Author: Denis Avetisyan
Researchers have developed a novel framework for dissecting complex time series models and revealing the underlying drivers of their predictions.
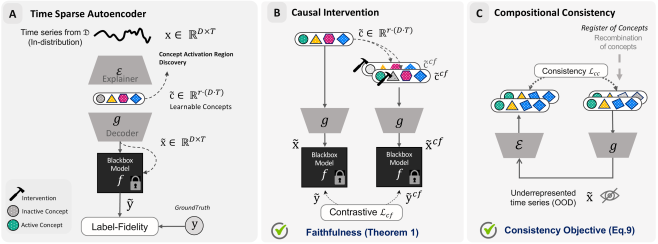
TimeSAE leverages sparse autoencoders to generate faithful and interpretable explanations by decomposing time series into meaningful concepts.
Despite the increasing prevalence of black-box models in time series analysis, explaining their predictions-particularly when faced with distributional shifts-remains a critical challenge. This work introduces TimeSAE: Sparse Decoding for Faithful Explanations of Black-Box Time Series Models, a novel framework leveraging sparse autoencoders to decompose time series into interpretable, causal concepts. Through this approach, TimeSAE generates more faithful and robust explanations compared to existing methods, demonstrating improved performance on both synthetic and real-world datasets. Can this concept-learning approach unlock greater trust and reliability in time series forecasting and decision-making?
Deconstructing the Black Box: The Quest for Transparent Time Series Models
A growing reliance on complex time series models – often described as ‘black boxes’ – permeates critical applications ranging from financial forecasting and healthcare monitoring to energy grid management and climate prediction. While these models can achieve impressive accuracy, their internal workings remain opaque, leaving users unable to discern why a particular prediction was made. This lack of transparency poses significant challenges; without understanding the reasoning behind a forecast, validating its reliability becomes difficult, hindering trust and potentially leading to flawed decision-making. Consequently, a demand is emerging not just for accurate predictions, but for models that can articulate the factors driving those predictions, enabling informed intervention and responsible application of time series analysis in increasingly complex domains.
Historically, analyzing time series data has often yielded predictions without accompanying explanations, creating a significant barrier to practical application. Traditional statistical methods, while adept at forecasting, frequently treat the underlying data as a monolithic block, obscuring the individual contributions of different temporal features. This lack of transparency makes it difficult to validate model outputs, identify spurious correlations, or understand the causal mechanisms driving observed trends. Consequently, decision-makers are often hesitant to rely on these ‘black box’ predictions, particularly in high-stakes domains like finance, healthcare, or infrastructure management, where understanding why a prediction is made is as crucial as the prediction itself. The inability to extract meaningful insights from time series data thus limits its utility, hindering informed action and eroding trust in predictive modeling.
The demand for interpretable machine learning extends beyond simply understanding how a model arrives at a prediction; it fundamentally addresses the need for transparency and accountability in critical applications. In fields like healthcare, finance, and autonomous systems, the implications of a flawed or biased prediction can be severe, necessitating the ability to trace the reasoning behind decisions. Identifying causal factors-the specific elements within time series data that drive a particular outcome-is paramount for building trust and ensuring responsible AI. This interpretability isn’t merely about explaining results post hoc; it enables proactive model refinement, facilitates regulatory compliance, and empowers stakeholders to confidently integrate these predictive tools into complex workflows. Ultimately, a model’s predictive power is significantly enhanced when coupled with a clear understanding of its internal logic and the variables influencing its forecasts.
TimeSAE: Distilling Essence from Complexity
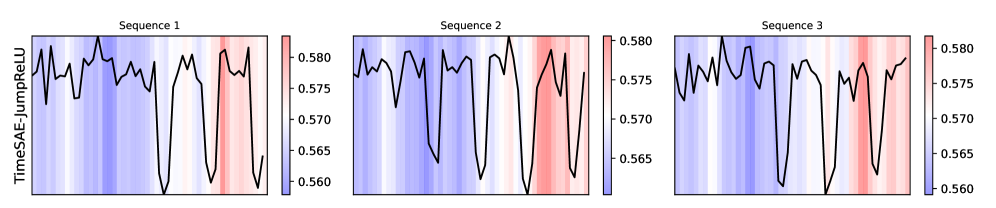
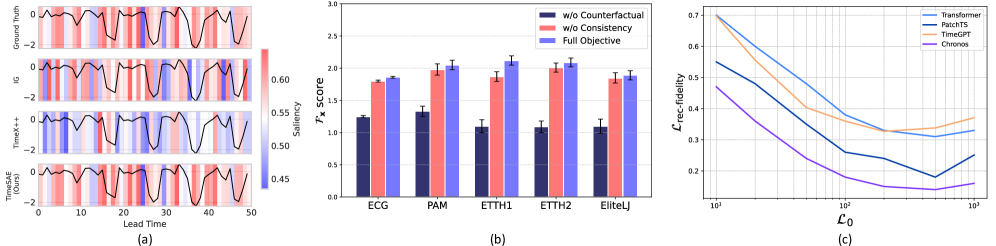
TimeSAE is a novel approach to interpreting time series models by leveraging the principles of sparse autoencoders. This method aims to generate interpretable explanations for predictions made by black-box time series models. The core architecture utilizes an autoencoder, a type of neural network trained to reconstruct its input, but incorporates sparsity-inducing techniques to force the learned representations to focus on the most salient features. By learning a compressed, sparse representation of the input time series data, TimeSAE effectively distills the key concepts driving the model’s decision-making process, providing a more transparent and understandable explanation of its behavior. This contrasts with methods that may highlight numerous, and potentially irrelevant, features.
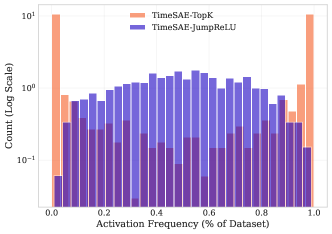
TimeSAE employs the JumpReLU activation function to induce sparsity within the learned representations. JumpReLU operates by randomly zeroing out a proportion of activations during the forward pass, effectively acting as a stochastic regularizer. This process forces the autoencoder to rely on a limited subset of features – the most salient concepts – to reconstruct the input time series. The degree of sparsity is controlled by a hyperparameter determining the probability of an activation ‘jumping’ to zero. By prioritizing these dominant features, TimeSAE generates more interpretable explanations of the black-box model’s decision-making process, as the remaining non-zero activations directly correspond to the most relevant concepts influencing predictions.
TimeSAE achieves enhanced interpretability by generating sparse representations of the concepts impacting model predictions. This is accomplished through a reduction in the number of active features used to represent each concept, effectively isolating the most influential elements. By minimizing redundancy and focusing on key features, the model distills complex relationships into a more understandable format. The resulting sparse representations allow for easier identification of the concepts driving specific predictions, providing a focused explanation of the model’s behavior and facilitating analysis of its decision-making process.
Unveiling Causal Links: A Rigorous Examination
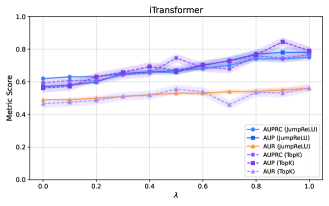
TopK Selection within TimeSAE functions as a dimensionality reduction technique to distill the most pertinent concepts from a larger set of potential explanations. This method identifies the ‘K’ most influential concepts based on their contribution to the model’s decision-making process, effectively prioritizing those features that have the strongest impact. By limiting the explanation to these top-ranked concepts, TimeSAE ensures a concise and focused output, improving interpretability without sacrificing fidelity to the original model’s reasoning. The value of ‘K’ is a hyperparameter that controls the granularity of the explanation; lower values yield more compact explanations, while higher values offer greater detail.
TimeSAE prioritizes faithfulness in concept extraction to ensure the identified concepts directly reflect the reasoning process of the underlying black-box model. This is achieved through a specific optimization strategy during the extraction process, resulting in a state-of-the-art faithfulness score of 2.12, as measured by established evaluation metrics. This score indicates a high degree of alignment between the extracted concepts and the model’s internal logic, providing more interpretable and reliable explanations compared to methods with lower faithfulness scores.
The quality of extracted explanations is quantitatively assessed using the Causal Concept Effect (CCE). CCE directly measures the impact of identified concepts on the model’s predictive behavior; a higher CCE indicates a stronger correlation between the presence or absence of a concept and changes in the model’s output. This is achieved by perturbing the input feature corresponding to a concept and observing the resulting shift in the model’s prediction. The magnitude of this shift is then quantified, providing a concrete metric for evaluating the causal relevance of the extracted concept and validating the explanation’s fidelity.
TimeSAE enhances feature representation and extraction through the incorporation of Squeeze-and-Excitation (SE) and Time Convolutional Network (TCN) techniques. The SE mechanism adaptively recalibrates channel-wise feature responses, emphasizing informative features and suppressing less relevant ones. Concurrently, the TCN utilizes dilated convolutions to efficiently process temporal sequences, capturing long-range dependencies without the computational burden of recurrent networks. This combination allows TimeSAE to effectively learn and represent features crucial for accurate concept extraction, particularly in time-series data, by weighting feature importance and efficiently modelling temporal relationships.
Beyond Prediction: Towards Actionable Intelligence
TimeSAE distinguishes itself through its ability to generate ‘Counterfactual Explanations’, moving beyond simply identifying influential factors in time series data to actively exploring potential outcomes. This is achieved by dissecting complex patterns into sparse, interpretable concepts, allowing the system to reason about hypothetical scenarios – what if a particular variable had been different? By pinpointing the minimal changes required to achieve a desired outcome, TimeSAE empowers users to not only understand why a prediction was made, but also to assess the impact of interventions or alterations to the underlying data. This capability is particularly valuable in domains requiring proactive decision-making, offering a powerful tool for scenario planning and risk assessment, as it transforms opaque model outputs into actionable insights regarding potential future states.
A central benefit of this research lies in its emphasis on identifying causal relationships within time series data, rather than merely correlations. By pinpointing the factors that directly influence model predictions, the system fosters greater trust in its outputs. This isn’t simply about knowing what a model predicts, but understanding why, enabling users to confidently integrate these predictions into real-world decision-making processes. This causal clarity is particularly valuable in domains where incorrect predictions can have significant consequences, allowing stakeholders to assess the robustness of the model and proactively mitigate potential risks. Ultimately, the method empowers informed action by translating complex data patterns into understandable, actionable insights.
TimeSAE significantly advances model reliability through enhanced debugging capabilities, directly revealing the reasoning behind its predictions. This transparency isn’t merely for human understanding; it actively facilitates the identification and correction of internal flaws within the model itself. The system achieves a demonstrably reduced reconstruction error – a key metric of predictive accuracy – not by sacrificing performance, but by maintaining competitive levels alongside established methodologies. This dual benefit of improved accuracy and enhanced debuggability positions TimeSAE as a robust solution for time series analysis, fostering greater trust in model outputs and enabling more effective system maintenance over time.
The development of transparent and accountable artificial intelligence within time series analysis is significantly advanced by this approach, offering a compelling alternative to computationally expensive models. By achieving comparable performance with a mere 3.5 million parameters-a substantial reduction from the 8.2 million required by Transformer-based methods-the system demonstrates remarkable parameter efficiency. This streamlined architecture translates directly into lower inference costs, registering at 0.45 GFLOPs and facilitating deployment in resource-constrained environments. The resulting gains in efficiency and clarity not only enhance the practicality of time series AI, but also lay a crucial foundation for building systems where predictions are understandable, trustworthy, and readily auditable.
The pursuit of understanding, as demonstrated by TimeSAE, mirrors a fundamental tenet of knowledge acquisition: deconstruction. This framework doesn’t simply accept the output of black-box time series models; it actively dissects them, seeking the underlying concepts that drive prediction. This echoes John McCarthy’s sentiment: “It is better to deal with reality, even if it is unpleasant, than to create a pleasant fantasy.” TimeSAE embraces the complexity of real-world time series data, opting to reveal its inherent structure through sparse decomposition, rather than simplifying it into a palatable but inaccurate representation. The resulting faithful explanations aren’t about creating a comforting narrative, but about accurately representing the causal mechanisms at play.
What Lies Ahead?
The pursuit of explainability, as demonstrated by TimeSAE, frequently resembles a controlled demolition rather than genuine understanding. The framework successfully decomposes time series, identifying ‘concepts’ that purportedly drive model behavior. However, the very notion of a ‘meaningful concept’ remains frustratingly subjective. The inherent risk lies in mistaking correlation for causation, building explanations that seem right but lack true predictive power when pushed beyond the training distribution. Future work must aggressively challenge these learned concepts, actively attempting to break them with adversarial examples and out-of-distribution data-only then can genuine robustness be assessed.
A critical limitation lies in the autoencoder’s inherent dimensionality reduction. While sparsity aids interpretability, it simultaneously imposes a bottleneck, potentially obscuring subtle but crucial influences. The field needs to explore methods for quantifying information loss during decomposition, acknowledging that any explanation is, by necessity, an incomplete representation of reality. Perhaps the focus should shift from finding concepts to generating counterfactuals-not explaining why a model made a decision, but systematically probing the boundaries of its knowledge.
Ultimately, TimeSAE, like all explainability research, is a temporary truce in an ongoing war against complexity. The true test won’t be in creating pretty explanations, but in building systems that are demonstrably wrong when presented with invalid assumptions. The goal isn’t to illuminate the black box, but to rigorously map its failure modes – because understanding what a system cannot do is far more valuable than understanding what it does.
Original article: https://arxiv.org/pdf/2601.09776.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Mewgenics vinyl limited editions now available to pre-order
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- ‘Timur’ Trailer Sees Martial Arts Action Collide With a Real-Life War Rescue
- Crimson Desert Guide – How to Pay Fines, Bounties & Debt
2026-01-18 15:06