Author: Denis Avetisyan
A new framework dissects how AI systems like those powered by retrieval-augmented generation arrive at their answers, offering unprecedented insight into their reasoning.
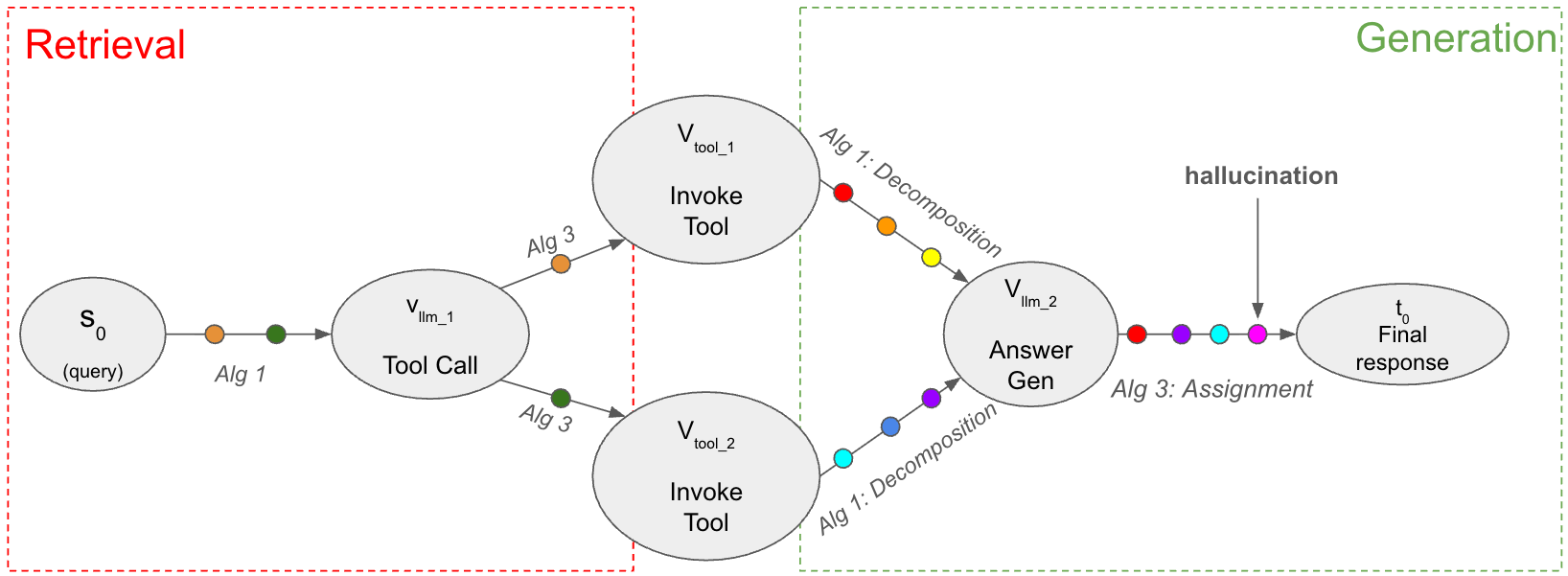
This paper introduces Atomic Information Flow, a network-flow model for attributing information in RAG systems at the atomic level to improve tool attribution, interpretability, and context compression.
As Retrieval-Augmented Generation (RAG) systems grow in complexity, tracing the provenance of final responses through multi-tool workflows remains a critical challenge. To address this, we introduce Atomic\ Information\ Flow\ (AIF), a network flow model for attributing information in RAG systems at a granular, atomic level. By modeling LLM orchestration as a directed flow of information, AIF enables improved tool attribution and interpretability, and-when paired with a lightweight language model-achieves significant context compression, boosting accuracy by over 28 points on HotpotQA. Could this framework unlock more efficient and transparent RAG systems capable of pinpointing the precise origins of their reasoning?
Deconstructing the Black Box: The Limits of Contextual Understanding
Traditional Retrieval-Augmented Generation (RAG) systems, while effective for straightforward queries, often falter when faced with tasks demanding complex reasoning. This limitation stems from the “opaque context window” – the large block of retrieved text fed into the language model. The model treats this context as a monolithic entity, lacking the ability to discern which specific pieces of information are truly relevant to the question at hand. Consequently, crucial details can be lost within the volume of text, or irrelevant information can distract the model, leading to inaccurate or poorly supported answers. Essentially, the system struggles to synthesize knowledge effectively because it lacks a granular understanding of the contextual information, hindering its ability to perform nuanced inference and problem-solving.
Increasing the size of the context window in Retrieval-Augmented Generation (RAG) systems, while seemingly a direct path to improved performance, quickly encounters practical limitations. The computational cost of processing extended contexts grows disproportionately, demanding significantly more memory and processing power – a challenge for deployment at scale. More critically, simply providing a larger context doesn’t inherently improve the quality of the generated response or its faithfulness to the source material. Research indicates diminishing returns, where the gains in fidelity and attribution plateau, and can even decline as the model struggles to discern relevant information within the expanded, and potentially noisy, context. This suggests that effective RAG isn’t solely about ‘more’ context, but about intelligently selecting and utilizing the right information – a far more nuanced undertaking.
Current Retrieval-Augmented Generation (RAG) systems often treat context as a monolithic block of text, failing to discern which specific pieces of information are genuinely pivotal in formulating an answer. This lack of granularity creates a significant impediment to building trustworthy AI; without understanding why a system arrived at a particular conclusion, assessing its reliability becomes exceedingly difficult. The systems ingest potentially vast quantities of data, but lack the capacity to pinpoint the precise evidence driving the generation process, leading to outputs that, while seemingly coherent, may rest on tenuous or irrelevant foundations. Consequently, users are left with limited ability to validate the reasoning or trace the origin of claims, hindering adoption in critical applications where accountability and transparency are paramount.
Establishing clear provenance for text generated by Retrieval-Augmented Generation (RAG) systems proves remarkably difficult, particularly as these pipelines grow in complexity. While RAG aims to ground responses in source documents, tracing the precise influence of specific passages on the final output is often obscured by multiple retrieval steps, transformations, and the generative model itself. This lack of granular attribution hinders trust and accountability; users cannot easily verify the basis of a claim or identify potential biases introduced during the process. Current methods frequently offer only document-level attribution, falling short of pinpointing the specific sentences or phrases that drove a particular conclusion. Consequently, ensuring the reliability and transparency of RAG-generated content requires innovative approaches to tracking information flow and highlighting the evidentiary basis for each statement.

Atomic Information Flow: Unraveling the Logic Within
Atomic Information Flow (AIF) defines information not as continuous data streams, but as discrete ‘Atoms’ representing the smallest units of semantic meaning. These Atoms are self-contained and explicitly defined, enabling precise tracking and analysis of information propagation. Each Atom encapsulates a single, verifiable piece of knowledge, such as a fact, observation, or logical deduction, and is designed to be independent of its source or context initially. This granular representation contrasts with traditional methods where information is often represented as unstructured text or embeddings, and allows for a deterministic model of knowledge transfer within a larger system.
Atomic Information Flow (AIF) conceptualizes reasoning as information propagating through a directed graph. This graph comprises two primary node types: LLM Nodes, which encapsulate Large Language Model operations such as text generation or analysis, and Tool Nodes, representing external functions like API calls or data retrievals. Information, represented as ‘Atoms’, moves from node to node along defined edges, indicating data dependencies. The structure allows for tracking the precise path of each Atom as it contributes to the final output, establishing a clear lineage of information processing within the system. This ‘Flow’ is not simply a sequential process, but a network where Atoms can be processed by multiple nodes and contribute to multiple subsequent steps.
Tracking information as discrete Atoms allows for a detailed analysis of its contribution to the final output. Each Atom represents a specific piece of knowledge or a computational step, and its propagation through the system – from Large Language Model (LLM) Nodes to Tool Nodes and back – is recorded. This enables precise attribution: identifying exactly which Atoms influenced specific parts of the reasoning process and ultimately, the generated answer. By examining the lineage of each Atom, developers can pinpoint the source of correct or incorrect information, and assess the relative importance of different data points or tool executions in arriving at the final result. This granular visibility facilitates debugging, performance optimization, and a deeper understanding of the LLM’s internal logic.
Tracking information at the level of individual semantic units – Atoms – enables precise attribution of specific data points to the LLM’s final output. This granular tracking moves beyond simply identifying which tools were used; it reveals how specific information propagated through the system, connecting initial data inputs to the reasoning steps performed by LLM Nodes and Tool Nodes. Consequently, developers can pinpoint the exact source and influence of each piece of information, enhancing the interpretability of the LLM’s decision-making process and facilitating debugging or refinement of the system’s reasoning capabilities. This targeted attribution is crucial for building trust and accountability in LLM-driven applications.
Directed Compression: Sculpting Context for Optimal Reasoning
Atom Information Filtering (AIF) employs the ‘Minimum Cut’ algorithm, a graph theory technique, to determine and eliminate redundant Atoms – discrete units of information – within a context window. This process identifies Atoms whose removal has a minimal impact on the overall connectivity and information flow related to answering a specific question. The algorithm operates by calculating the minimum capacity cut separating Atoms, effectively partitioning the context while preserving critical relationships necessary for accurate response generation. By removing Atoms below this cut threshold, AIF reduces context length without sacrificing the ability to derive the correct answer, as the remaining Atoms maintain sufficient connectivity to support reasoning.
AIF reduces computational costs and improves response times by selectively removing redundant information from the input context. This process minimizes the number of tokens processed by the language model without sacrificing answer accuracy. By decreasing the input sequence length, AIF directly lowers the demand on both memory and processing power, leading to faster inference speeds. This is particularly beneficial for resource-constrained environments and applications requiring real-time responses, as demonstrated by token reductions ranging from 65.83% to 90.72% across various datasets.
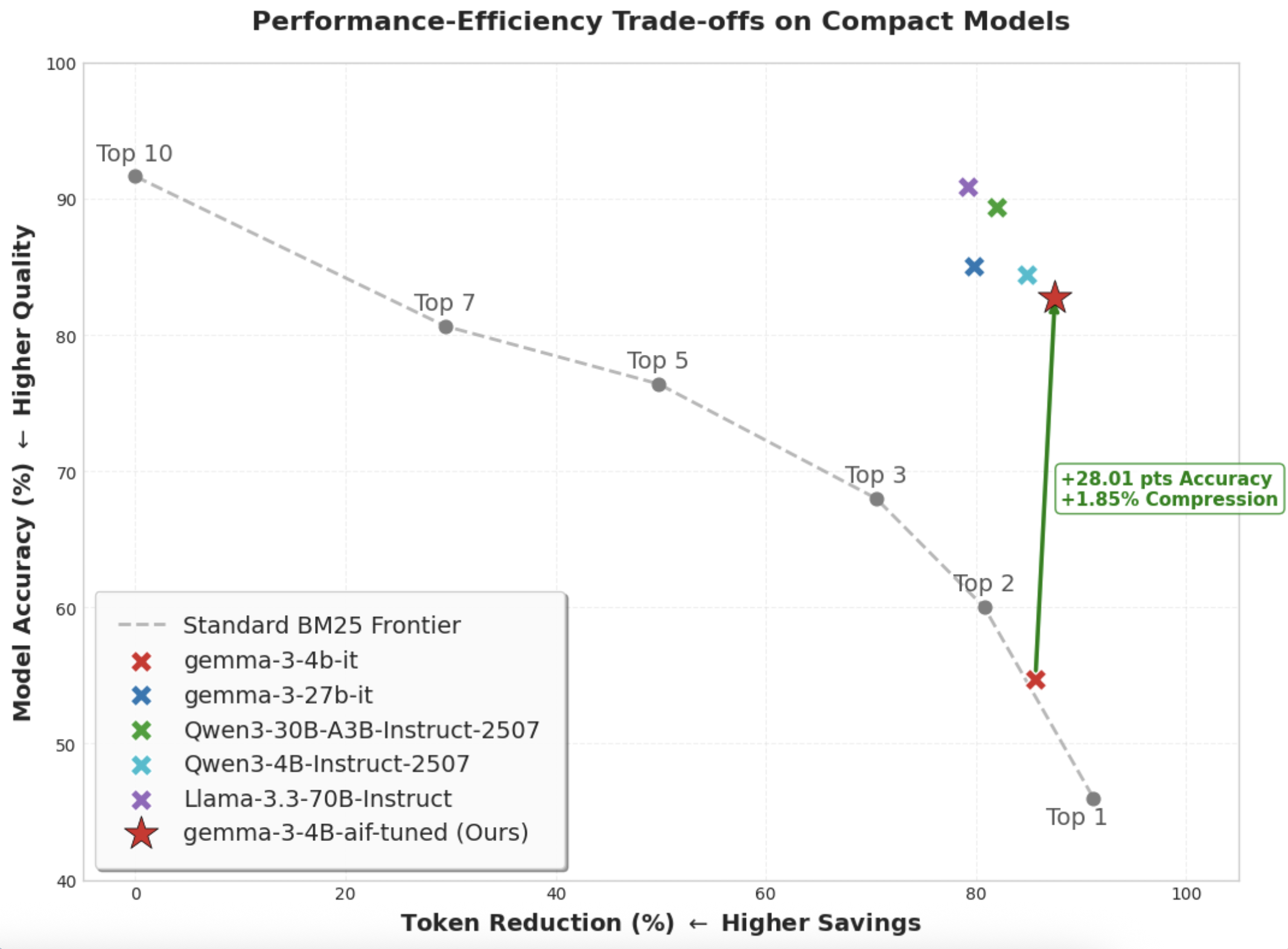
Evaluations using the Gemma3-4B model demonstrate the efficacy of Directed Information Compression in enhancing question answering performance. Specifically, the approach accurately identifies optimal subsets of contextual tools for compression, leading to a measured accuracy improvement of up to 33.30% on the HotPotQA dataset. This improvement indicates the model’s ability to effectively retain critical information while discarding redundancy, ultimately boosting its performance on complex reasoning tasks.
Targeted compression within complex reasoning pipelines achieves substantial reductions in token count, ranging from 65.83% to 90.72% across varied datasets. This efficiency gain is achieved by strategically removing redundant or irrelevant information prior to processing, thereby decreasing computational load and accelerating inference speeds. Evaluation across multiple datasets demonstrates consistent performance improvements resulting from this targeted approach to context reduction, allowing for more efficient utilization of resources without sacrificing accuracy.
Validating the Framework: Rigorous Benchmarking and Performance Metrics
Artificial Intelligence Framework (AIF) exhibits robust performance across several established Question Answering (QA) datasets. Specifically, AIF has been evaluated on WikiMultihopQA, MS MARCO, and HotPotQA, demonstrating its capacity to handle complex, multi-hop reasoning and information retrieval tasks. These datasets represent diverse challenges in QA, including knowledge-intensive tasks and the need to synthesize information from multiple sources. Performance on these benchmarks indicates AIF’s ability to generalize and maintain accuracy when faced with varied question types and knowledge domains, establishing a baseline for further improvements and comparative analysis against other QA models.
Attribution fidelity was assessed using the DeepResearch Bench and ALCE datasets. DeepResearch Bench evaluates the ability to correctly identify supporting documents for a given claim, while ALCE measures the alignment between model attributions and human rationales. Evaluations on these benchmarks demonstrate that AIF improves source fidelity by more accurately pinpointing the specific text spans within source documents that justify its responses, indicating a reduction in irrelevant or unsupported attributions compared to baseline models. This enhanced fidelity contributes to increased trustworthiness and interpretability of the AI system’s outputs.
FactScore is a metric used to evaluate the groundedness of generated text by assessing the ratio of supported atomic facts within the response. Evaluations utilizing FactScore demonstrate that AIF consistently maintains a high proportion of verifiable factual claims. This indicates that AIF-generated content is not only coherent but also strongly anchored in supporting evidence, minimizing the occurrence of unsupported or hallucinated information. The metric operates by identifying atomic facts within a generated response and then verifying their presence in supporting source documents, providing a quantitative measure of factual consistency.
Application of AIF-based compression techniques to the MS MARCO dataset resulted in a 14.41% increase in token reduction. Prior to AIF integration, the dataset achieved a 51.9% token reduction rate; post-implementation, this rate increased to 66.31%. This improvement indicates a significant enhancement in data compression efficiency, potentially leading to reduced storage requirements and faster processing times when utilizing the MS MARCO dataset for model training and evaluation.
Evaluation of the AIF-trained Gemma3-4B model on the HotPotQA dataset demonstrates a significant improvement in accuracy. Performance gains range from +19.89% to +33.30% depending on the specific configuration and training parameters utilized. This improvement indicates AIF’s effectiveness in enhancing the model’s ability to accurately answer multi-hop reasoning questions, as assessed by the HotPotQA benchmark which requires identifying supporting facts from multiple documents to arrive at a correct answer.

Beyond Explanation: Toward Truly Trustworthy Artificial Intelligence
Artificial Intelligence Frameworks (AIF) are revolutionizing explainable AI (XAI) through an unprecedented level of detail in tracking information pathways. Unlike traditional methods that offer a broad overview of decision-making, AIF dissects the process into granular steps, revealing precisely how each piece of information contributes to an outcome. This detailed understanding isn’t simply about identifying what an AI concluded, but how it arrived at that conclusion, tracing the journey of data from its origin through each layer of processing. By mapping these information flows, AIF allows for pinpoint accuracy in identifying influential factors, potential biases, and the logical connections that underpin AI reasoning – ultimately fostering greater transparency and trust in complex systems.
Large language models often arrive at conclusions without revealing how they did so, creating a ‘black box’ effect that hinders trust and responsible deployment. However, advancements in tracing information flow within these models are beginning to address this challenge. By pinpointing the precise sources that contributed to a specific output – identifying which data points influenced each reasoning step – it becomes possible to audit the model’s logic. This capability isn’t merely about explanation; it establishes accountability. If an LLM generates a biased or inaccurate response, the traceable pathway allows developers to pinpoint the problematic data or reasoning flaw, fostering iterative improvements and building confidence in the system’s reliability. Ultimately, this move toward source-attribution represents a paradigm shift, enabling users to move beyond simply accepting an LLM’s output to critically evaluating and understanding the basis for its conclusions.
Artificial Intelligence Frameworks (AIF) offer a crucial mechanism for addressing the pervasive issue of bias within large language models, not merely by detecting its presence, but by actively tracing its origins and spread. This framework analyzes information as it flows through the system, pinpointing instances where biased data or flawed reasoning contribute to skewed outputs. By meticulously mapping these propagation pathways, AIF enables developers to intervene at specific points, mitigating the impact of bias before it manifests in potentially harmful or unfair outcomes. This proactive approach goes beyond simply correcting outputs; it allows for refinement of the underlying data and algorithms, fostering a more equitable and trustworthy AI ecosystem where bias is systematically identified, addressed, and minimized throughout the entire information lifecycle.
The pursuit of artificial intelligence extends beyond simply achieving high performance; increasingly, the focus is shifting towards building systems that engender confidence and reliability. This research establishes a critical foundation for that future, moving past ‘black box’ models towards AI capable of demonstrating how conclusions are reached. By prioritizing transparency and accountability in information processing, the work facilitates the identification and correction of potential flaws – including biases – within AI reasoning. Ultimately, this approach promises a new generation of AI not merely defined by its capabilities, but also by its trustworthiness, enabling broader adoption and responsible innovation across diverse applications.
The pursuit of understanding, as demonstrated by this work on Atomic Information Flow, inherently involves a dismantling of established assumptions. This paper doesn’t simply accept the ‘black box’ nature of Retrieval-Augmented Generation systems; it dissects information propagation at a granular level, revealing how knowledge flows and compresses within the network. G.H. Hardy recognized this spirit of inquiry when he stated, “A mathematician, like a painter or a poet, is a maker of patterns.” This research mirrors that sentiment; it constructs a framework – a pattern – not to passively observe RAG systems, but to actively deconstruct and rebuild understanding of their internal mechanisms, ultimately allowing for more precise tool attribution and improved interpretability.
What’s Next?
The introduction of Atomic Information Flow (AIF) offers a compelling, if brutally honest, assessment of what RAG systems actually do with information. The framework’s insistence on tracking information at the atomic level, while computationally demanding, forces a reckoning with the inherent lossiness of even the most sophisticated retrieval and generation processes. AIF doesn’t simply identify that information is lost, but attempts to quantify where and how-a crucial step beyond surface-level interpretability metrics.
However, the model’s current reliance on graph network flows presents a clear bottleneck. Future work must address the scalability of these flows to truly massive knowledge bases, perhaps through approximation algorithms or novel data structures. More provocatively, the very notion of “atomic” information may prove insufficient; reality rarely adheres to neat, discrete units. The challenge lies in developing a framework that gracefully handles degrees of informational granularity-a continuous spectrum of relevance, rather than a binary state.
Ultimately, the best hack is understanding why it worked. Every patch, every compression algorithm, every attribution score is a philosophical confession of imperfection. AIF, by explicitly mapping these imperfections, provides not just a tool for debugging RAG systems, but a framework for interrogating the limits of information itself.
Original article: https://arxiv.org/pdf/2602.04912.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- Mewgenics vinyl limited editions now available to pre-order
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- TikToker’s viral search for soulmate “Mike” takes brutal turn after his wife responds
- ‘Timur’ Trailer Sees Martial Arts Action Collide With a Real-Life War Rescue
2026-02-08 02:31