone. As G.H. Hardy stated, “Mathematics may be compared to a box of tools.” This sentiment underscores the importance of a well-defined, robust methodology-like the federated learning approach-to dissect complex systems. The article’s commitment to differential privacy further reinforces this principle, ensuring the integrity and reliability of the analytical process, striving for correctness beyond mere functional performance.
What Lies Ahead?
The presented framework, while a demonstrable advance in decentralized anomaly attribution, merely skirts the fundamental issue of model identifiability. The successful operation relies on the implicit assumption that the learned interdependencies are uniquely defined by the observed data – a proposition rarely verifiable in complex, high-dimensional industrial processes. Future work must address the inherent ambiguity; a probabilistic treatment of interdependency strength, coupled with formal sensitivity analysis, is not simply desirable, but essential. The current reliance on federated averaging, while pragmatic, introduces a degree of statistical smoothing that could mask subtle, yet critical, causal pathways.
A persistent challenge remains the computational cost of inferring causal structures from decentralized data streams. The pursuit of ever-more-complex models risks exceeding the resource constraints of edge devices, negating the benefits of a decentralized approach. A shift towards provably efficient algorithms – those with guaranteed computational bounds – is paramount. The elegance of a solution is not measured by its accuracy on a benchmark, but by the demonstrable minimality of its implementation.
Ultimately, the true test lies not in identifying anomalies, but in preventing them. The long-term objective should be the development of adaptive control strategies predicated on the learned interdependencies – systems that proactively mitigate risk rather than reactively diagnose failure. Such a vision demands a rigorous formalization of the underlying dynamical system, and a departure from purely data-driven approaches. The pursuit of empirical success, while tempting, should not overshadow the necessity of mathematical certainty.
Original article: https://arxiv.org/pdf/2602.21928.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Mewgenics vinyl limited editions now available to pre-order
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Viral Letterboxd keychain lets cinephiles show off their favorite movies on the go
2026-02-26 11:31