Author: Denis Avetisyan
A new approach leverages compositional data analysis to monitor evolving software systems and maintain reliable observability.
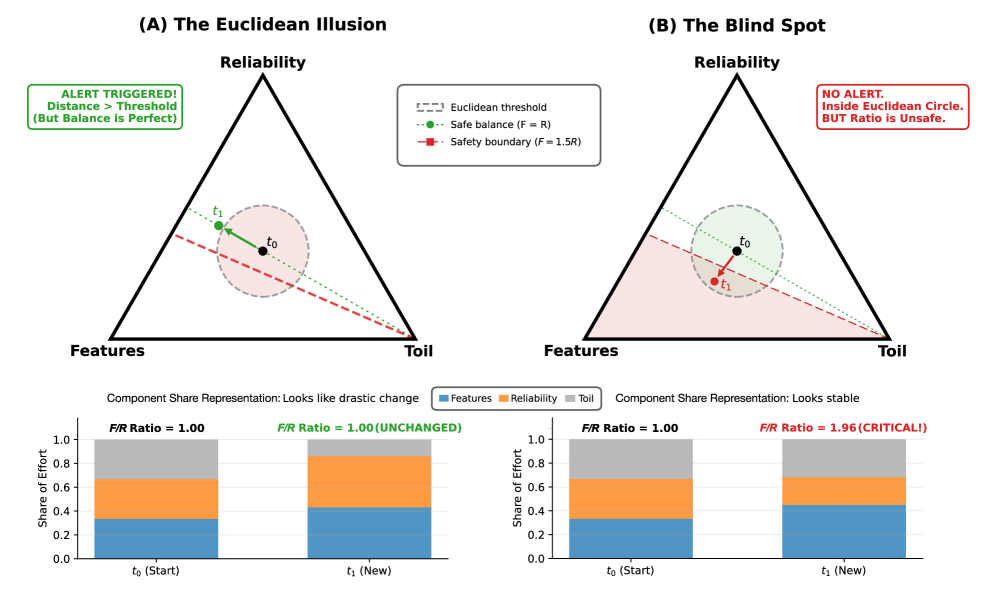
This paper introduces a method for detecting operational drift in microservices architectures using Aitchison geometry and simplex-based representations of system state.
Detecting subtle degradation in complex systems is challenged by conventional anomaly detection which struggles with compositional signals and rapidly evolving architectures. This paper, ‘Toward Operationalizing Rasmussen: Drift Observability on the Simplex for Evolving Systems’, proposes a novel approach to monitoring system health by representing operational state as compositions on a simplex and leveraging Aitchison geometry to stabilize drift detection under architectural churn. By modeling drift as movement within this compositional space, the work offers coordinate-invariant diagnostics for assessing proximity to failure boundaries. Could this framework enable more proactive and reliable site reliability engineering in the face of increasingly dynamic microservice environments?
The Inevitable Failure of Static Observation
Conventional monitoring systems, designed for static infrastructure, increasingly falter when applied to the fluid environments characteristic of modern software, particularly within a Microservice Architecture. These architectures, built from independently deployable services, introduce a level of complexity that renders fixed thresholds and reactive alerts largely ineffective. The very nature of microservices – constant updates, scaling operations, and intricate inter-service communication – generates a baseline of continuous change, obscuring genuine anomalies. Consequently, alerts often prove to be false positives, desensitizing operations teams, or, conversely, fail to identify emerging issues hidden within the noise of normal variation. This inability to adapt to dynamic behavior necessitates a fundamental rethinking of how systems are observed and managed, moving beyond simply reacting to problems as they occur towards anticipating and preventing them.
Conventional monitoring systems, reliant on predefined static thresholds, frequently fail to address the intricacies of contemporary software environments. These systems typically react after a problem manifests, triggering alerts based on breached limits – a fundamentally reactive approach. However, modern applications, particularly those built with a μservice architecture, exhibit constantly shifting states and complex interdependencies. This dynamism means a threshold appropriate at one moment may be irrelevant the next, leading to both false positives and, critically, missed genuine issues. The sheer number of potential interaction pathways within these systems exponentially increases the likelihood of unforeseen consequences, rendering static rules inadequate for anticipating problems before they impact the end user. Consequently, a paradigm shift is necessary, moving beyond simply responding to symptoms towards predicting and preventing failures through a deeper understanding of system behavior.
Modern software systems, particularly those built on microservice architectures, demand a departure from traditional reactive monitoring strategies. Instead of simply responding to incidents, a proactive approach leveraging system models is crucial for anticipating and mitigating issues before they affect users. This involves constructing representations of normal system behavior, allowing for the detection of anomalies and the prediction of potential boundary events – instances where performance degrades or failures occur. The effectiveness of such a system hinges on achieving a quantifiable minimum lead time, denoted as ℓ_{min}, representing the duration between the prediction of an event and its actual occurrence. A sufficiently large ℓ_{min} enables intervention – such as resource scaling or request rerouting – preventing negative user experiences and ensuring system resilience. Consequently, the focus shifts from merely observing symptoms to understanding underlying causes and forecasting future states, ultimately transforming monitoring from a reactive cost center into a proactive capability.
A Model of Safety as Transient Equilibrium
The Dynamic Safety Model departs from traditional safety paradigms by conceptualizing safety not as a static condition, but as an emergent property resulting from the ongoing negotiation between competing system gradients and localized adaptations. This means that safety is not achieved by simply maintaining a predetermined state, but rather by continuously balancing opposing forces within a complex system. These gradients represent inherent tendencies toward deviation or failure, while local adaptations are the system’s responses to maintain equilibrium. Consequently, safety is a function of this dynamic interplay, requiring ongoing monitoring and adjustment rather than a one-time fix. The model posits that safety is therefore a temporary equilibrium, constantly shifting in response to internal and external pressures.
Assessment of Boundary Proximity involves continuous monitoring of system states relative to established operational limits, shifting the focus from reactive incident investigation to proactive risk management. This necessitates defining quantifiable boundaries for critical system parameters and implementing real-time measurement capabilities. Rather than solely addressing constraint violations after they occur, the Dynamic Safety Model prioritizes identifying trends and deviations that indicate increasing proximity to these boundaries. This allows for intervention and adjustment before a breach occurs, minimizing potential harm and maintaining system integrity. Techniques for assessing proximity include statistical process control, predictive modeling, and the implementation of early warning systems based on pre-defined threshold values and drift rates.
Proactive safety systems prioritize identifying the root causes of system drift rather than solely responding to incidents. This is achieved by modeling system behavior as the result of multiple interacting balances, designated as ‘k’, each representing a contributing factor to overall drift. The goal is to attribute a significant portion – at least p% – of the total observed drift energy to these identified balances. By focusing on a limited number of key factors, these systems aim to simplify complexity and enable predictive interventions before violations occur; this contrasts with reactive approaches that address issues only after boundaries are crossed. The percentage ‘p’ and the number of balances ‘k’ represent tunable parameters defining the sensitivity and scope of the proactive safety model.
Inferring System Behavior from Established Artifacts
Artifact-Grounded Model Inference utilizes readily available system documentation – termed ‘Artifacts’ – to construct simplified, analytically tractable models of operational behavior. These Artifacts encompass deployment specifications, detailing system configuration, and Service Level Objectives (SLOs), which define expected performance characteristics. The inference process extracts key parameters and relationships from these sources, creating a model representing the system’s intended operating point. This approach avoids reliance on live traffic data for initial model creation, enabling drift detection even during periods of low activity or before system launch. The resulting models are designed to be lightweight, prioritizing ease of analysis and rapid comparison to historical data, rather than comprehensive system simulation.
Model-Induced Compositions function as a dynamic representation of the system’s current operating point, capturing the relationships between key components and their expected behaviors. These compositions are generated from observed system artifacts and are not static; they are continuously updated to reflect the live system state. This continuous updating is the basis for Drift Monitoring, allowing for real-time comparison against established baseline models. Deviations between the current composition and historical baselines are flagged as potential drift, providing actionable signals for investigation and remediation. The granularity of these compositions allows for precise identification of the source of drift, moving beyond simple aggregate metrics to pinpoint specific behavioral changes.
Drift detection utilizes the comparison of currently observed `Model-Induced Composition`s to previously established historical baselines. This comparison identifies deviations in system behavior, enabling proactive identification of potential issues before they impact service. A key focus of this approach is the minimization of false positive alerts; traditional drift detection methods often trigger alerts based on minor, inconsequential changes. By leveraging artifact-grounded models, the system can differentiate between genuine behavioral shifts indicative of a problem and normal operational variance, thereby reducing alert fatigue and improving the efficiency of incident response.
Stabilizing Observation in Evolving Systems
Lineage-aware aggregation addresses drift monitoring instability in dynamic systems by maintaining a historical record of component relationships and dependencies. This approach moves beyond simple point-in-time comparisons by tracking how data flows and transforms as the architecture evolves. Each data point is associated with its originating component and any subsequent processing steps, allowing the monitoring system to adapt to changes such as component replacements, scaling events, or modifications to data pipelines. By aggregating drift metrics based on this lineage information, the system can accurately identify the root cause of performance changes and distinguish between genuine drift and artifacts caused by architectural shifts. This historical context is crucial for maintaining the effectiveness of drift detection in environments where components are frequently updated or replaced, ensuring that alerts reflect actual behavioral changes rather than system topology changes.
Defining Service Level Objectives (SLOs) as code establishes a formalized, machine-readable specification of expected system behavior. This approach moves beyond manually maintained SLO documentation by representing SLOs as executable definitions – typically expressed in YAML or similar formats – that can be integrated directly into monitoring and alerting pipelines. The resulting benefits include automated validation of SLO adherence, reduced risk of human error in SLO interpretation, and enhanced reproducibility of drift detection results. Furthermore, SLO-as-Code facilitates version control and collaborative management of SLOs, enabling consistent application of performance criteria across evolving system architectures and facilitating accurate assessment of drift against clearly defined, auditable targets.
Compositional Data Analysis (CDA) offers a geometrically sound approach to drift detection by treating system metrics as parts of a whole, rather than independent variables. Traditional statistical methods can be inaccurate when analyzing compositional data due to the inherent constraints-summing to one-and interdependence of the variables. CDA, leveraging Aitchison Geometry and transformations like Log-Ratio Coordinates, addresses these limitations. Log-Ratio Coordinates, specifically, transform compositional data into a Euclidean space, enabling the application of standard statistical techniques while preserving the relationships between components. The proposed framework validates this approach by demonstrating quantifiable detection delays greater than or equal to ℓ_{min}, indicating the effectiveness of CDA in accurately identifying and responding to system drift within evolving architectures.
Mapping Systemic Vulnerability Through Risk Share
A system’s inherent vulnerabilities can be mapped and understood through the construction of a Risk Share Composition, derived from its underlying Service Graph. This composition doesn’t simply identify potential failure points; it quantifies the degree to which each service contributes to overall system risk, revealing how a disruption in one area propagates to others. By representing risk as a distributed property across interconnected services, teams gain insight into which components demand the most attention and investment in resilience. The result is a dynamic visualization of systemic vulnerability, enabling proactive mitigation of potential cascading failures and improved resource allocation based on actual risk exposure, rather than perceived criticality.
The creation of a visual representation of system risk allows for the anticipation of potential failure points and performance limitations before they manifest as widespread issues. By mapping dependencies and quantifying the impact of service disruptions, critical components – those whose failure would cascade and significantly affect overall system health – become immediately apparent. This proactive approach extends beyond simply identifying these key services; it also reveals potential bottlenecks where concentrated risk resides. Understanding these chokepoints enables teams to strategically allocate resources, implement preventative measures, and develop mitigation strategies, ultimately bolstering system resilience and minimizing the blast radius of any single point of failure. This capability moves beyond reactive troubleshooting to a predictive posture, fostering a more stable and reliable system operation.
Combining error budget monitoring with comprehensive risk assessments offers a powerful pathway to enhanced system resilience and proactive management. By tracking allowable error rates-the \geq \ell_{min} threshold- alongside the potential impact of service failures, teams gain crucial insights for informed decision-making. This integrated approach moves beyond simply identifying vulnerabilities; it enables optimized resource allocation, prioritizing areas where increased investment will yield the greatest reduction in risk. The result is a framework designed not only to minimize the time it takes to detect issues-reducing mean time to detection-but also to prevent unnecessary alerts and maintain a consistently low false positive rate, ultimately fostering a more stable and reliable system.
The pursuit of reliable system monitoring, as detailed in this work, demands a rigorous mathematical foundation. The proposed use of compositional data analysis and Aitchison geometry to represent operational state on a simplex offers precisely this – a deterministic framework for drift detection. This approach moves beyond merely observing that a system has changed, to quantifying how it has changed in a provable manner. As Carl Sagan observed, “Somewhere, something incredible is waiting to be known.” This sentiment applies perfectly; by employing mathematical purity, the research strives to uncover the underlying truths of system behavior, transforming ephemeral observations into reliable, reproducible knowledge about evolving architectures and ultimately bolstering system stability.
What Lies Ahead?
The presented work, while offering a geometrically sound methodology for drift detection, merely scratches the surface of a far more fundamental challenge. Representing operational state as compositions on a simplex is elegant, certainly, but the true test resides in formally demonstrating its completeness. A system’s health isn’t merely a matter of compositional shifts; it’s a topological problem, demanding a rigorous understanding of the state space’s manifold structure. Current approaches, relying on empirical observation of drift, are akin to charting an ocean with a sextant – useful, perhaps, but lacking the predictive power of a complete hydrodynamic model.
Future investigations should prioritize the development of provably correct algorithms for identifying and isolating the root causes of drift, rather than simply flagging its presence. A drift alert, devoid of diagnostic precision, is little more than noise. Moreover, the extension of Aitchison geometry to encompass more complex compositional relationships – beyond simple ratios – is crucial. Real-world systems aren’t built on perfectly balanced components; they are messy, interconnected, and often exhibit non-linear behavior. The simplex, in its current form, may prove insufficient to capture this complexity.
Ultimately, the pursuit of operational observability must transcend the limitations of ad-hoc monitoring and embrace the principles of formal verification. A system’s health isn’t something to be inferred; it’s something to be proven. Only then can the promise of truly reliable, self-stabilizing systems be realized – a goal, it must be admitted, that has eluded engineers for far too long.
Original article: https://arxiv.org/pdf/2602.05483.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Mewgenics vinyl limited editions now available to pre-order
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- TikToker’s viral search for soulmate “Mike” takes brutal turn after his wife responds
- All Golden Ball Locations in Yakuza Kiwami 3 & Dark Ties
2026-02-08 10:52