Author: Denis Avetisyan
New research shows that combining the insights of prediction markets with large language models can significantly improve the accuracy of forecasting future events.
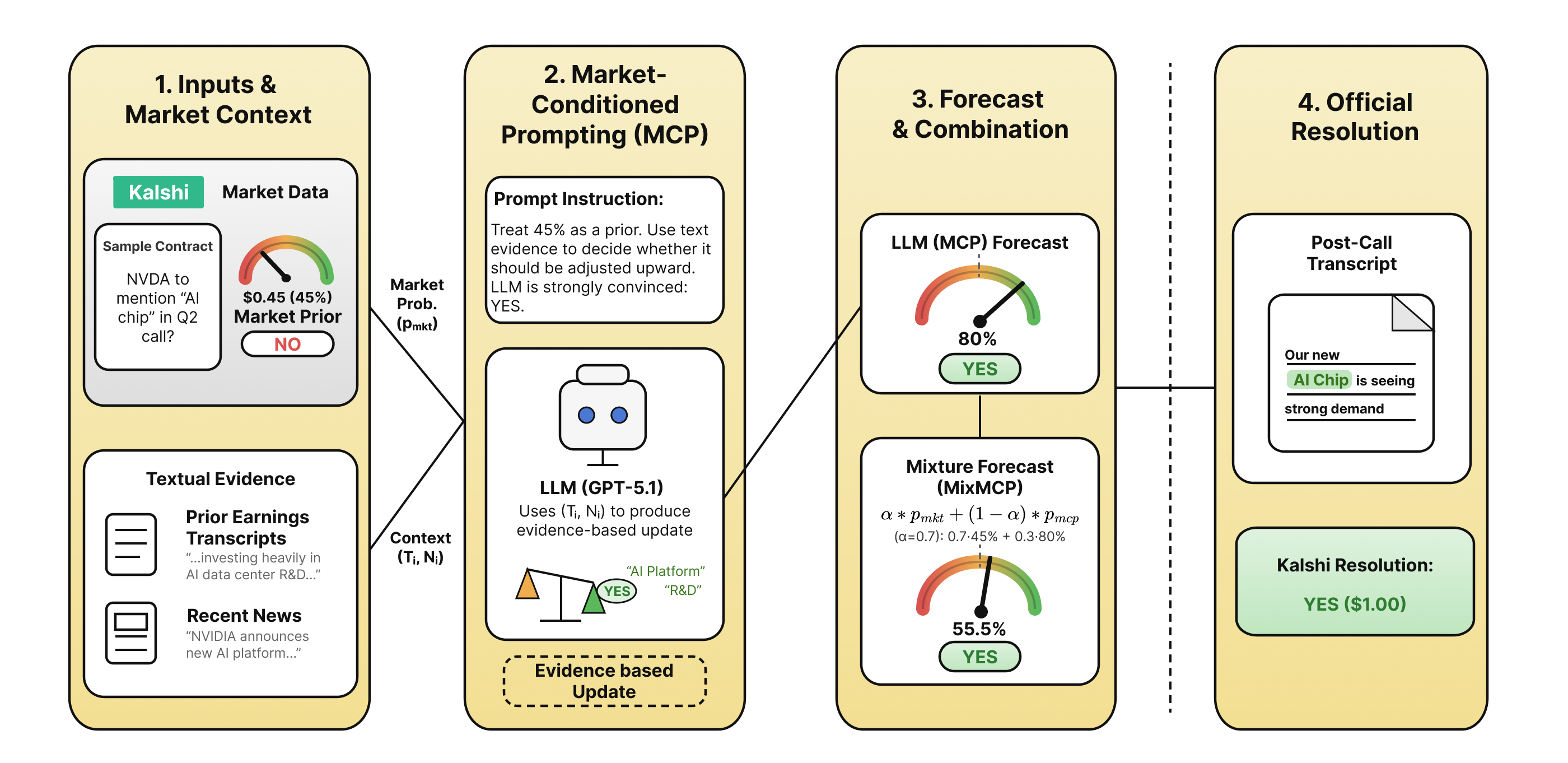
Text-grounded forecasting with market-conditioned prompting enhances probabilistic accuracy in prediction markets using large language models.
Accurate probabilistic forecasting remains a challenge in prediction markets, particularly when relying on complex textual data. This is addressed in ‘Forecasting Future Language: Context Design for Mention Markets’, which investigates how to best leverage large language models (LLMs) for forecasting keyword mentions in future events. The authors demonstrate that providing richer contextual information-news and prior transcripts-improves forecasting performance, and-crucially-that a novel ‘market-conditioned prompting’ approach, which treats existing market probabilities as a prior, yields better-calibrated and more robust predictions than either market baselines or LLMs alone. Will this method unlock more effective integration of LLMs into real-world forecasting and decision-making systems?
Unveiling Predictive Blind Spots: Beyond Isolated Data Streams
Conventional forecasting frequently operates with a narrowed focus, analyzing individual data streams – such as historical sales figures or quantitative market indicators – in relative isolation. This approach, while seemingly pragmatic, often overlooks the wealth of contextual information that surrounds and influences those numbers. Critical signals embedded in qualitative data, like shifts in consumer sentiment expressed on social media, or nuanced discussions within industry reports, are commonly disregarded. Consequently, predictions can become detached from the broader realities driving market behavior, leading to inaccurate assessments of risk and opportunity. The failure to acknowledge these interconnected signals represents a significant limitation, as predictive power is demonstrably enhanced when diverse data sources are integrated into a holistic model.
Predictive models frequently falter when built solely on quantitative data, overlooking a wealth of information embedded within pre-event textual sources. Research demonstrates that analyses of earnings call transcripts, news articles, and other textual communications reveal nuanced sentiment and emerging trends often missed by traditional metrics. These textual signals can act as early indicators of shifts in performance or risk, providing crucial context for probability assessments. Ignoring this data frequently results in inaccurate forecasts, as models fail to account for qualitative factors influencing outcomes – a missed opportunity to refine predictions and mitigate potential errors. The capacity to effectively process and integrate these textual insights is becoming increasingly vital for robust and reliable forecasting in complex environments.
Achieving truly accurate predictions demands more than simply accumulating data; the central difficulty lies in synthesizing information from disparate sources. Modern forecasting often treats numerical time series, textual reports, and even social media trends as independent entities, yet these streams are fundamentally interconnected. Effective integration requires not only advanced analytical techniques – such as natural language processing to extract sentiment from news articles and χ-squared tests to assess statistical dependencies – but also a framework that accounts for the inherent noise and biases within each source. The challenge isn’t just about having more data, but about intelligently weighting and correlating it to reveal underlying patterns and improve the reliability of probability assessments, ultimately moving beyond the limitations of isolated prediction models.

Harnessing the Wisdom of Crowds: Prediction Markets as a Foundation
Prediction markets function as forecasting tools by leveraging the diverse information and perspectives held by a group of individuals. Participants buy and sell contracts contingent on the outcome of a future event, establishing market prices that reflect the collective probability assessment of the crowd. This aggregation of individual judgments often outperforms traditional forecasting methods, including expert opinion and statistical models, due to the “wisdom of the crowd” effect. The underlying principle is that the errors of individual predictions tend to cancel each other out when averaged across a sufficiently large and diverse group, leading to more accurate probabilistic forecasts. These markets incentivize truthful reporting of beliefs through financial rewards, further enhancing the reliability of the aggregated signal.
Market Probability, as determined within a prediction market, represents the aggregated beliefs of a diverse group of participants regarding the likelihood of a specific event. This value is not a single individual’s assessment, but rather a weighted average of numerous independent predictions, typically expressed as a percentage or decimal between 0 and 1. The calculation relies on the market prices of contracts representing different event outcomes; for example, a contract predicting the occurrence of an event trading at $0.70 implies a 70% probability assigned by the market. This crowd-sourced probability benefits from the ‘wisdom of the crowd’ effect, where collective judgment often surpasses the accuracy of individual experts, provided participants have sufficient information and incentives to accurately express their beliefs.
While prediction market probabilities offer a valuable quantitative forecast, they often lack the contextual detail to fully explain why a particular outcome is anticipated. Qualitative data, such as news articles, expert opinions, and social media commentary, can provide this missing nuance. Integrating textual analysis alongside market signals allows for a more comprehensive understanding of the factors driving predictions, identifies potential biases within the market, and enables more informed decision-making. This combined approach moves beyond simply predicting what will happen to understanding why it might happen, increasing the overall utility of the forecasting process.
Evaluating the accuracy of probabilistic forecasts generated by prediction markets, or any forecasting system, requires specific metrics beyond simple accuracy rates. The Brier Score, ranging from 0 to 1 with lower values indicating better performance, measures the mean squared probability error between predicted probabilities and actual outcomes; a perfect score is 0. Expected Calibration Error (ECE) assesses the degree to which predicted probabilities align with observed frequencies – for instance, if a model predicts an event with 70% probability 100 times, ECE quantifies the deviation from the event actually occurring approximately 70 times. Both metrics are crucial for determining the reliability and calibration of probabilistic forecasts, allowing for comparison of different forecasting methods and identification of systematic biases.
Enriching Predictions with Large Language Models
Large Language Models (LLMs) possess the computational capacity to process and interpret unstructured textual data at scale, exceeding traditional methods of textual analysis. This capability extends to complex sources like earnings call transcripts and news articles, where information is often presented in narrative form with nuanced language. LLMs utilize deep learning architectures, specifically transformer networks, to understand the relationships between words and phrases, allowing them to identify relevant information, assess sentiment, and extract key insights that would be difficult or impossible to obtain through simple keyword searches or rule-based systems. The models achieve this by representing words as vectors in a high-dimensional space, capturing semantic meaning and allowing for comparisons between different textual elements. This enables LLMs to move beyond literal matching and recognize contextual cues, ultimately facilitating a more comprehensive analysis of textual information.
Market-Conditioned Prompting enhances Large Language Model (LLM) forecasting by integrating pre-existing market probabilities into the prompt structure. This technique moves beyond relying solely on textual content; instead, it provides the LLM with a baseline understanding of expected outcomes, allowing it to focus on identifying textual signals that deviate from those expectations. By weighting the LLM’s analysis based on prior probabilities – derived from sources like options pricing or historical data – the model can refine its forecasts, effectively calibrating textual interpretations against established market consensus. This approach reduces the impact of spurious correlations and increases the reliability of forecasts generated from textual analysis.
The implementation of our market-conditioned prompting strategy relied on the capabilities of the GPT-5.1 large language model. GPT-5.1 was selected for its demonstrated ability to process and interpret complex textual data, specifically allowing for the identification of subtle semantic relationships beyond simple keyword matching. This facilitated a more nuanced understanding of textual cues derived from sources like earnings calls and news reports, enabling the model to incorporate prior market probabilities into its analysis and refine subsequent forecasts. The model’s architecture allowed for the effective weighting of these contextual factors during the prompting process, improving the accuracy and relevance of the generated insights.
Traditional methods of textual analysis, such as those focused on simple keyword detection – exemplified by tracking “Mention Markets” – identify only the presence of specific terms without understanding their contextual relevance. This approach frequently results in false positives and a failure to capture nuanced sentiment or predictive signals. In contrast, the implemented method leverages large language models to analyze semantic relationships between words and phrases, identifying not just what is mentioned, but how it is discussed. This allows for the detection of implied meaning, contextual dependencies, and subtle shifts in language that would be missed by keyword-based systems, ultimately providing a more accurate and robust assessment of textual data.
Synergistic Forecasting: A Hybrid Approach
A novel forecasting approach, termed a Mixture Forecast, strategically integrates two distinct sources of information: market probability and the posterior probabilities generated through Market-Conditioned Prompting. This method doesn’t simply average these values; rather, it intelligently combines them, capitalizing on the collective wisdom reflected in market data while also leveraging the nuanced understanding and reasoning capabilities of a large language model. By weighting each component – the broad signal from the market and the refined insights from the LLM – the Mixture Forecast aims to produce a more reliable and accurate predictive signal than either approach could achieve in isolation. This synergistic combination offers a robust solution, particularly valuable in scenarios where market confidence is moderate and requires a more discerning analysis.
The predictive power of this approach stems from a synergistic combination of distinct informational sources. Market probability, representing the aggregated beliefs of numerous actors, provides a valuable baseline reflecting collective wisdom and readily available information. However, this broad consensus often lacks the granularity to capture subtle nuances or anticipate shifts in sentiment. Large Language Models, conversely, excel at processing complex data and identifying intricate patterns, offering a more nuanced understanding of underlying factors. By intelligently integrating these complementary strengths, the method moves beyond simple aggregation, capitalizing on the robustness of market data while leveraging the analytical capabilities of the LLM to refine and enhance predictive accuracy.
The predictive power of combining market data with large language model analysis hinges on effectively integrating these distinct sources of information. Rather than simply averaging probabilities, the proposed method strategically weights the contributions of each component – the collective intelligence reflected in market forecasts and the nuanced, context-aware reasoning of the language model. This careful calibration allows the system to prioritize the more reliable signal in any given situation, bolstering forecast robustness and accuracy. The result is a predictive signal less susceptible to the limitations of either approach in isolation, consistently outperforming both market-only baselines and standalone language model predictions, as demonstrated by improvements in metrics like Brier Score and overall accuracy.
The proposed MixMCP method demonstrably improves forecasting performance through a carefully weighted combination of market probabilities and large language model insights. Quantitative analysis reveals a Brier Score of 0.1392, representing a significant reduction in forecast error compared to both the market baseline of 0.1441 and the standalone Market-Conditioned Prompting (MCP) score of 0.1470. This translates to an overall Accuracy of 80.3%, consistently exceeding the performance of both baseline methods. Notably, MixMCP exhibits particular strength in scenarios where market confidence is moderate-specifically, within the 50-60% probability range-outperforming the market in 17 out of 30 evaluated cases. Furthermore, the method achieves an Expected Calibration Error (ECE) of 0.051 for MCP, indicating a refined level of confidence in its probability estimates and suggesting a more reliable predictive signal.
The study reveals a compelling interplay between collective intelligence, as embodied by prediction markets, and the reasoning capabilities of large language models. It posits that LLMs aren’t merely echoing existing beliefs, but actively integrating textual evidence to refine probabilistic forecasts. This resonates with Simone de Beauvoir’s assertion: “One is not born, but rather becomes a woman.” Similarly, a forecast isn’t preordained; it becomes more accurate through the continuous process of information assimilation and contextual refinement. The ‘market-conditioned prompting’ technique effectively allows the LLM to ‘become’ a more informed forecaster, moving beyond initial probabilities to a nuanced understanding grounded in textual data-a fascinating demonstration of emergent intelligence.
Looking Ahead
The apparent success of aligning large language models with the wisdom of crowds, as embodied by prediction markets, presents a peculiar opportunity. It is tempting to envision a future of seamless forecasting, where textual nuance and collective probability converge. However, a careful examination of the boundaries reveals limitations. The current approach relies heavily on the quality of the textual evidence provided; a poorly curated dataset, or one reflecting inherent biases, will predictably yield skewed forecasts. Researchers should prioritize methods for robustly assessing and mitigating such data-driven distortions.
Furthermore, the ‘market-conditioned prompting’ technique, while promising, invites scrutiny. How generalizable is this method across diverse forecasting domains? And does the act of prompting – framing the question for the language model – inadvertently introduce another layer of bias, subtly nudging the forecast in a particular direction? The potential for manipulation, even unintentional, demands careful consideration. Thorough calibration studies, extending beyond simple accuracy metrics, are essential.
Ultimately, the most intriguing path forward lies not simply in improving predictive accuracy, but in understanding why this combination of textual analysis and collective intelligence works. Is the language model truly extracting meaningful signals from the text, or is it merely learning to mimic the patterns of market behavior? Disentangling these effects will require a shift in focus, from prediction to explanation – a move toward a more nuanced, and perhaps more honest, understanding of how knowledge emerges from complex systems.
Original article: https://arxiv.org/pdf/2602.21229.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- United Airlines can now kick passengers off flights and ban them for not using headphones
- Crimson Desert: Disconnected Truth Puzzle Guide
- All 9 Coalition Heroes In Invincible Season 4 & Their Powers
- The Boys Season 5 Spoilers: Every Major Character Death If the Show Follows the Comics
- Invincible Season 4 Episode 6 Release Date, Time, Where to Watch
- Mewgenics vinyl limited editions now available to pre-order
- Assassin’s Creed Shadows will get upgraded PSSR support on PS5 Pro with Title Update 1.1.9 launching April 7
- Grok’s ‘Ask’ feature no longer free as X moves it behind paywall
- Crimson Desert Guide – How to Pay Fines, Bounties & Debt
- Grey’s Anatomy Season 23 Confirmed for 2026-2027 Broadcast Season
2026-02-27 01:08