Author: Denis Avetisyan
Researchers have developed a novel method to reveal underlying network structures within observational data, offering insights into phenomena ranging from customer behavior to neurological events.

Leveraging fractional covariance powers and network science, this work demonstrates robust structural recovery and a framework for detecting emergent behavior in partially observed complex systems.
Detecting emergent phenomena – from sudden customer attrition to epileptic seizure onset – remains challenging due to the hidden causal interactions within complex systems. This work, ‘The Powers of Precision: Structure-Informed Detection in Complex Systems — From Customer Churn to Seizure Onset’, introduces a novel machine learning method that recovers latent network structure from observational data by leveraging fractional powers of the empirical covariance matrix, \Sigma^\alpha. We demonstrate that this approach provides a structurally consistent feature representation, even with partial observability, and achieves competitive performance in both seizure detection and churn prediction. Can this principled framework for reconciling predictive power with interpretable statistical structure unlock broader applications in understanding and forecasting critical transitions across diverse complex systems?
The Illusion of Order: Why We Chase Patterns in Noise
The world is replete with phenomena – from the synchronized flashing of fireflies to the cascading failures of financial markets – that arise not from isolated events, but from the intricate interplay within complex systems. These systems, comprised of numerous interconnected components, exhibit behaviors that are more than the sum of their parts – a characteristic known as emergence. An epileptic seizure, for instance, isn’t simply a random firing of neurons; it’s a macroscopic consequence of aberrant collective dynamics within a neural network. Similarly, a market crash isn’t caused by a single failing stock, but by a rapid, self-reinforcing cascade of selling pressure triggered by interconnected trading algorithms and investor psychology. Understanding these emergent properties requires moving beyond a reductionist approach and instead focusing on the relationships and interactions between the system’s constituent elements, revealing a deeper order hidden within apparent chaos.
Conventional analytical techniques, while effective for simpler systems, frequently falter when confronted with the tangled web of interactions defining complex phenomena. These methods often rely on assumptions of linearity or independence that simply don’t hold true in systems where components dynamically influence each other. Consequently, models built upon these foundations can yield inaccurate predictions, failing to anticipate emergent behaviors or cascading failures. For example, attempts to forecast financial market volatility using solely historical price data often miss crucial signals embedded in the network of investor sentiment and global events. This limitation highlights the need for innovative approaches capable of discerning the nuanced, often non-linear, dependencies that govern these intricate systems, moving beyond superficial correlations to uncover the deeper structural laws at play.
The predictive power of complex systems modeling hinges not simply on identifying relationships, but on discerning the underlying structural laws that dictate how components interact. Traditional correlation-based approaches often fall short because they mistake association for causation, or fail to account for higher-order dependencies-a network might show increased activity in two areas when a third, unobserved element is the primary driver. Consequently, researchers are increasingly focused on techniques like network analysis and information theory to map the architecture of these systems, revealing patterns of influence and control that go beyond pairwise relationships. These methods aim to identify the critical nodes and connections-the ‘skeleton’ of the system-that determine its overall behavior and resilience, offering a pathway to more accurate predictions and targeted interventions.
Beyond Independence: Modeling Systems as Networks
Structure-Informed Feature Representation is a modeling methodology designed to integrate a system’s inherent network topology directly into the feature engineering process. Unlike traditional methods that treat data points as independent, this approach explicitly acknowledges and utilizes the relationships defined by the network structure. This is achieved by constructing feature representations that reflect the connectivity patterns and dependencies within the system, allowing models to leverage information about how variables interact. The methodology moves beyond simple correlation and seeks to capture a more holistic understanding of the system’s organization, ultimately aiming for improved model performance and interpretability by grounding representations in the underlying system architecture.
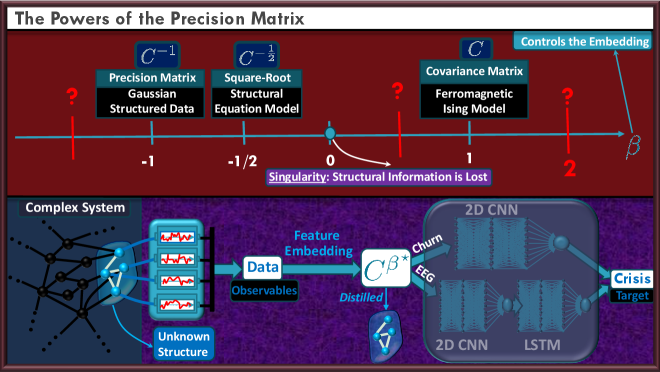
The methodology utilizes the covariance matrix to quantify relationships between variables within a system; however, standard covariance analysis can fail to capture nuanced or indirect dependencies. To address this, the approach incorporates techniques such as raising the covariance matrix to a fractional power – denoted as Σ^{α} , where 0 < α < 1 – which effectively scales the eigenvalues and can reveal latent relationships not apparent in the original matrix. This fractional power transformation acts as a regularization technique, reducing the influence of strong, potentially spurious correlations while amplifying weaker, but meaningful, dependencies, thereby improving the robustness and interpretability of the resulting feature representation.
Structure-informed feature representation aims to enhance model robustness and interpretability by directly incorporating a system’s underlying network structure into the modeling process. This is achieved by representing data not as isolated points, but as influenced by their relationships within the network. Demonstrated across diverse systems, the methodology provides consistent structural recovery, evidenced by a mathematically bounded error term, Δβ. This bound quantifies the deviation between the recovered structure and the true underlying network, providing a measurable guarantee of accuracy and enabling reliable inference even with noisy or incomplete data. The ability to rigorously bound Δβ is critical for applications requiring high confidence in structural identification and parameter estimation.
From Euclidean Space to Network Topology: A Generalized Random Field
The Graph-Based Matérn Random Field (GBMRF) represents an extension of the established Matérn Random Field to accommodate data structured as a network. Traditional Matérn Random Fields are defined on Euclidean spaces, but the GBMRF generalizes this to operate directly on graph data, where variables reside on the nodes of a graph. This is achieved by defining the covariance structure of the random field based on the graph’s adjacency matrix, enabling the modeling of spatial correlation between nodes. Specifically, the GBMRF utilizes a kernel function parameterized by a scale and range parameter, analogous to the traditional Matérn, but adapted to the graph structure to define the covariance between any two nodes based on their network connectivity and distance – measured as the shortest path length between them. This allows for the representation of dependencies beyond immediate neighbors, capturing long-range influences within the network.
The modeling of dependencies between variables residing on graph nodes is achieved through the utilization of the Precision Matrix, also known as the inverse covariance matrix \textbf{Θ} = \textbf{Σ}^{-1}. This matrix directly encodes conditional relationships; a zero value at position (i,j) indicates that variable i is conditionally independent of variable j given all other variables. Non-zero elements represent direct dependencies, quantifying the strength and direction of influence. By analyzing the structure of \textbf{Θ}, particularly its sparsity pattern, we can infer the underlying network of conditional relationships and understand how variables influence each other within the defined graph. This approach allows for a compact representation of complex dependencies compared to directly modeling the full joint distribution.
The Dunford-Taylor integral facilitates analysis of dependencies within graph-based Matérn random fields by providing a means to express the inverse of a matrix as an infinite series. This is particularly valuable when addressing scenarios with latent (unobserved) nodes influencing observed data, as it allows for consistent estimation even with incomplete information. Specifically, the bounding of the cross-block interaction matrix A_{S S'} – representing the influence of latent nodes S' on observed nodes S – is achievable through the integral’s properties, ensuring the precision matrix remains positive definite and enabling stable recovery of network dependencies despite the presence of hidden variables.
Beyond Prediction: Understanding Why Things Happen
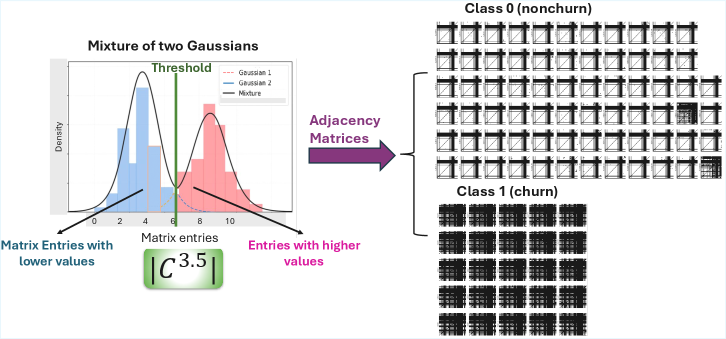
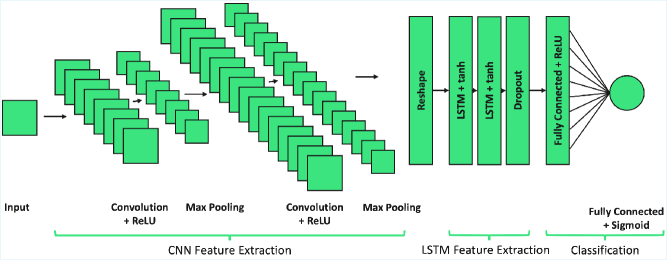
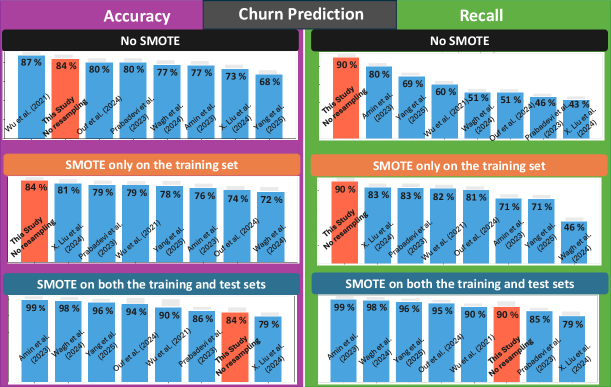
This methodology demonstrates substantial applicability beyond theoretical exploration, proving effective in fields reliant on discerning complex relationships within data. Specifically, promising results have emerged in both seizure detection – where identifying subtle patterns can signal neurological events – and customer churn prediction, a critical area for businesses striving to retain clients. In both cases, the ability to model and interpret underlying data structures, rather than simply observe correlations, yields significantly improved performance and more actionable insights. This suggests a powerful tool for any domain where understanding why something happens is as important as predicting that it will happen, extending its potential far beyond the initial scope of development.
The methodology demonstrates enhanced predictive power through the explicit integration of structural information, yielding results that are not only more accurate but also more readily translated into practical applications. In the critical field of seizure detection, this approach consistently outperforms established benchmark methods, offering a significant step towards more reliable and timely diagnoses. This improvement stems from the system’s ability to discern underlying relationships within complex datasets, moving beyond simple correlative analysis to identify meaningful patterns indicative of seizure activity. The resultant gains in performance promise more effective clinical tools and a deeper understanding of the neurological processes involved, ultimately contributing to improved patient outcomes.
The methodology facilitates a progression beyond simple correlation by enabling structure identification, ultimately opening avenues for causal inference. This is achieved through a representational framework that distinctly separates underlying feature clusters, demonstrated by significantly larger distances between different classes compared to the distances within each class. This clear separation isn’t merely descriptive; it suggests that the identified features are not arbitrarily associated, but rather linked by potential causal mechanisms. Consequently, the representation moves beyond predicting what happens to offer insights into why it happens, providing a foundation for understanding driving forces within complex systems and informing more targeted interventions.
Robustness in the Face of Scarcity: Adapting to Limited Data
Many practical applications face a fundamental hurdle: a lack of sufficient data for effective model training. To overcome this, ‘Training-Testing Adaptation’ techniques have emerged, focusing on preserving the underlying structural information within the limited dataset. Rather than solely memorizing available examples, these methods prioritize capturing the inherent relationships and patterns present, allowing models to generalize more effectively to unseen data. This approach effectively combats overfitting – a common issue when training on small datasets – and enhances the robustness of the model, ultimately broadening its applicability to scenarios where data acquisition is costly, time-consuming, or otherwise restricted. By focusing on structure, these techniques unlock insights even from sparse observations, paving the way for more versatile and reliable artificial intelligence systems.
The capacity to construct resilient models from sparse datasets dramatically broadens the scope of potential applications. Traditionally, machine learning algorithms require extensive data to generalize effectively; however, this research demonstrates that preserving underlying structural information during training mitigates the need for massive datasets. This approach proves particularly valuable in fields where data collection is costly, time-consuming, or ethically challenging, such as rare disease diagnosis, environmental monitoring with limited sensor networks, or personalized medicine based on individual patient histories. By enabling robust performance even with minimal observations, this methodology extends the reach of sophisticated analytical tools to previously inaccessible problem domains, promising impactful solutions across diverse scientific and industrial landscapes.
The current framework, while effective with static datasets, is poised for advancement through the integration of dynamic system modeling and external knowledge sources. Researchers are actively exploring methods to allow the model to adapt not just to limited data, but to evolving circumstances and previously unseen scenarios. This involves incorporating principles of control theory and predictive modeling to anticipate system changes, alongside the infusion of domain-specific expertise – such as established scientific principles or curated databases. Such enhancements promise to move beyond mere pattern recognition, enabling the model to generate truly insightful predictions and offer a more nuanced understanding of complex phenomena, ultimately broadening its applicability to real-world challenges where conditions are rarely static and complete information is often unavailable.
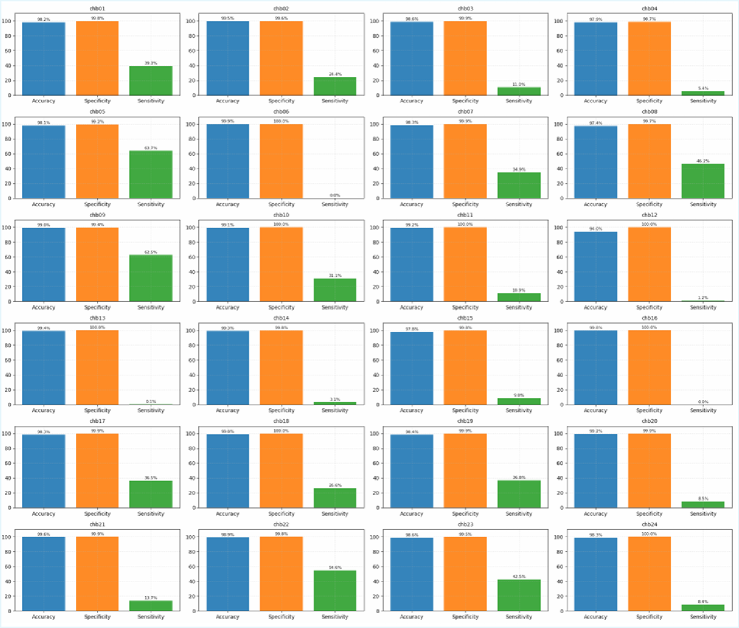
The pursuit of structural recovery, as detailed in the paper, feels less like elegant design and more like archaeological work. One excavates signal from noise, hoping a coherent form emerges from the rubble. Vinton Cerf observed, “Any sufficiently advanced technology is indistinguishable from magic.” This resonates; the method’s ability to infer latent network structure – to glimpse the underlying order even with incomplete data – borders on the mystical. Yet, it’s not magic, but meticulous application of fractional fields and covariance power. The paper demonstrates that even partial observability doesn’t necessarily condemn a system to opacity, but it will inevitably require compromise-a surviving architecture, not a perfect one.
What’s Next?
The enthusiastic pursuit of latent structure, as demonstrated here, will inevitably encounter the harsh realities of production data. Fractional covariance powers, while elegant on paper, presume a stationarity rarely found outside of simulations. The true test won’t be recovering a known network, but discerning signal from the endless noise of systems actively trying to avoid being modeled. Any claim of ‘structural recovery’ should be accompanied by a detailed accounting of the missing data-and a quiet admission of what was conveniently discarded.
The authors rightly highlight the potential for detecting emergent phenomena. However, ‘emergence’ is often a polite term for ‘unforeseen consequence’. Better one monolith, thoroughly understood, than a hundred lying microservices, each confidently predicting the wrong failure mode. The field will likely move toward hybrid approaches, blending these network-based methods with more traditional, statistically robust anomaly detection-essentially, admitting that no single framework possesses all the answers.
Ultimately, the lingering question remains: how much structure is truly there to be recovered? Or is this simply a sophisticated form of pattern-seeking, projecting order onto chaos? The answer, predictably, will depend on who is paying for the analysis. One anticipates a future crowded with increasingly complex methods, each promising to unlock the secrets of complex systems-and each, inevitably, requiring more data than anyone is willing to provide.
Original article: https://arxiv.org/pdf/2601.21170.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- All Itzaland Animal Locations in Infinity Nikki
- Crimson Desert: Disconnected Truth Puzzle Guide
- Katanire’s Yae Miko Cosplay: Genshin Impact Masterpiece
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
- How to Get to the Undercoast in Esoteric Ebb
- How to Complete Bloom of Tranquility Challenge in Infinity Nikki
- DC Comics’ Absolute Two-Face and Absolute Penguin Confirmed
- BloxStrike codes (March 2026)
- 6 Ways Invincible Season 4’s Hell Episode Rewrites The Comics
2026-01-30 12:37