Author: Denis Avetisyan
A new framework automatically assesses how changes to deep learning libraries impact the applications that depend on them, preventing silent errors and improving software stability.
DepRadar leverages multi-agent systems and code understanding to perform context-aware defect impact analysis in deep learning libraries.
Despite the growing reliance on deep learning libraries like Transformers and Megatron, assessing the impact of defects within these systems on downstream applications remains a significant challenge. This paper introduces DepRadar: Agentic Coordination for Context Aware Defect Impact Analysis in Deep Learning Libraries, a novel multi-agent framework designed to automatically pinpoint and analyze such defects, considering complex triggering conditions and client-side configurations. DepRadar achieves high precision and recall in identifying affected programs by coordinating specialized agents that extract defect semantics, synthesize triggering patterns, and perform client-side impact analysis. Could this approach pave the way for more robust and reliable deep learning deployments, minimizing silent errors and enhancing software dependability?
Unseen Failures: The Silent Threat to AI Reliability
Despite their remarkable capabilities, contemporary deep learning libraries aren’t immune to a particularly insidious class of errors known as ‘Silent Defects’. These aren’t the typical bugs that cause immediate program crashes; instead, they manifest as subtle performance degradations, gradually eroding the accuracy or efficiency of a deployed model without any overt warning. The challenge lies in their covert nature – a model might continue to operate, producing outputs that seem reasonable, while quietly generating increasingly inaccurate results. This poses a significant risk, especially in critical applications where even small errors can have substantial consequences, as traditional debugging methods are often ineffective at detecting these performance-based flaws, demanding novel approaches to ensure the reliability of AI systems.
Conventional techniques for identifying software errors often falter when confronted with the nuanced challenges presented by deep learning models. These methods, typically designed to detect crashes or obvious malfunctions, struggle to pinpoint the subtle performance degradation caused by ‘Silent Defects’. Unlike traditional bugs that immediately halt execution, these errors manifest as gradual declines in accuracy or unexpected biases, making them difficult to isolate through standard testing procedures. Consequently, deployed applications reliant on these models face significant risks, potentially leading to flawed decision-making in critical areas such as healthcare, finance, or autonomous systems, all while appearing to function normally.
Assessing the full ramifications of silent defects presents a significant hurdle in ensuring the dependability of artificial intelligence. Unlike conventional software bugs that manifest as crashes or errors, these subtle flaws erode model accuracy and predictive power without immediate indication of failure. This makes pinpointing the extent of compromised functionality incredibly difficult; a seemingly minor degradation in performance across a specific dataset might belie systemic errors impacting critical applications. Consequently, developers face the complex task of not only identifying these hidden defects, but also of rigorously evaluating their influence on various inputs and downstream tasks – a process demanding robust testing methodologies and comprehensive performance monitoring to safeguard against potentially serious consequences in real-world deployments.
DepRadar: An Automated Framework for Defect Impact Analysis
DepRadar is an automated framework designed to analyze defects and their potential impact within deep learning libraries. It functions through the coordination of multiple specialized agents, enabling a systematic approach to identifying issues. This agent-based architecture allows for automated analysis of code changes, defect classification, and the determination of downstream effects resulting from those defects. The framework is intended to improve the efficiency and accuracy of identifying and mitigating potential problems in complex deep learning systems, reducing the need for manual inspection and analysis.
DepRadar utilizes Large Language Models (LLMs), specifically DeepSeek-V3, to parse and interpret the semantic meaning of code within deep learning libraries. This LLM-driven approach allows the framework to move beyond simple syntactic analysis and comprehend the functional role of code components. By understanding code semantics, DepRadar can identify potential defects that might be missed by traditional static analysis tools and accurately pinpoint the root cause of issues. The LLM’s capabilities are central to enabling automated impact analysis by recognizing how changes to one part of the codebase may affect other dependent components.
DepRadar utilizes a multi-agent system for automated defect analysis, comprising a Miner Agent to identify relevant code, a Code Diff Analyzer Agent to pinpoint changes, and an Impact Analyzer Agent to assess downstream effects. Evaluations demonstrate the framework achieves a 95% F1-score in classifying defects and an 85% F1-score in determining the impact of those defects, indicating high performance in both defect identification and consequence prediction.
Deconstructing Defects: A Standardized Approach to Pattern Recognition
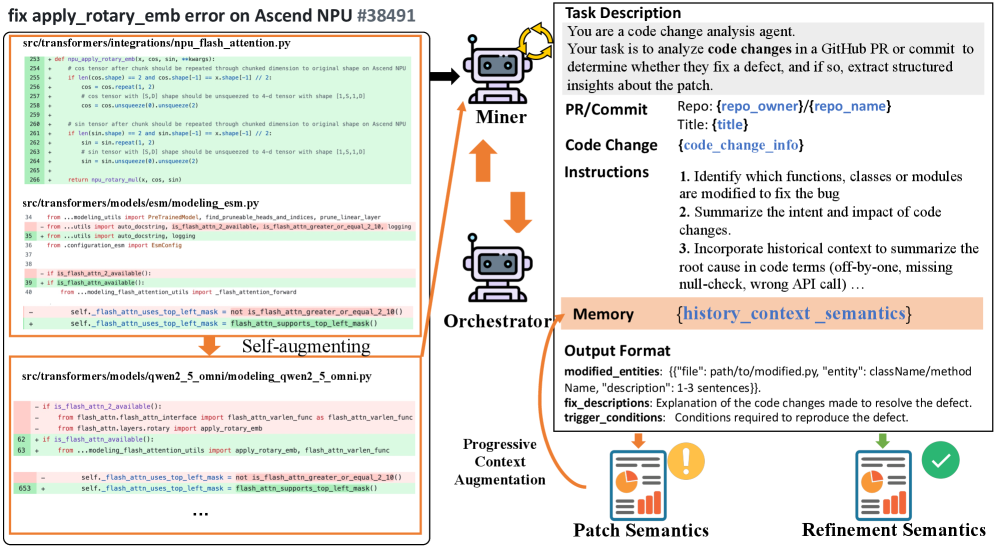
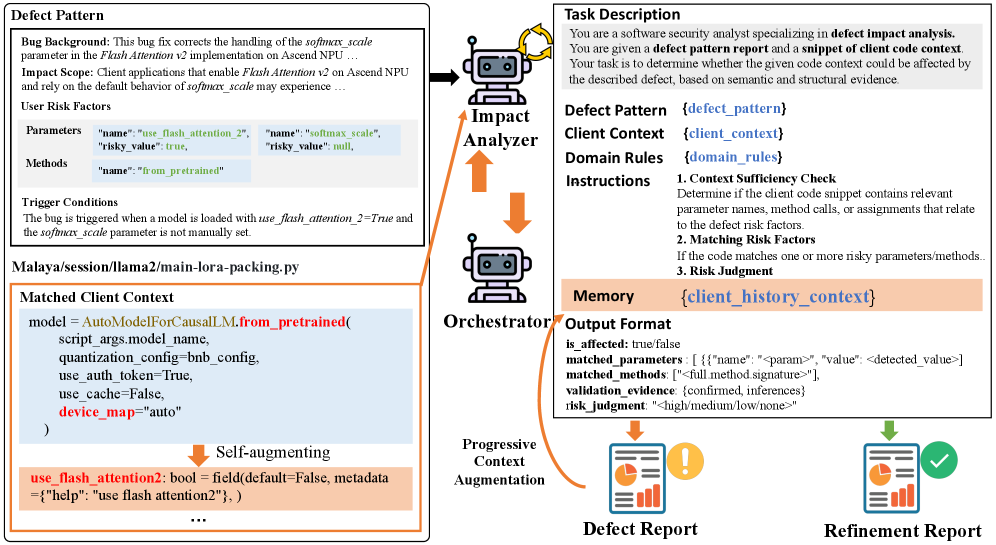
DepRadar utilizes a ‘Defect Pattern’ to standardize defect representation, encompassing three core elements: the nature of the bug itself, the scope of its potential impact-defined by affected functionalities or components-and the specific ‘Trigger Conditions’ that activate the defect. This structured approach moves beyond simple bug reports by explicitly modeling the relationship between the defect and the circumstances under which it manifests. Each pattern serves as a discrete unit of analysis, enabling automated reasoning about defect propagation and impact assessment across dependent systems. The formalized structure allows for consistent categorization, efficient querying, and the application of automated analysis techniques to predict and mitigate potential issues.
Trigger Conditions within the DepRadar framework function as specific criteria used to evaluate if a given defect propagates to client applications. These conditions are not simply boolean flags, but rather defined statements examining the runtime behavior or code characteristics of downstream programs. Evaluation involves verifying the presence of specific function calls, parameter values, or data dependencies within the client code that, when present, indicate the defect will manifest as an issue. The accuracy of defect impact assessment relies heavily on the precision of these Trigger Conditions, which are designed to minimize both false positives and false negatives in determining affected client programs.
AST (Abstract Syntax Tree) analysis is a static analysis technique used by DepRadar to determine the presence of specific parameters and methods within client program code. This process involves parsing the source code into an AST, a tree-like representation of the code’s structure, allowing for programmatic examination of code elements without executing the program. By verifying the existence of these elements, DepRadar accurately assesses the impact of a defect; a defect is only flagged as affecting a client program if the relevant parameters or methods are demonstrably present in its codebase. This method avoids false positives that could occur with simpler text-based searches and provides a more reliable basis for impact assessment.
From Commits to Consequences: Linking Changes to Underlying Defects
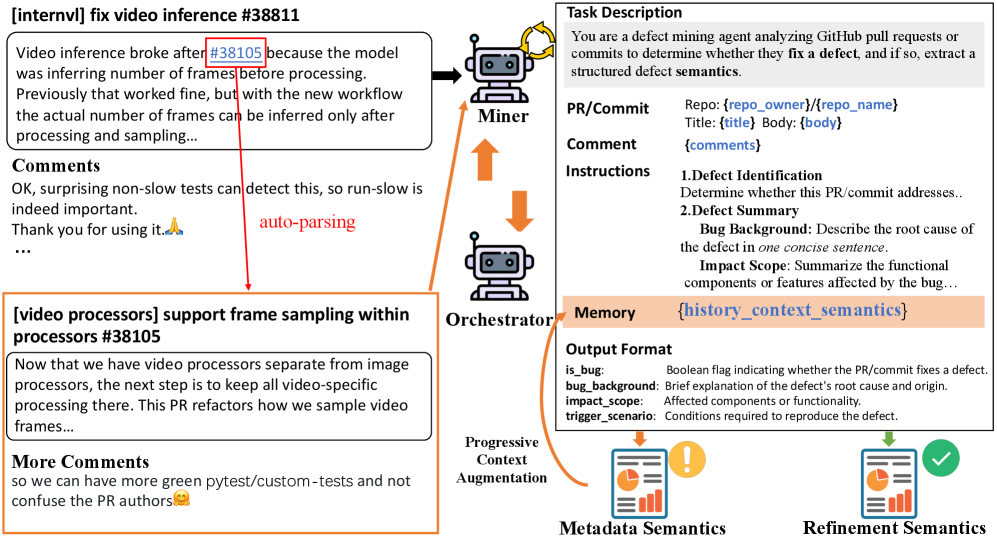
DepRadar utilizes integration with source code management systems – including support for common repositories – to monitor commits and pull requests. This integration allows the system to identify changes explicitly linked to defect resolution. Specifically, DepRadar analyzes commit messages, associated issue tracker tickets (e.g., Jira, GitHub Issues), and code modifications to determine if a change is intended as a fix for a reported defect. The system filters out commits related to features, documentation, or refactoring, focusing solely on those addressing identified bugs or vulnerabilities. This process enables traceability from code changes to the defects they resolve, providing quantifiable metrics on code quality and the effectiveness of defect resolution efforts.
The Code Diff Analyzer Agent operates by parsing the semantic differences between code versions presented in a patch. This analysis identifies specifically which methods were modified within the commit or pull request. The agent then generates a concise summary of the fix logic implemented in those modified methods, focusing on the functional change achieved. This summary is not a line-by-line description, but rather a higher-level explanation of what the code change accomplishes, enabling rapid understanding of the defect resolution without requiring a full code review. The agent leverages abstract syntax tree (AST) analysis and control flow graph examination to determine the impact of the modifications.
Context Augmentation is a technique employed to manage the input size for Large Language Models (LLMs) when analyzing code changes. LLMs have token limits, restricting the amount of text they can process in a single request. This process dynamically adjusts the information provided to the LLM by either expanding prompts with relevant details – such as surrounding code or commit metadata – or compressing them by summarizing lengthy sections. The goal is to ensure the LLM receives a complete and informative prompt without exceeding its token limit, thereby optimizing performance and the accuracy of defect analysis related to code commits and pull requests.

Towards Proactive Defect Mitigation: Shifting from Reaction to Prevention
Traditional defect analysis relies heavily on manual inspection, a process often limited by scale and prone to overlooking subtle, yet critical, issues within AI models. DepRadar addresses these limitations through automated analysis, shifting the paradigm from reactive bug fixing to proactive defect mitigation. By systematically scanning model components and their interactions, the framework identifies potential vulnerabilities before deployment, reducing the risk of performance degradation or unexpected behavior in real-world applications. This capability is particularly valuable as AI systems become increasingly complex, where manual review struggles to keep pace with the rate of development and the sheer volume of code. The result is a more reliable and robust AI lifecycle, minimizing costly errors and enhancing user trust.
The deployment of artificial intelligence systems often carries the hidden risk of ‘Silent Defects’ – subtle flaws within a model that aren’t immediately apparent but can lead to significant failures post-launch. DepRadar addresses this challenge with an automated framework designed to drastically reduce this risk and bolster overall system reliability. Achieving a reported 96% precision in defect classification, the system accurately identifies problematic areas within a model. Crucially, it extends beyond simple detection, providing an impact analysis with 80% precision, allowing developers to prioritize remediation efforts based on the severity of potential consequences. This high degree of accuracy enables a shift from reactive debugging to proactive defect mitigation, ultimately fostering greater confidence in the performance and stability of deployed AI.
DepRadar is engineered for seamless adoption within established software development practices. Its modular architecture facilitates straightforward integration into existing continuous integration and continuous delivery (CI/CD) pipelines, allowing for automated defect analysis at various stages of the development lifecycle. This design avoids the need for substantial workflow overhauls, minimizing disruption and accelerating time-to-value. Developers can readily incorporate DepRadar’s analysis as a standard step in their build and testing processes, enabling early and frequent detection of potential issues before they escalate into costly errors or compromise model performance. The framework’s adaptability ensures that organizations can leverage its capabilities without requiring significant investment in retraining or infrastructure changes.
The pursuit of reliable deep learning systems, as demonstrated by DepRadar’s agentic approach to defect impact analysis, echoes a fundamental tenet of elegant engineering. Grace Hopper observed, “It’s easier to ask forgiveness than it is to get permission.” This resonates with DepRadar’s proactive stance; rather than awaiting failures to surface, the framework systematically explores the dependency graph to anticipate potential disruptions stemming from library modifications. By intelligently coordinating agents to trace the flow of data and control, DepRadar minimizes the need for reactive debugging – a sentiment aligning with Hopper’s preference for decisive action and preemptive problem-solving. The system’s ability to understand code dependencies exemplifies the value of clear, self-evident logic.
What Remains?
The automation of dependency analysis, as demonstrated, addresses a symptom, not the disease. Deep learning libraries accrue complexity at a rate that exceeds comprehension. DepRadar offers a temporary reprieve, a map drawn in shifting sands. The true challenge lies not in tracking impact, but in reducing the surface area for impact to occur. Simpler libraries, designed with predictable behavior, obviate the need for such elaborate tracing.
Current limitations reside in the inherent ambiguity of code semantics. LLMs, while adept at pattern matching, lack genuine understanding. Their pronouncements are statistically informed guesses, prone to silent failures. Future work must confront this epistemological hurdle. Perhaps a shift in development paradigm-towards formally verified components-offers a more robust, if less expedient, solution.
Ultimately, the pursuit of perfect impact analysis is a fool’s errand. The system will always be an approximation of reality. The value lies not in eliminating uncertainty, but in quantifying it. A framework that reliably states what it cannot know may prove more useful than one that confidently asserts falsehoods.
Original article: https://arxiv.org/pdf/2601.09440.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
- Crimson Desert Guide – How to Pay Fines, Bounties & Debt
2026-01-16 04:21